

Businesses everywhere have engaged in modernization projects with the goal of making their data and application infrastructure more nimble and dynamic. By breaking down monolithic apps into microservices architectures, for example, or making modularized data products, organizations do their best to enable more rapid iterative cycles of design, build, test, and deployment of innovative solutions. The advantage gained from increasing the speed at which an organization can move through these cycles is compounded when it comes to data apps – data apps both execute business processes more efficiently and facilitate organizational learning/improvement.
SQL Stream Builder streamlines this process by managing your data sources, virtual tables, connectors, and other resources your jobs might need, and allowing non technical domain experts to to quickly run versions of their queries.
In the 1.9 release of Cloudera’s SQL Stream Builder (available on CDP Public Cloud 7.2.16 and in the Community Edition), we have redesigned the workflow from the ground up, organizing all resources into Projects. The release includes a new synchronization feature, allowing you to track your project’s versions by importing and exporting them to a Git repository. The newly introduced Environments feature allows you to export only the generic, reusable parts of code and resources, while managing environment-specific configuration separately. Cloudera is therefore uniquely able to decouple the development of business/event logic from other aspects of application development, to further empower domain experts and accelerate development of real time data apps.
In this blog post, we will take a look at how these new concepts and features can help you develop complex Flink SQL projects, manage jobs’ lifecycles, and promote them between different environments in a more robust, traceable and automated manner.
What is a Project in SSB?
Projects provide a way to group resources required for the task that you are trying to solve, and collaborate with others.
In case of SSB projects, you might want to define Data Sources (such as Kafka providers or Catalogs), Virtual tables, User Defined Functions (UDFs), and write various Flink SQL jobs that use these resources. The jobs might have Materialized Views defined with some query endpoints and API keys. All of these resources together make up the project.
An example of a project might be a fraud detection system implemented in Flink/SSB. The project’s resources can be viewed and managed in a tree-based Explorer on the left side when the project is open.
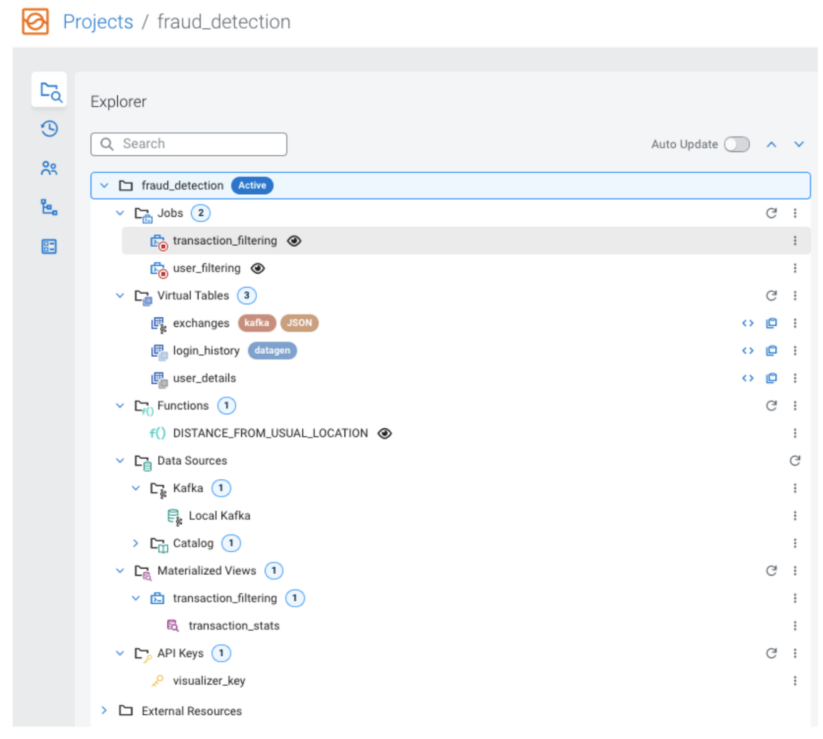
You can invite other SSB users to collaborate on a project, in which case they will also be able to open it to manage its resources and jobs.
Some other users might be working on a different, unrelated project. Their resources will not collide with the ones in your project, as they are either only visible when the project is active, or are namespaced with the project name. Users might be members of multiple projects at the same time, have access to their resources, and switch between them to select
the active one they want to be working on.
Resources that the user has access to can be found under “External Resources”. These are tables from other projects, or tables that are accessed through a Catalog. These resources are not considered part of the project, they may be affected by actions outside of the project. For production jobs, it is recommended to stick to resources that are within the scope of the project.
Tracking changes in a project
As any software project, SSB projects are constantly evolving as users create or modify resources, run queries and create jobs. Projects can be synchronized to a Git repository.
You can either import a project from a repository (“cloning it” into the SSB instance), or configure a sync source for an existing project. In both cases, you need to configure the clone URL and the branch where project files are stored. The repository contains the project contents (as json files) in directories named after the project.
The repository may be hosted anywhere in your organization, as long as SSB can connect to it. SSB supports secure synchronization via HTTPS or SSH authentication.
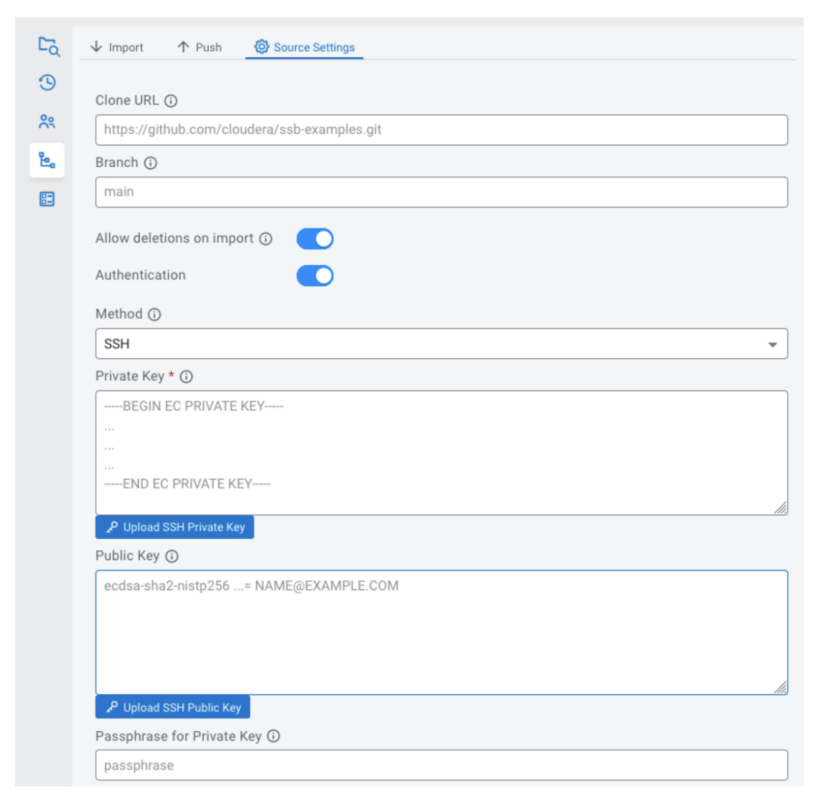
If you have configured a sync source for a project, you can import it. Depending on the “Allow deletions on import” setting, this will either only import newly created resources and update existing ones; or perform a “hard reset”, making the local state match the contents of the repository entirely.
After making some changes to a project in SSB, the current state (the resources in the project) are considered the “working tree”, a local version that lives in the database of the SSB instance. Once you have reached a state that you would like to persist for the future to see, you can create a commit in the “Push” tab. After specifying a commit message, the current state will be pushed to the configured sync source as a commit.
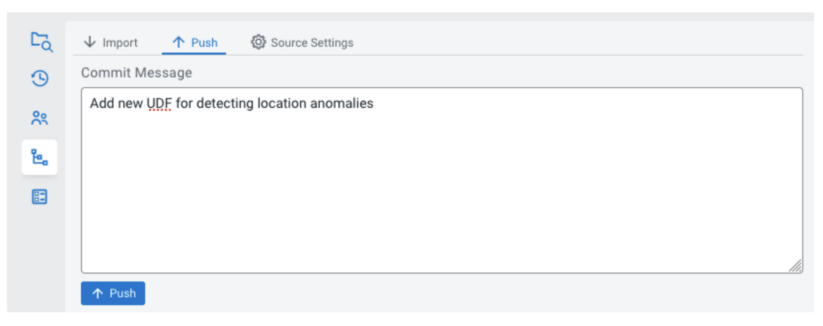
Environments and templating
Projects contain your business logic, but it might need some customization depending on where or on which conditions you want to run it. Many applications make use of properties files to provide configuration at runtime. Environments were inspired by this concept.
Environments (environment files) are project-specific sets of configuration: key-value pairs that can be used for substitutions into templates. They are project-specific in that they belong to a project, and you define variables that are used within the project; but independent because they are not included in the synchronization with Git, they are not part of the repository. This is because a project (the business logic) might require different environment configurations depending on which cluster it is imported to.
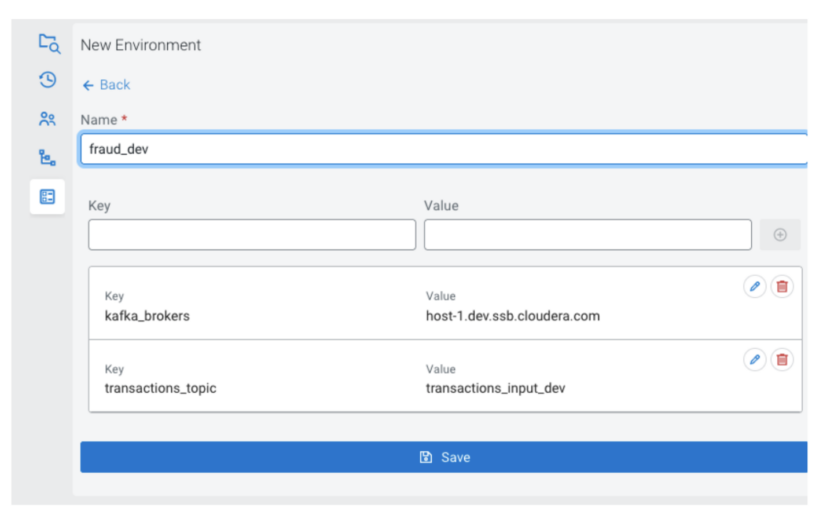
You can manage multiple environments for projects on a cluster, and they can be imported and exported as json files. There is always zero or one active environment for a project, and it is common among the users working on the project. That means that the variables defined in the environment will be available, no matter which user executes a job.
For example, one of the tables in your project might be backed by a Kafka topic. In the dev and prod environments, the Kafka brokers or the topic name might be different. So you can use a placeholder in the table definition, referring to a variable in the environment (prefixed with ssb.env.):
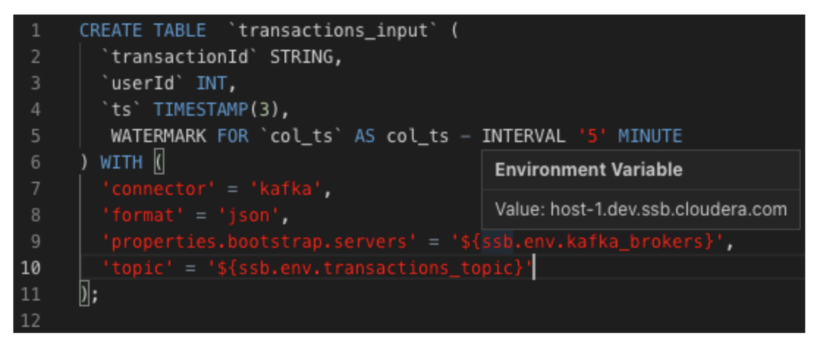
This way, you can use the same project on both clusters, but upload (or define) different environments for the two, providing different values for the placeholders.
Placeholders can be used in the values fields of:
- Properties of table DDLs
- Properties of Kafka tables created with the wizard
- Kafka Data Source properties (e.g. brokers, trust store)
- Catalog properties (e.g. schema registry url, kudu masters, custom properties)
SDLC and headless deployments
SQL Stream Builder exposes APIs to synchronize projects and manage environment configurations. These can be used to create automated workflows of promoting projects to a production environment.
In a typical setup, new features or upgrades to existing jobs are developed and tested on a dev cluster. Your team would use the SSB UI to iterate on a project until they are satisfied with the changes. They can then commit and push the changes into the configured Git repository.
Some automated workflows might be triggered, which use the Project Sync API to deploy these changes to a staging cluster, where further tests can be performed. The Jobs API or the SSB UI can be used to take savepoints and restart existing running jobs.
Once it has been verified that the jobs upgrade without issues, and work as intended, the same APIs can be used to perform the same deployment and upgrade to the production cluster. A simplified setup containing a dev and prod cluster can be seen in the following diagram:
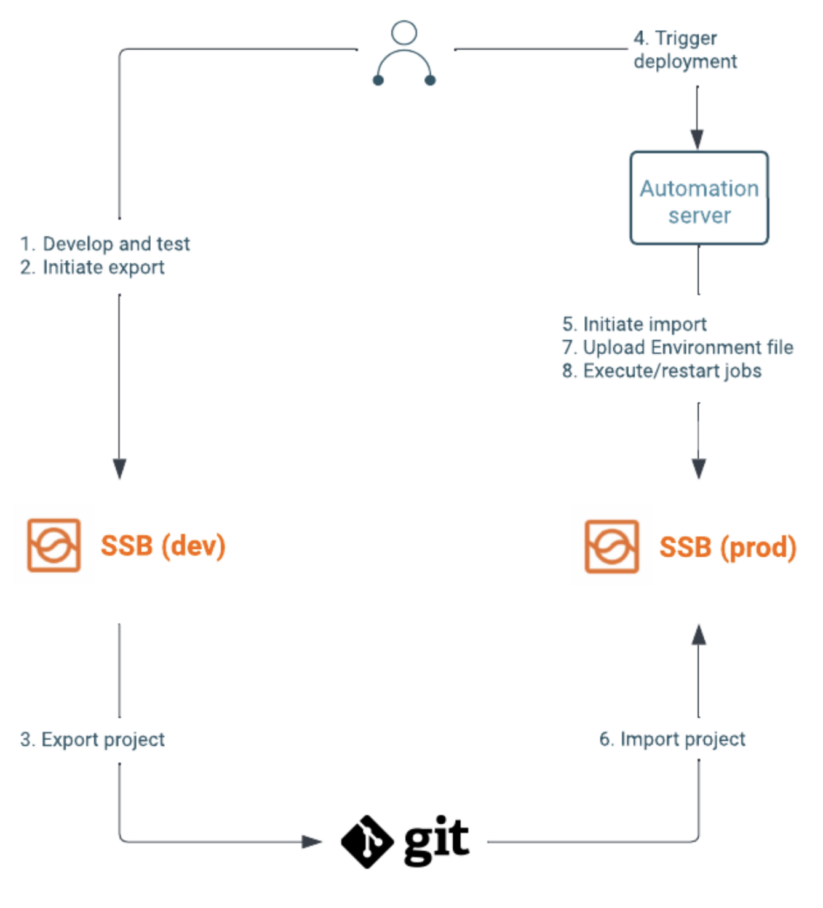
If there are configurations (e.g. kafka broker urls, passwords) that differ between the clusters, you can use placeholders in the project and upload environment files to the different clusters. With the Environment API this step can also be part of the automated workflow.
Conclusion
The new Project-related features take developing Flink SQL projects to the next level, providing a better organization and a cleaner view of your resources. The new git synchronization capabilities allow you to store and version projects in a robust and standard way. Supported by Environments and new APIs, they allow you to build automated workflows to promote projects between your environments.
Try it out yourself!
Anybody can try out SSB using the Stream Processing Community Edition (CSP-CE). CE makes developing stream processors easy, as it can be done right from your desktop or any other development node. Analysts, data scientists, and developers can now evaluate new features, develop SQL-based stream processors locally using SQL Stream Builder powered by Flink, and develop Kafka Consumers/Producers and Kafka Connect Connectors, all locally before moving to production in CDP.
Editor's Choice

