


Overview
This blog post describes support for materialized views for the Iceberg table format in Cloudera Data Warehouse.
Apache Iceberg is a high-performance open table format for petabyte-scale analytic datasets. It has been designed and developed as an open community standard to ensure compatibility across languages and implementations. It brings the reliability and simplicity of SQL tables to big data while enabling engines like Hive, Impala, Spark, Trino, Flink, and Presto to work with the same tables at the same time. Apache Iceberg forms the core foundation for Cloudera’s Open Data Lakehouse with the Cloudera Data Platform (CDP).
Materialized views are valuable for accelerating common classes of business intelligence (BI) queries that consist of joins, group-bys and aggregate functions. Cloudera Data Warehouse (CDW) running Hive has previously supported creating materialized views against Hive ACID source tables. Starting from the CDW Public Cloud DWX-1.6.1 release and the matching CDW Private Cloud Data Services release, Hive also supports creating, using, and rebuilding materialized views for Iceberg table format.
The key characteristics of this functionality are:
- Source tables of the materialized view are Iceberg tables (the underlying file format could be Parquet, ORC).
- The materialized view itself is an Iceberg table.
- Materialized views can be partitioned on one or more columns.
- Queries containing joins, filters, projections, group-by, or aggregations without group-by can be transparently rewritten by the Hive optimizer to use one or more eligible materialized views. This can potentially lead to orders of magnitude improvement in performance.
- Both full and incremental rebuild of the materialized view are supported. Incremental rebuild can be done under qualifying conditions.
Create Iceberg materialized view
For the examples in this blog, we will use three tables from the TPC-DS dataset as our base tables: store_sales, customer and date_dim.
These tables are created as Iceberg tables. For instance:
create table store_sales ( `ss_sold_time_sk` int, … … `ss_net_profit` decimal(7,2)) PARTITIONED BY ( `ss_sold_date_sk` int) stored by iceberg stored as orc ;
It is the same for the other two tables. We populated the tables using INSERT-SELECT statements by reading from text format source tables but they can be populated through any ETL process.
Let’s create a materialized view that joins the three tables, has filter conditions, and does grouped aggregation. Such a query pattern is quite common in BI queries. Note that the materialized view definition contains the ‘stored by iceberg’ clause. Furthermore, it is partitioned on the d_year column.
drop materialized view year_total_mv1; create materialized view year_total_mv1 PARTITIONED ON (dyear) stored by iceberg stored as orc tblproperties ('format-version'='2') AS select c_birth_country customer_birth_country ,d_year dyear ,sum(ss_ext_sales_price) year_total_sales ,count(ss_ext_sales_price) total_count from customer ,store_sales ,date_dim where c_customer_sk = ss_customer_sk and ss_sold_date_sk = d_date_sk and d_year between 1999 and 2023 group by c_birth_country ,d_year ;
Show materialized view metadata
Similar to a regular table, you can describe the materialized view to show metadata.
DESCRIBE FORMATTED year_total_mv1;
A few key characteristics are listed below (extracted from the DESCRIBE output):

As shown above, this materialized view is enabled for rewrites and is not outdated. The snapshotId of the source tables involved in the materialized view are also maintained in the metadata. Subsequently, these snapshot IDs are used to determine the delta changes that should be applied to the materialized view rows.
SHOW MATERIALIZED VIEWS;

The last column indicates that the materialized view can be incrementally maintained in the presence of insert operations only. If the base table data is modified through an UPDATE/DELETE/MERGE operation, then the materialized view must go through a full rebuild. In a future version, we intend to support incremental rebuild for such cases.
A materialized view can also be explicitly disabled for rewrites. This is similar to disabling indexes in databases for certain reasons.
ALTER MATERIALIZED VIEW year_total_mv1 DISABLE REWRITE;
Conversely, it can be enabled as follows:
ALTER MATERIALIZED VIEW year_total_mv1 ENABLE REWRITE;
Query planning using materialized view
Let’s first consider a simple case where the grouping columns and aggregate expression exactly match one of the materialized views.
explain cbo select c_birth_country customer_birth_country ,d_year dyear ,sum(ss_ext_sales_price) year_total_sales from customer ,store_sales ,date_dim where c_customer_sk = ss_customer_sk and ss_sold_date_sk = d_date_sk and d_year between 2000 and 2003 group by c_birth_country ,d_year ;
CBO PLAN:
HiveProject(customer_birth_country=[$0], dyear=[$3], year_total_sales=[$1]) HiveFilter(condition=[BETWEEN(false, $3, 2000, 2003)]) HiveTableScan(table=[[tpcds_iceberg, year_total_mv1]], table:alias=[tpcds_iceberg.year_total_mv1])
The above CBO (cost based optimizer) plan shows that only the year_total_mv1 materialized view is scanned and a filter condition applied since the range filter in the query is a subset of the range in the materialized view. Thus, the scans and joins of the three tables in the original query are not needed and this can improve performance significantly due to both I/O cost saving and the CPU cost saving of computing the joins and aggregations.
Now consider a more advanced usage where the group-by and aggregate expressions in the query don’t exactly match the materialized view but can potentially be derived.
explain cbo select c_birth_country customer_birth_country ,avg(ss_ext_sales_price) year_average_sales from customer ,store_sales ,date_dim where c_customer_sk = ss_customer_sk and ss_sold_date_sk = d_date_sk and d_year between 2000 and 2003 group by c_birth_country ;
CBO PLAN:
HiveProject(customer_birth_country=[$0], year_average_sales=[CAST(/($1, COALESCE($2, 0:BIGINT))):DECIMAL(11, 6)]) HiveAggregate(group=[{0}], agg#0=[sum($1)], agg#1=[sum($2)]) HiveFilter(condition=[BETWEEN(false, $3, 2000, 2003)]) HiveTableScan(table=[[tpcds_iceberg, year_total_mv1]], table:alias=[tpcds_iceberg.year_total_mv1])
Here, the materialized view year_total_mv1 contains the SUM and COUNT aggregate expressions which are used to derive the AVG(ss_ext_sales_price) expression for the query. Further, since the query contains GROUP BY c_birth_country only, a second-level grouping is done on c_birth_country to produce the final output.
Incremental and full rebuild of materialized view
We will insert rows into the base table and examine how the materialized view can be updated to reflect the new data.

Due to the table modification, Iceberg creates new snapshots and the metadata table “snapshots” can be examined to view the new snapshot version:
SELECT * FROM tpcds_iceberg.store_sales.snapshots;
Note that the materialized view is now marked outdated for rewriting because their contents are now stale:
DESCRIBE FORMATTED year_total_mv1;
Outdated for Rewriting: Yes
Running the original query now will not leverage the materialized view and instead do the full scan of the source tables followed by the joins and group-by.
Let us now rebuild the materialized view:
ALTER MATERIALIZED VIEW year_total_mv1 REBUILD;
This does an incremental rebuild of the materialized view by reading only the delta changes from the store_sales table. Hive does this by asking the Iceberg library to return only the rows inserted since that table’s last snapshot when the materialized view was last rebuilt/created. It then computes the aggregate values for these delta rows after joining them with the other tables. Finally, this set of rows is outer joined with the materialized view using the grouping columns as the join key and the appropriate aggregate values are consolidated—for example, the old sum and the new sum are added together and the old min/max aggregate values may be replaced with the new one depending on whether the new value is lower/higher than the old one.
The rebuild of the materialized view is triggered manually here but it can also be done on a periodic interval using the scheduled query approach.
At this point, the materialized view should be available for query rewrites:
DESCRIBE FORMATTED year_total_mv1; Outdated for Rewriting: No
Re-running the original query will again use the materialized view.
Qualifying conditions for incremental rebuild
An incremental rebuild is not possible under the following situations:
- If the base table was modified through a DELETE/MERGE/UPDATE operation.
- If the aggregate function is anything other than SUM, MIN, MAX, COUNT, AVG. Other aggregates such as STDDEV, VARIANCE, and similar require a full scan of the base data.
- If any of the source tables were compacted since the last rebuild. Compaction creates a new snapshot consisting of merged files and it is not possible to determine the delta changes since the last rebuild operation.
In such situations, Hive falls back to the full rebuild. This fall-back is done transparently as part of the same REBUILD command.
A Note on Iceberg materialized view specification
Currently, the metadata needed for materialized views is maintained in Hive Metastore and it builds upon the materialized views metadata previously supported for Hive ACID tables. Over the past year, the Iceberg community has proposed a materialized view specification. We intend to adopt this specification in the future for Hive Iceberg materialized view support.
Performance with materialized views
In order to evaluate the performance of queries in the presence of materialized views in Iceberg table format, we used a TPC-DS data set at 1 TB scale factor. The table format was Iceberg and the underlying file format was ORC (similar tests can be performed with Parquet but we chose ORC as most Hive customers use ORC). We ran the ANALYZE command to gather both table and column statistics on all the base tables.
We started with twenty three TPC-DS queries and created variants of them such that we had a total of fifty queries in the workload. Each query had between one to three variants. A variant was created by one of the following modifications: (a) adding extra columns in the GROUP-BY clause (b) adding extra aggregation function in the SELECT list, and (c) adding or modifying single table WHERE predicates. We obtained the EXPLAIN CBO (cost based optimization) plan in JSON format for all the fifty queries and supplied the plans to a materialized view recommender that is supported by Cloudera Data Warehouse. Based on the ranked recommendations, we picked the top seven materialized views and created them in the Iceberg table format. We ran the fifty query workload on a CDW Hive virtual warehouse on AWS using a large t-shirt size (see Virtual Warehouse sizes) . Each query was run three times and the minimum total execution time was captured. The query performance results are shown below with and without the materialized view rewrite enabled. The following configuration option is toggled for this:
SET hive.materializedview.rewriting = false;
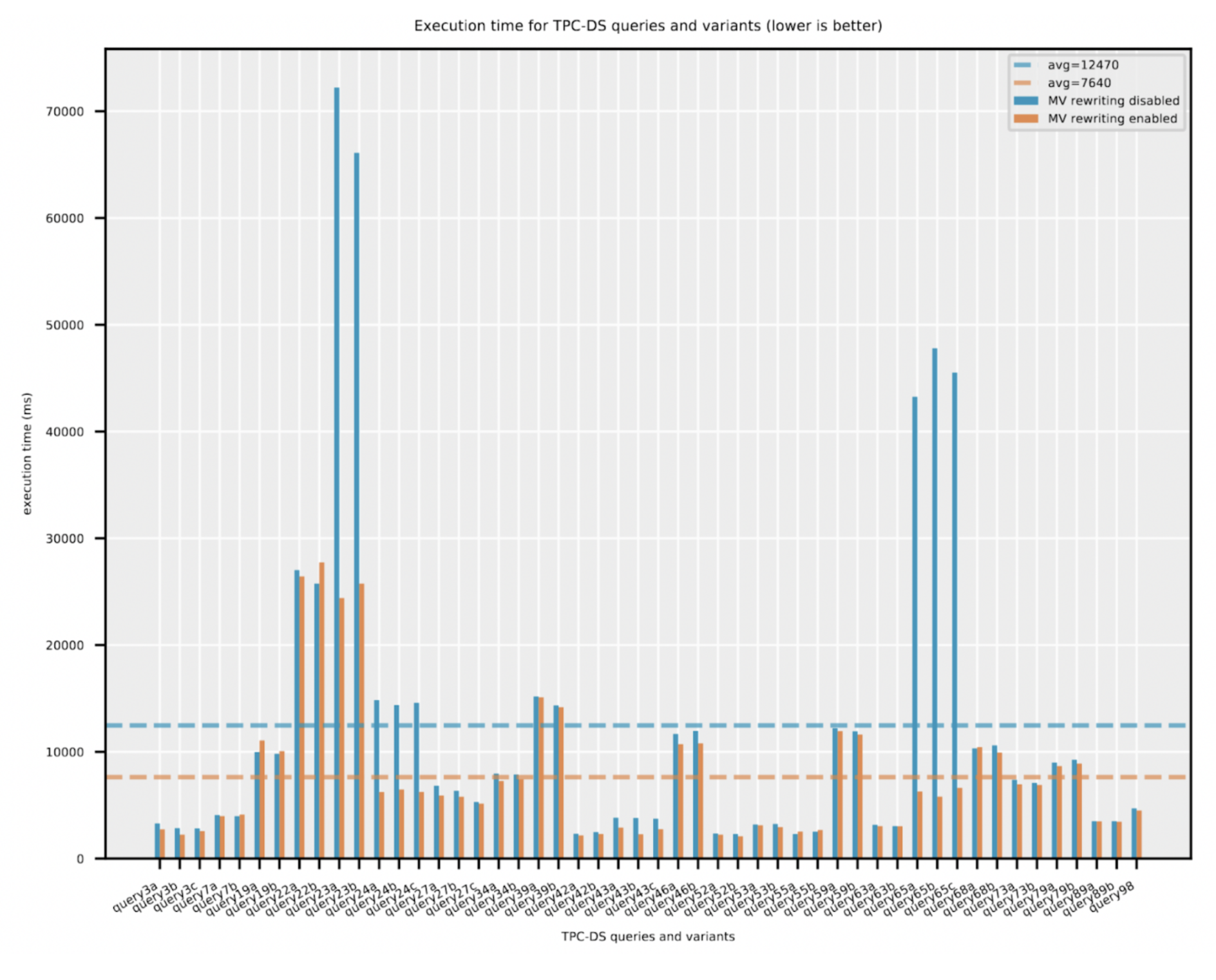
Out of the fifty queries, there are sixteen queries which the optimizer planned using materialized views. A few of the longer running queries benefited the most by the materialized views – for example the query65 a, b, c variants showed a reduction of nearly 85% in the elapsed time. Overall, across all queries, the average reduction in total elapsed time was 40%. We also looked at only the query compilation time overhead for queries that did not hit the materialized views. A slight increase of 4% in the average query compilation time, approximately 60 milliseconds, was observed due to the optimizer attempting to evaluate the feasibility of using materialized views.
This performance evaluation focused on the query rewrite performance using materialized views. In a future blog, we will evaluate the incremental versus full rebuild performance.
Conclusion
This blog post describes the materialized view support in Hive for the Iceberg table format. This functionality is available in Cloudera Data Warehouse (CDW) Public Cloud deployments on AWS and Azure as well as in CDW Private Cloud Data Services deployments. Users can create materialized views on Iceberg source tables, and Hive will leverage these to accelerate query performance. When the source table data is modified, incremental rebuild of the materialized view is supported under qualifying conditions (stated above); otherwise, a full rebuild is done.
The support for Apache Iceberg as the table format in Cloudera Data Platform and the ability to create and use materialized views on top of such tables provides a powerful combination to build fast analytic applications on open data lake architectures. Sign up for one of our next hands-on labs to try Apache Iceberg on Cloudera’s lakehouse and see the benefits and ease of using materialized views. You can also sign up for the webinar to learn more about the benefits of Apache Iceberg and watch the demo to see the latest capabilities.
Acknowledgement
The authors would like to acknowledge the assistance of Soumyakanti Das in gathering the performance results.
Editor's Choice

