

At Cloudera Fast Forward we work to make the recently possible useful. Our goal is to take the incredible data science and machine learning research developments we see emerging from academia and large industrial labs, and bridge the gap to products and processes that are useful to practitioners working across industries. In the past year, we’ve released research reports and prototypes exploring Deep Learning for Anomaly Detection, Causality for Machine Learning and NLP for Automated Question Answering.
Evolving Research At Cloudera Fast Forward
Each of these reports went through a lengthy topic selection process, where we investigated and evaluated many emerging machine learning capabilities against criteria including their relevance to businesses, novelty, and how excited we were to work on them. Then, we spent six months diving deep into each, reading the relevant literature, sometimes (multiple!) textbooks, and understanding potential applications and limitations by prototyping.
While we’re proud of the work we’ve done and the businesses we’ve helped, investing six months in each report meant we also had to leave a lot of topics unexplored. There are relevant emerging and established capabilities that we rejected because we weren’t certain enough they would work out.
Our research process has ever been evolving, and we recently embarked on the next iteration of that: more frequent, focused reports. Our hope is that working in shorter research cycles allows us to explore more topics, without compromising on the ability to dive deep in subsequent cycles. We also hope that more concise reports will be more digestible, and as such, more useful to more people. To aid that, we’ll also be releasing a lot more code as we go!
We’re pleased to share the first two of our new-form research releases: Meta-Learning, and Structural Time Series. We’re collecting both into our upcoming webinar, our very first Fast Forward Research Roundup.
Meta-Learning
Humans have an innate ability to learn new skills quickly. For example, we can look at one instance of a knife and be able to discriminate all knives from other cutlery items, like spoons and forks. We can learn new skills and adapt to new environments quickly by leveraging knowledge acquired from prior experience. In a similar fashion, meta-learning leverages previous knowledge acquired from data to solve novel tasks quickly and more efficiently.
Many real-world problems nicely fit this criteria – it encompasses use cases where it might be expensive or simply hard to collect massive amounts of labeled data due to long-tailed and imbalanced data distributions, while still allowing us to use deep learning techniques. Instead of relying on pre-trained models that may be less effective for domain-specific problems, what meta-learning proposes is to use an end-to-end deep learning algorithm. The idea is to learn a model from a large number of similar tasks—for example, classifying images from other image categories—to create a representation better suited for learning new categories quickly and efficiently. In turn, this enables us to classify new classes based on only a handful of examples during model inference that makes meta-learning particularly attractive.
Structural Time Series
Time series are ubiquitous and come in diverse shapes and sizes. Many time series display common characteristics, such as a general upwards or downwards trend, repeating patterns, or sudden spikes or drops. We can address these features explicitly by taking a structural approach that represents an observed time series as a combination of components: a Generalized Additive Model (GAM).
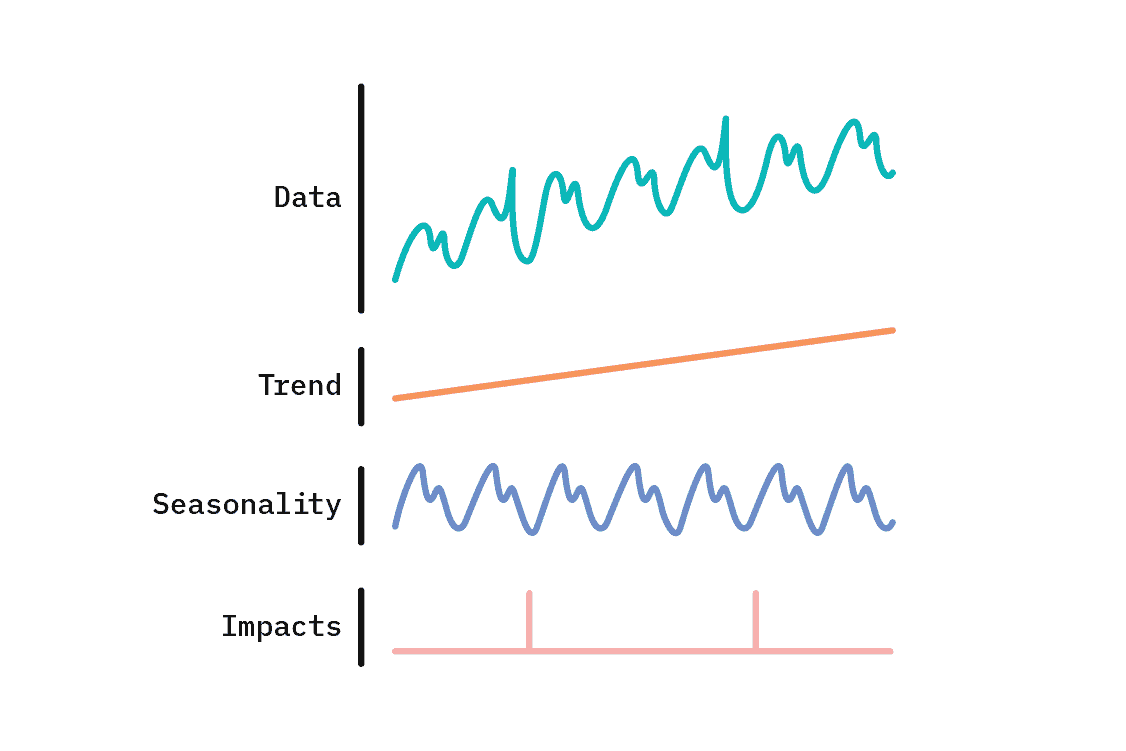
GAMs provide a flexible and broadly applicable basis for time series modeling, with upsides like naturally handling missing and unevenly spaced observations. By no means a new technique, they remain a practical tool for applied machine learning, and the open-source Prophet library provides a mature and robust implementation for their use.
We find these models to be increasingly relevant in domains that are rightly demanding interpretable models. Generalized additive models are intrinsically interpretable themselves, and do not require post-facto explanation by a second model. By additionally capturing uncertainty, GAMs unlock much smarter forecasting possibilities than mere point predictions. While point predictions limit us to asking “what is the demand forecast for Tuesday?” probabilistic forecasts let us ask “what is the probability that demand will exceed our supply on Tuesday?” Such probabilistic questions facilitate a sophisticated treatment of risk, which is perennially relevant.
And beyond
Making good on our commitment to more frequent releases, we’re excited to announce two more research releases in the pipeline for this year. Our work on semantic image search and zero-shot text classification will be coming to your screens in November and December, respectively!
Learn More
Attend our Fast Forward Research Roundup webinar & don’t forget to sign-up for the Fast Forward Research Newsletter!
Editor's Choice

