

Introduction
With an ever-increasing number of IoT use cases on the CDH platform, security for such workloads is of paramount importance. This blog post describes how one can consume data from Kafka in Spark, two critical components for IoT use cases, in a secure manner.
The Cloudera Distribution of Apache Kafka 2.0.0 (based on Apache Kafka 0.9.0) introduced a new Kafka consumer API that allowed consumers to read data from a secure Kafka cluster. This allows administrators to lock down their Kafka clusters and requires clients to authenticate via Kerberos. It also allows clients to encrypt data over the wire when communicating with Kafka brokers (via SSL/TLS). Subsequently, in the Cloudera Distribution of Apache Kafka 2.1.0, Kafka introduced support for authorization via Apache Sentry. This allows Kafka administrators to lock down certain topics and grant privileges to specific roles and users, leveraging role-based access control.
And, now, starting Cloudera Distribution of Spark 2.1 release 1, we have the functionality to read securely from Kafka in Spark. To read more about Cloudera Distribution of Spark 2, please refer to documentation.
Requirements
- Cloudera Distribution of Spark 2.1 release 1 or higher
- Cloudera Distribution of Kafka 2.1.0 or higher
Architecture
Consuming from secure Kafka clusters is supported using a new direct connector in Spark (source available here). A direct connector doesn’t use a separate process (a.k.a receiver) to read data. Instead, the Spark driver tracks offsets of various Kafka topic partitions, and sends offsets to executors which read data directly from Kafka. A simplistic depiction of a direct connector is shown below.
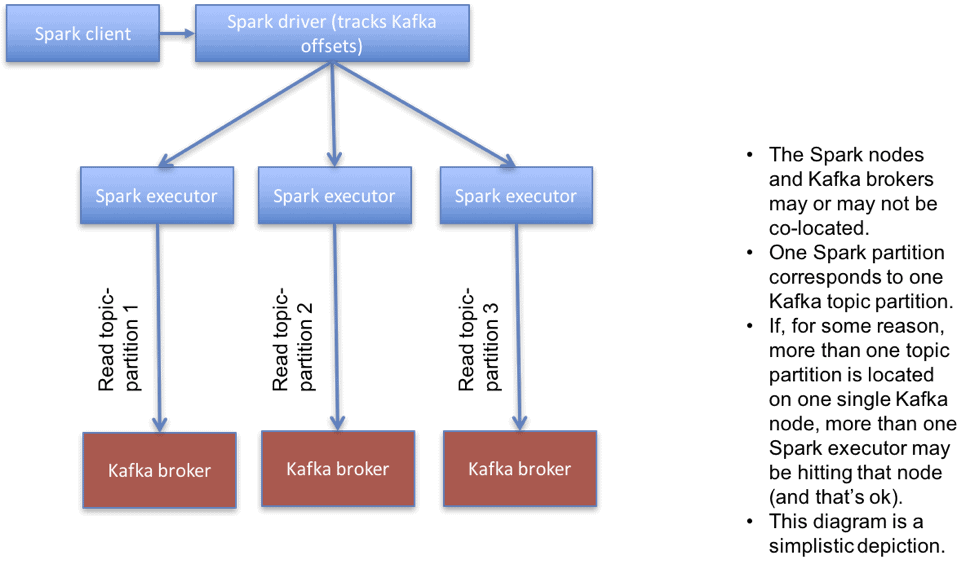
The important point to note is that Spark accesses data from Kafka in a distributed manner. Each task in Spark reads data from a particular partition of a Kafka topic, known as a topic-partition. Topic-partitions are ideally uniformly distributed across Kafka brokers. You can read about how Spark places executors here.
However, to read data from secure Kafka in distributed fashion, we need Hadoop-style delegation tokens in Kafka (KAFKA-1696), support for which doesn’t exist at the time of this writing (Spring 2017).
We considered various ways to solve this problem but ultimately decided that the recommended solution to read data securely from Kafka (at least until Kafka delegation tokens support is introduced) would be for the Spark application to distribute the user’s keytab so it’s accessible to the executors. The executors will then use the user’s keytab shared with them, to authenticate with the Kerberos Key Distribution Center (KDC) and read from Kafka brokers. YARN distributed cache is used for shipping and sharing the keytab to the driver and executors, from the client (that is, the gateway node). The figure below shows an overview of the current solution.
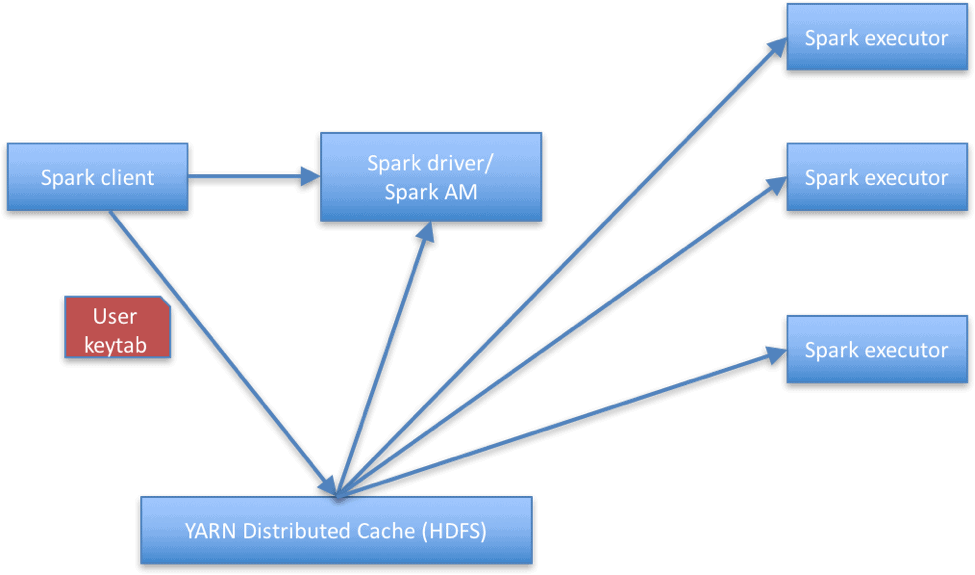
There are a few commonly raised concerns with this approach:
- It’s not considered the best security practice to ship keytabs around.
- In case of a large number of Kafka topic partitions, all executors may try logging in to the KDC at the same time, potentially leading to what’s called a replay attack (similar to DDOS attack).
Regarding a), Spark already uses the distributed cache to ship the user’s keytab from the client (a.k.a gateway) node to the driver, and given the lack of delegation tokens there was no way around it. Administrators can choose to distribute the keytab to various Spark executor nodes (i.e. YARN nodes, since Spark runs on YARN) themselves, outside of Spark, and tweak the shared sample app (see Sample app section) to alleviate that concern.
Regarding b), we tested over 1000 topic partitions in a Kafka topic and saw no adverse effect on the KDC server by increasing the number of partitions.
Sample app
A sample Spark Streaming app that reads data from Kafka secured by Kerberos, with SSL is available here.
Integration with Apache Sentry
The sample app assumes no Kafka authorization is being used. If using Kafka authorization (via Apache Sentry), you’d have to ensure that the consumer groups specified in your application are authorized in Sentry. If, for example, the name of your application consumer group was my-consumer-group, you’d have to give access to both my-consumer-group and spark-executor-my-consumer-group (i.e. name of your consumer group prefixed by spark-executor-). This is because the spark driver uses the consumer group specified by the app, but the spark executors use a different consumer group in this integration, which prefixes spark-executor- before the name of the driver consumer group.
You can find more information about Kafka Sentry integration in the docs.
Conclusion
To recap, you can use Cloudera Distribution of Apache Kafka 2.1.0 (or higher) and Cloudera Distribution of Apache Spark 2.1 release 1 (or higher) to consume data in Spark from Kafka in a secure manner – including authentication (using Kerberos), authorization (using Sentry) and encryption over the wire (using SSL/TLS).
The code for the sample app on github is available at https://github.com/markgrover/spark-secure-kafka-app
Editor's Choice

