

It’s no secret that Data Scientists have a difficult job. It feels like a lifetime ago that everyone was talking about data science as the sexiest job of the 21st century. Heck, it was so long ago that people were still meeting in person! Today, the sexy is starting to lose its shine. There’s recognition that it’s nearly impossible to find the unicorn data scientist that was the apple of every CEO’s eye in 2012. You know the one, the mathematician / statistician / computer scientist / data engineer / industry expert. It turns out it’s hard to find all that awesome packed into a single brain.
Some companies are starting to segregate the responsibilities of the unicorn data scientist into multiple roles (data engineer, ML engineer, ML architect, visualization developer, etc.), but on the whole there is still a strong need for the data scientist that can do a little bit of everything. Just take a look at the description for data science job postings on LinkedIn if you don’t believe us.
In recognition of the diverse workload that data scientists face, Cloudera’s library of Applied ML Prototypes (AMPs) provide Data Scientists with pre-built reference examples and end-to-end solutions, using some of the most cutting edge ML methods, for a variety of common data science projects. Every AMP includes all the dependencies, industry best practices, prebuilt models, and a business-ready AI application — All deployable with a couple clicks, allowing Data Science teams to start a new project with a working example that they can then customize to their own needs in a fraction of the time.
We are very excited to announce the release of five, yes FIVE new AMPs, now available in Cloudera Machine Learning (CML).
Thanks to our hard working research team at Fast Forward Labs, these new AMPs cover a wide range of topics, from an in depth demonstration of how to automate CML tasks with the newly released CML API v2, to using TPOT to implement AutoML.
Here’s an overview of what was released:
Getting Started with the CML API
In addition to the UI interface, Cloudera Machine Learning exposes a REST API that can be used to programmatically perform operations related to Projects, Jobs, Models, and Applications. API v2 supersedes the legacy Jobs API, and it allows for integration of CML with third-party workflow tools or control of CML from the command line. This Applied ML Prototype consists of a Jupyter notebook demonstrating the core functionality of the CML API using a Python client.
![]()
AutoML with TPOT

In the hands of an experienced practitioner, AutoML holds much promise for automating away some of the tedious parts of building machine learning systems. TPOT is a library for performing sophisticated search over whole ML pipelines, selecting preprocessing steps and algorithm hyperparameters to optimize for your use case. While saving the data scientist a lot of manual effort, performing this search is computationally costly. In this Applied ML Prototype, we go beyond what we can achieve with a laptop, and use the Cloudera Machine Learning Workers API to spin up an on-demand Dask cluster to distribute AutoML computations. This sets us up for automated machine learning at scale!
![]()
Summarize
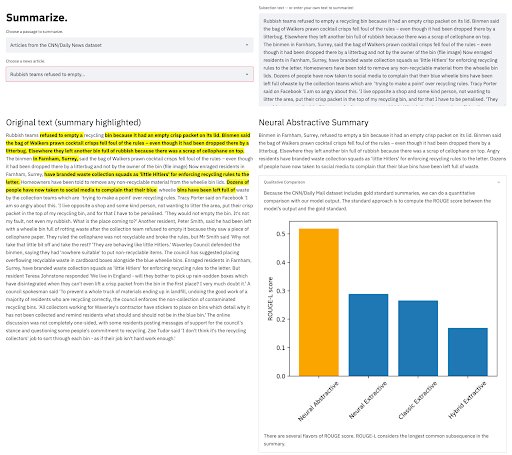
There is a wealth of information locked in written text, but gleaning insights from that information can be time-prohibitive. Automatic summarization is a powerful natural language processing capability with the potential to accelerate any text processing workflow by algorithmically summarizing an article, delivering the most important content to the user. This Applied ML Prototype uses the Cloudera Machine Learning Applications abstraction to provide a full user interface in which users can compare and contrast several summarization algorithms and strategies on multiple example articles. You can even have the models summarize your own input text!
![]()
Train Gensim’s Word2Vec

Popularized by word vector representations, “embeddings” have become a staple of modern machine learning — and they’re not just for words anymore! It’s become common to learn embeddings for all kinds of entities (e.g. retail products, hotel listings, user profiles, videos, music, etc). Just about anything can be represented as a numerical vector. Once learned, these vectors can be used in a myriad of downstream tasks like classification, clustering, or recommendation systems. This Applied ML Prototype provides a Jupyter Notebook demonstration of how to use the classic Word2Vec algorithm from the Gensim library to learn entity2vec embeddings, including guidance on how your data should be structured and to how to perform an efficient hyperparameter search to maximize Word2Vec’s ability to understand your entity data.
![]()
TensorBoard as a CML Application
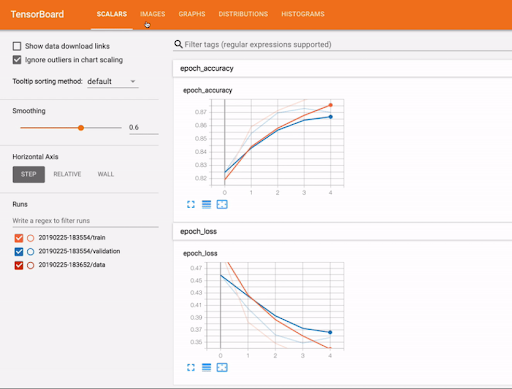
TensorBoard is a tool that provides the measurements and visualizations needed to help inspect, debug, and iterate during the machine learning workflow. It enables the tracking of experiment metrics like loss and accuracy, visualization of a model’s graph, projection of embeddings to a lower dimensional space, and much more. This Applied ML Prototype demonstrates how to run TensorBoard as an Application inside CML. To facilitate the demo, a minimal script is run to train a neural network on the MNIST digits dataset while capturing logs that are then visualized in the TensorBoard dashboard.
![]()
If you are not a Cloudera customer already, register for a test drive of Cloudera Data Platform (CDP) to see first hand just how easy AMPs are to use.
Editor's Choice


Thanks for the good article.