

We cannot hold our excitement anymore! For the last few months, our Data-in-Motion engineering teams have been working hard to deliver a compelling and critical part of our Cloudera DataFlow (CDF) story. To enhance our Stream Processing and Analytics narrative within the overall Data-in-Motion platform, we give you support for Apache Flink with the general availability of Cloudera Streaming Analytics (CSA).
Cloudera Streaming Analytics, powered by Apache Flink, is a new product offering within the Cloudera DataFlow (CDF) platform that provides real-time stateful processing of IoT-scale data streams and complex events for predictive insights. Cloudera DataFlow (as seen in the picture below) is a comprehensive edge-to-cloud real-time streaming data platform. As one of the key pillars of CDF, stream processing & analytics is important for processing millions of data points and complex events coming from various streaming sources. Over the years, we have supported several streaming engines but the addition of Flink now makes CDF an extremely compelling platform for processing high-volumes of streaming data at high-scale.
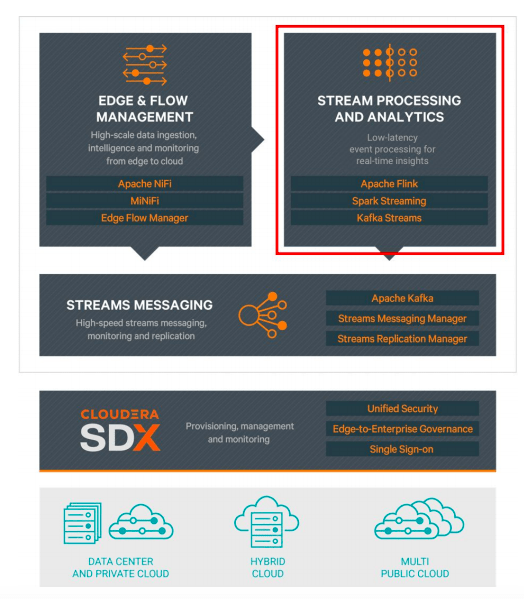
Cloudera Streaming Analytics covers the core streaming functionality of Apache Flink.
It introduces the following key features:
- Support for Flink 1.9.1 on YARN
- Support for installing Flink on Cloudera managed clusters
- Support for fully secure (TLS and Kerberos enabled) Flink cluster
- Data sources reading from Kafka or HDFS
- Pipeline definitions using Java DataStream and ProcessFunction APIs
- Exactly-once processing
- Event-time semantics
- Data sinks writing to Kafka, HDFS and HBase
- Integration with Cloudera Schema Registry for schema management and serialization / deserialization of streaming events
These features enable sophisticated end-to-end streaming pipelines. We have more exciting features planned for upcoming releases of CSA.
Wait, there’s more!
CSA will be made available on the recently released Cloudera Data Platform (CDP) Data Center. Take advantage of CDP’s flexibility and management options to scale-out Flink to any degree with ease. Given the platform integration, Cloudera Manager can be used for installing, monitoring and managing Flink clusters. A centralized log search also aggregates Flink application logs for easier management and debugging.
Most importantly, Flink application metrics can be published into Apache Kafka using the metrics reporter. Given the tightly integrated way, the CDF platform has evolved, Streams Messaging Manager can instantly pick up the metrics published by Flink into Kafka and showcase them with visual depth for analysis.
Why Flink?
Apache Flink is a distributed processing engine and a scalable data analytics framework that can process millions of data points or complex events very easily and deliver predictive insights in real-time. Flink also provides communication, fault tolerance, and data distribution for large scale computations over data streams. Flink can process real-time data as it is generated as well as stored data in storage filesystems.
Over the last few years, Apache Flink’s adoption has grown significantly across the world over a wide range of use cases –
- Telco network monitoring – handling customer complaints with a pre-calculated response about outage and an ETA for a fix, based on streaming data from the network using sophisticated windowing logic
- Content recommendation engine – Video streaming services that need to provide recommendations and search results to the user by the time they can load a web page requires sophisticated logic while actively processing billions of events per day
- Search optimization – Search engines optimizing search rankings in real-time
- Clickstream analysis – High traffic e-commerce websites collecting and serving optimal customer experience based on real-time clickstream data
- Application monitoring – Large enterprises evaluating thousands of customizable alert rules on metrics and log streams and detecting anomalies
- Fraud detection – Financial organizations detecting fraud patterns from millions of real-time financial data streaming from various sources
- Gaming analytics – Understanding the state of millions of daily users on a gaming platform and providing analytics to the business team requires handling high volume data at extremely high scale
While Cloudera offers our customers several options for stream processing engines – Storm, Spark Structured Streaming and Kafka Streams, the addition of Flink to CDF is very significant. Storm has been slowly losing favor in the market and in the open-source community and users are looking for a better option to move into. Apache Flink is that option. Kafka Streams and Spark Structured Streaming address their own relevant set of use cases around stream processing & analytics. However, Apache Flink has a streaming-first (over batch) approach to processing high-volume streams of data at high-scale, while supporting key features such as stateful streaming, exactly-once delivery, built-in fault tolerance/resilience, and advanced windowing techniques. This makes it the default choice for a wider range of stream processing use cases.
Cloudera has committed itself to the larger Flink community about contributing and innovating on Apache Flink through the CSA offering. Cloudera delivered this message at the Flink Forward event in Berlin, October 2019 when our Engineering Leader, Marton Balassi and Field CTO, Andrew Psaltis highlighted our approach in their keynote.
Cloudera Streaming Analytics unlocks net new business value for businesses requiring real-time insights from fast-paced customer experiences. Apache Flink provides stateful analytics at low latency and high scale to address such needs of today’s businesses.
Reach out to us if you are interested in getting hands-on experience of Cloudera Streaming Analytics!
Editor's Choice


Hi,
We are looking to replace Sybase CEP with Apace Flink in one of our modules,I would like to know what is the support model offered with Cloudera for Flink and what is cost involved.
Thanks,
Narendra.