

While it is a little dated, one amusing example that has been the source of countless internet memes is the famous, “is this a chihuahua or a muffin?” classification problem.

Figure 01: Is this a chihuahua or a muffin?
In this example, the Machine Learning (ML) model struggles to differentiate between a chihuahua and a muffin. The eyes and nose of a chihuahua, combined with the shape of its head and colour of its fur do look surprising like a muffin if we squint at the images in figure 01 above.
What if the spacing between blueberries in a muffin is reduced? What if a muffin is well-baked? What if it is an irregular shape? Will the model correctly determine it is a muffin or get confused and think it is a chihuahua? The extent to which we can predict how the model will classify an image given a change input (e.g. blueberry spacing) is a measure of the model’s interpretability. Model interpretability is one of five main components of model governance. The complete list is shown below:
- Model Lineage
- Model Visibility
- Model Explainability
- Model Interpretability
- Model Reproducibility
In this article, we explore model governance, a function of ML Operations (MLOps). We will learn what it is, why it is important and how Cloudera Machine Learning (CML) is helping organisations tackle this challenge as part of the broader objective of achieving Ethical AI.
Machine Learning Model Lineage
Before we can understand how model lineage is managed and subsequently audited, we first need to understand some high-level constructs within CML. The highest level construct in CML is a workspace. Each workspace is associated with a collection of cloud resources. In the case of CDP Public Cloud, this includes virtual networking constructs and the data lake as provided by a combination of a Cloudera Shared Data Experience (SDX) and the underlying cloud storage. Each workspace typically contains one or more projects. Each project consists of a declarative series of steps or operations that define the data science workflow. Each user associated with a project performs work via a session. So, we have workspaces, projects and sessions in that order.
We can think of model lineage as the specific combination of data and transformations on that data that create a model. This maps to the data collection, data engineering, model tuning and model training stages of the data science lifecycle. These stages need to be tracked over time and be auditable.
Weak model lineage can result in reduced model performance, a lack of confidence in model predictions and potentially violation of company, industry or legal regulations on how data is used.
Within the CML data service, model lineage is managed and tracked at a project level by the SDX. SDX provides open metadata management and governance across each deployed environment by allowing organisations to catalogue, classify as well as control access to and manage all data assets. This allows data scientists, engineers and data management teams to have the right level of access to effectively perform their role. As shown in figure 02 below, SDX, via the Apache Atlas subcomponent, provides model lineage starting from the data sources, the subsequent data engineering tasks, the data warehouse tables, the model training activities, the model build process and subsequent deployment and serving of the model behind an API. If any of these stages in the lineage changes, it will be captured and can be audited by SDX.
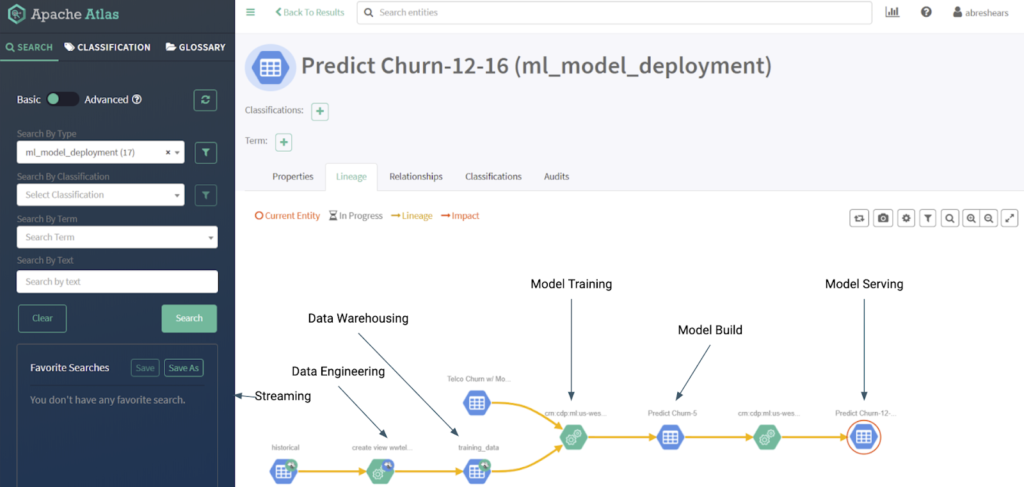
Figure 02: ML Model Lineage with SDX
CML also provides means to record the relationship between models, queries and training scripts at a project level. This is defined in a file, lineage.yaml as illustrated in figure 03 below. In this simple example, we can see that modelName1 is associated with tables table1 and table2. We can also see the query used to extract the training data and that training is performed by fit.py.

Figure 03: lineage.yaml
Further auditing can be enabled at a session level so administrators can request key metadata about each CML process.
Machine Learning Model Visibility
Model visibility is the extent to which a model is discoverable and its consumption is visible and transparent.
To simplify the creation of new projects, we provide a catalogue of base projects to start in the form of Applied Machine Learning Prototypes (AMPs) shown in figure 04 below.
AMPs are declarative projects in that they allow us to define each end-to-end ML project in code. They define each stage from data ingest, feature engineering, model building, testing, deployment and validation. This supports automation, consistency and reproducibility.
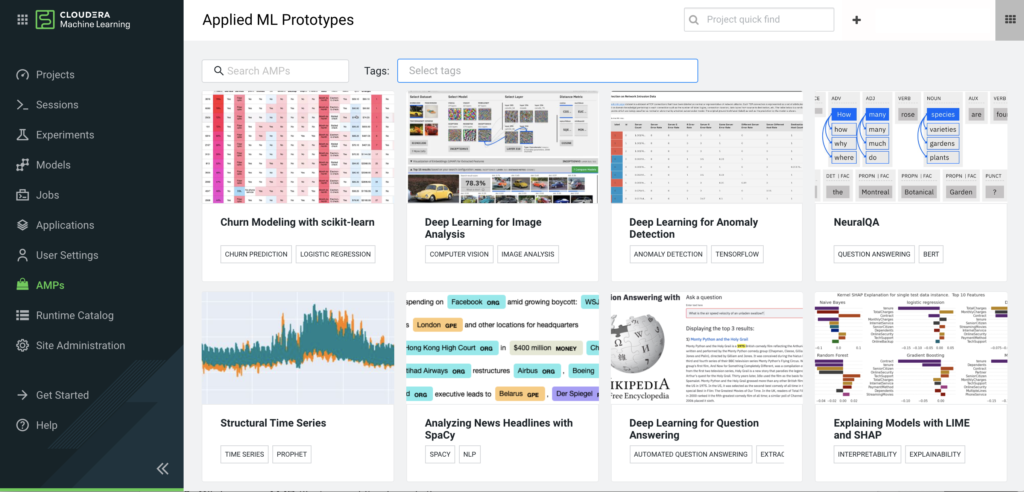
Figure 04: Applied Machine Learning Prototypes (AMPs)
AMPs are available for the most commonly used ML use cases and algorithms. For example, if you need to build a model for customer churn prediction, you can initiate a new churn modelling with scikit-learn project within Cloudera’s management console or via a call to CML’s RESTful API service. It is also possible to create your own AMP and publish it in the AMP catalogue for consumption.
Each time a project is successfully deployed, the trained model is recorded within the Models section of the Projects page. Support for multiple sessions within a project allows data scientists, engineers and operations teams to work independently alongside each other on experimentation, pipeline development, deployment and monitoring activities in parallel. The AMPs framework also supports the promotion of models from the lab into production, a common MLOps task.
It is also possible to run experiments within a project to try different tuning parameters for a given ML algorithm, as would be the case when using a grid search approach. By logging the performance of every combination of search parameters within an experiment, we can choose the optimal set of parameters when building a model. CML now supports experiment tracking using MLflow.
The combination of AMPs together with the ability to record ML models and experiments within CML, makes it convenient for users to search for and deploy models, thus increasing model visibility.
Machine Learning Model Explainability
Model explainability is the extent to which someone can explain the inner workings of a model. This is often limited to data scientists and data engineers as the ML algorithms upon which models are based can be complex and require at least some advanced understanding of mathematical concepts.
The first part of model explainability is to understand which ML algorithm or algorithms, in the case of ensemble models, were used to create the model. Model lineage and model visibility support this.
The second part of model explainability is whether a data scientist understands and can explain how the underlying algorithm works. The development of ML frameworks and toolkits simplifies these tasks for data scientists. However, before an algorithm is used, its suitability should be carefully considered.
The ML researchers in Cloudera’s Fast Forward Labs develop and maintain each published AMP. Each AMP consists of a working prototype for a ML use case together with a research report. Each report provides a detailed introduction to the ML algorithm behind each AMP; this includes its applicability to problem families together with examples for usage.
Machine Learning Model Interpretability
As we have already seen in the “chihuahua or a muffin” example, model interpretability is the extent to which someone can consistently predict a model’s output. The greater our understanding of how a model works, the better we are able to predict what the output will be for a range of inputs or changes to the model’s parameters. Given the complexity of some ML models, especially those based on Deep Learning (DL) Convolutional Neural Networks (CNNs), there are limits to interpretability.
Model interpretability can be improved by choosing algorithms that can be easily represented in human readable form. Probably the best example of this, is the decision tree algorithm or the more commonly used ensemble version, random forest.
Figure 05 below illustrates a simple iris flower classifier using a decision tree. Starting from the root of the inverted tree (top white bow), we simply take the left or right branch depending on the answer to a question about a specimen’s petals and sepals. After a few steps we have traversed the tree and can classify what type of iris a given specimen belongs to.
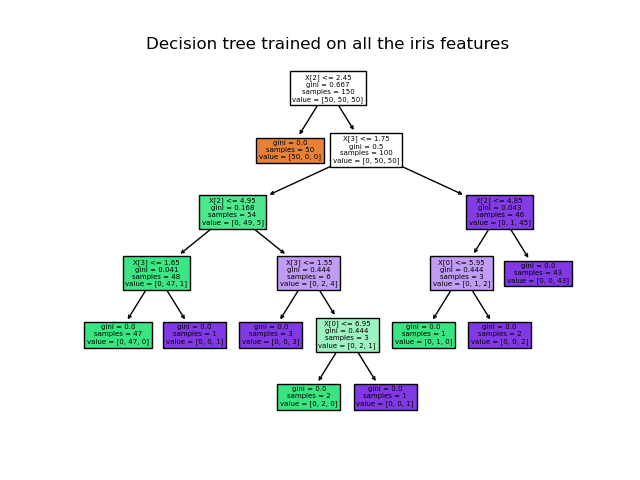
Figure 05: Iris Flower Classification Using a Decision Tree Classifier
While decision trees perform well for some classification and regression problems, they are unsuitable for other problems. For example, CNNs are far more effective at classifying images at the expense of being far less interpretable and explainable.
The other aspect to interpretability is to have sufficient and easy access to prior model predictions. For example, in the case of the “chihuahua or a muffin” model, if we notice high error rates within certain classes, we probably want to explore those data sets more closely and see if we can help the model better separate the two classes. This might require making batch and individual predictions.
CML supports model prediction in either batch mode or via a RESTful API for individual model predictions. Model performance metrics together with input features, predictions and potentially ground truth values, can be tracked over time.
Through a combination of choosing an algorithm that produces more explainable models, together with recording inputs, predictions and performance over time, data scientists and engineers can improve model interpretability using CML.
Machine Learning Model Reproducibility
Model reproducibility is the extent to which a model can be recreated. If a model’s lineage is completely captured, we know exactly what data was used to train, test and validate a model. This requires all randomness in the training process to be seeded for repeatability, and is achievable through careful creation of CML project code and experiments. CML supports using specific versions of ML algorithms, frameworks and libraries used during the entire data science lifecycle.
Summary
In this article, we looked at ML model governance, one of the challenges that organisations need to overcome to ensure that AI is being used ethically.
The Cloudera Machine Learning (CML) data service provides a solid foundation for ML model governance at ML Operations (MLOps) at Enterprise scale. It provides strong support for model lineage, visibility, explainability, interpretability and reproducibility. The extensive collection of Applied Model Prototypes (AMPs) help organisations choose the right ML algorithm for the family of problems they are solving and get them up and running quickly. The comprehensive data governance features of the Shared Data Experience (SDX) provide strong data lineage controls and auditability.
To learn more about CML, head over to https://www.cloudera.com/products/machine-learning.html or connect with us directly.
Editor's Choice

