

Data Science tools, algorithms, and practices are rapidly evolving to solve business problems on an unprecedented scale. This makes data science one of the most exciting fields to be in. As exciting as it is, practitioners face their fair share of challenges. There are well-known barriers that slow down predictive modeling or application development. Finding the right data and getting access to it are two of the top pain points we hear from our customers.
The first step in any machine learning project is finding and getting access to the data store. Data scientists need to get the endpoint, find out the correct configuration for the connection, and then authenticate. They can get these from their administrators, ask their colleagues, or copy them from an existing project. Once they know the details, they need to figure out and install the drivers and libraries to initiate the connection.
Doing all these takes time and resources away from the exciting work: building AI Applications.
Cloudera Machine Learning (CML) unblocks Data Scientists and lets them focus on solving their business problems. CML offers easy data access via preconfigured Data Connections in Cloudera Data Platform (CDP) environments. Data Scientists can copy a code snippet for their selected Connection and use it directly in their code. With the new cml Python library, CML users don’t need to worry about setting the connection endpoints, right configurations, or authentication. The library abstracts the complexity of creating a connection and fetching data.
Let’s see this in action
The first step is to create a new Project in CML.
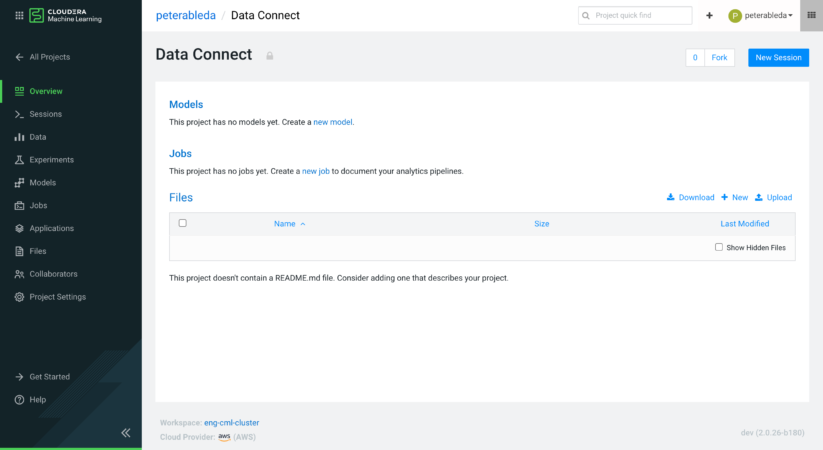
On the Project Settings > Data Connections tab, Data Scientists can review the connections Administrators configured for the CML Workspace. Most connections are auto-discovered in the CDP Environment. It’s as easy as clicking a button.
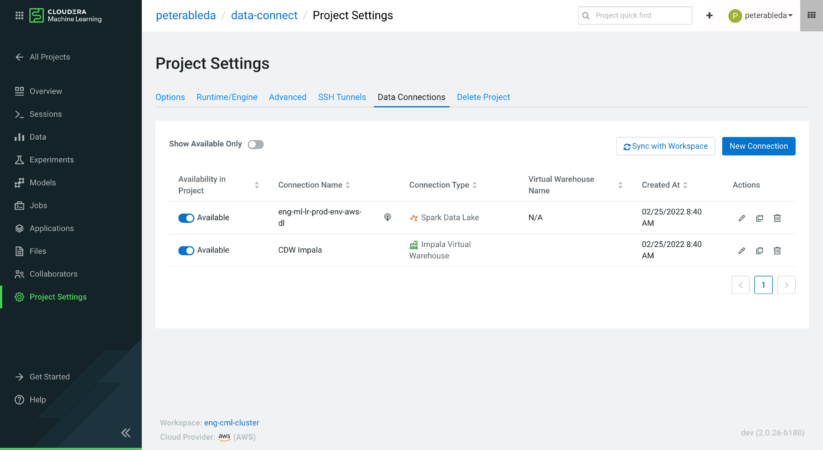
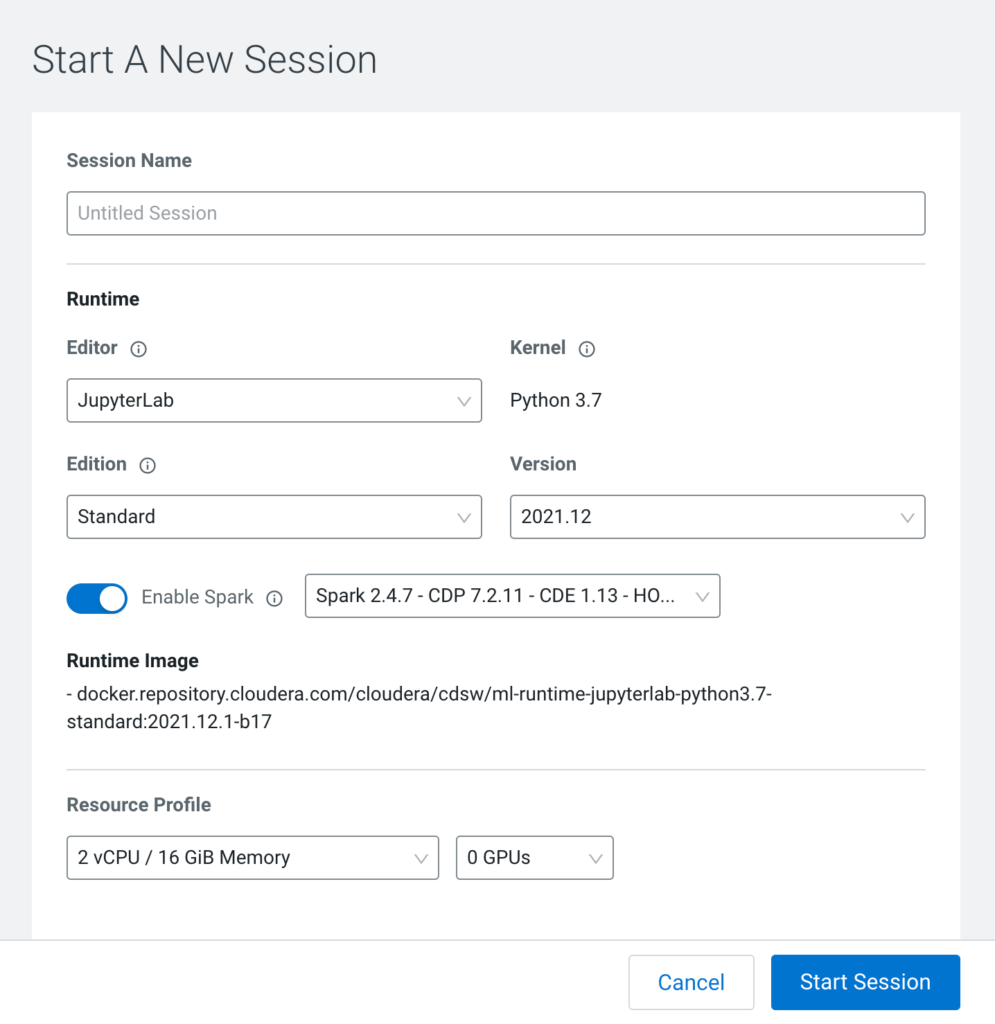
Data Scientists can start working by starting a new Session with their favorite Editor.
Once the Session starts, CML shows the Data Connections from the Project and offers snippets to create a connection and to fetch data.
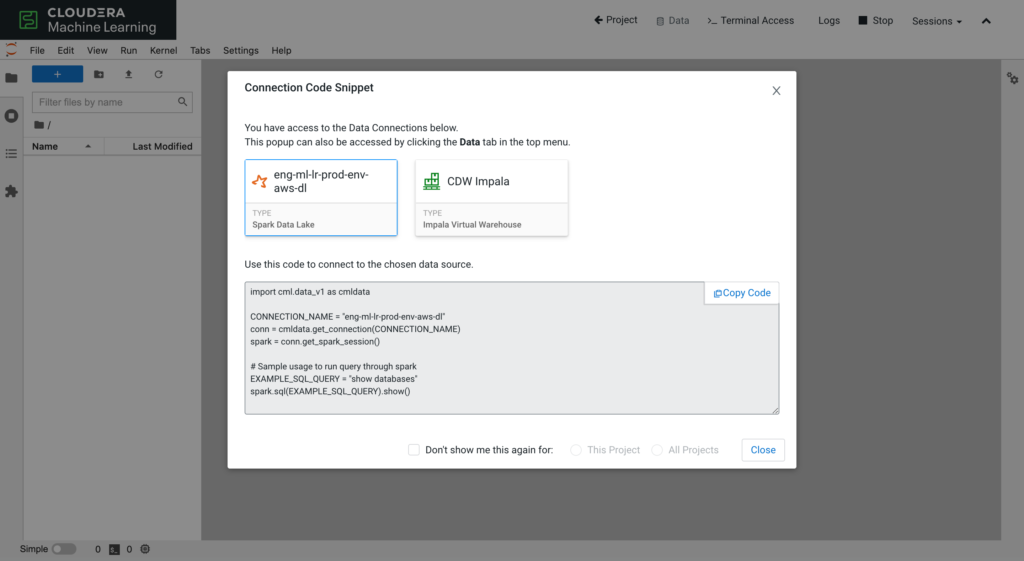
The new cml.data library takes away the complexity of initiating a connection and gives abstractions on fetching a dataset.
After importing the cml package, Data Scientists can connect by referencing the Connection name.
import cml.data_v1 as cmldata conn = cmldata.get_connection("CDW Impala")
The Impala connection object has different methods to interact with the CDW Impala Virtual Warehouse. Users can directly fetch data and return it as a pandas dataframe:
SQL_QUERY = "show databases" dataframe = conn.get_pandas_dataframe(SQL_QUERY)
In case users want to use the standard DB API Cursor interface, they can get that from the CML connection object:
db_cursor = conn.get_cursor() db_cursor.execute(SQL_QUERY) for row in db_cursor: print(row)
As an alternative, to gain full control over the connection, users can also get the DB API Connection interface:
db_conn = conn.get_base_connection()
In the below example we use an Impala connection to connect to a CDW Impala Virtual Warehouse and execute an example select query to fetch data.
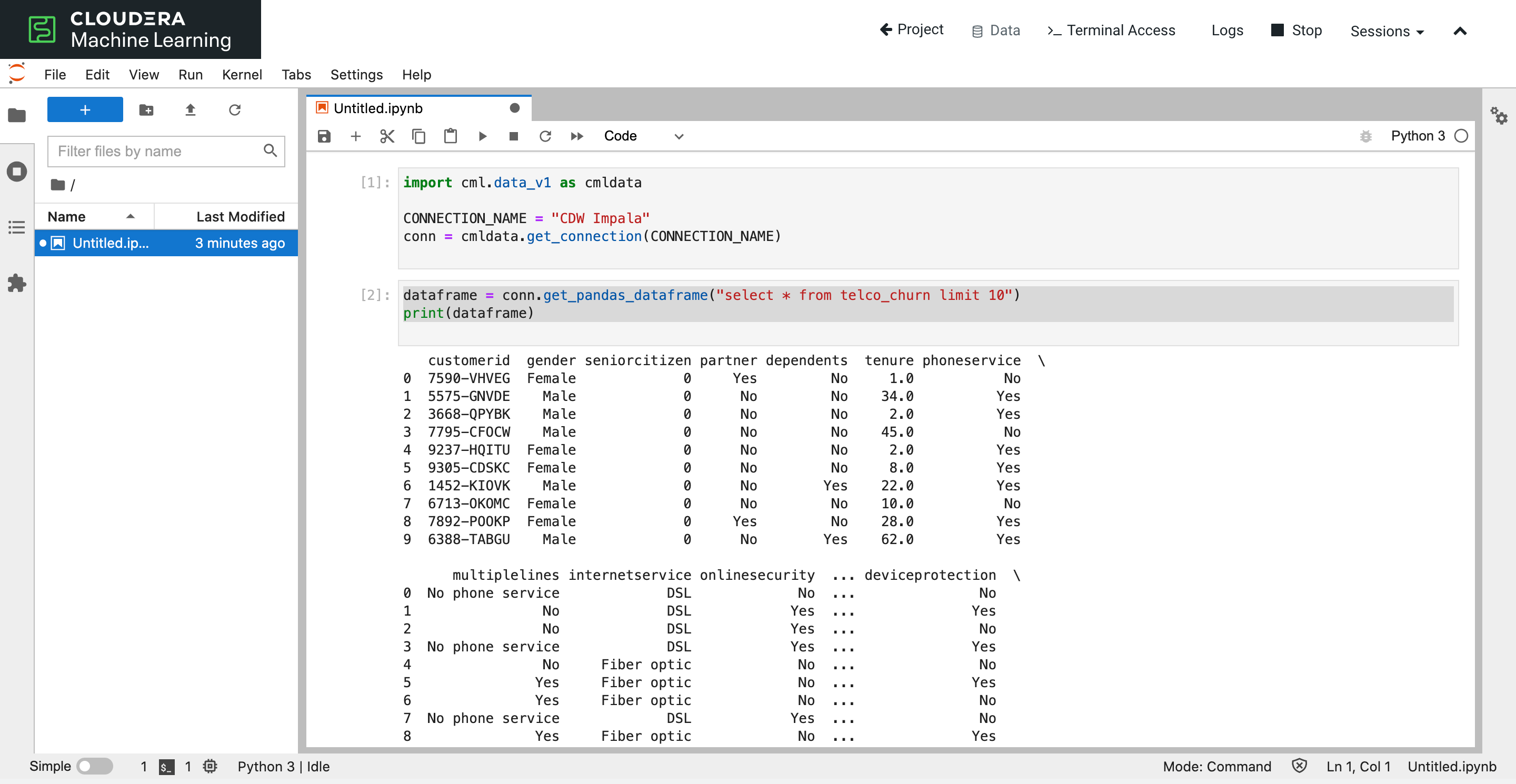
With CML’s new Data Connection & Snippet data scientists can focus on the exciting part of their work, building AI Applications. They don’t have to worry about data access anymore.
Next Steps
If you are not a Cloudera customer already and want to learn more about everything that CML has to offer, we’ll give you the keys and let you take it out for a test drive.
If you are already a Cloudera customer, what are you waiting for? Go try out this feature today!
Editor's Choice

