

This is the fourth post in a series that explores the theme of enabling diverse workloads in YARN. See the introductory post to understand the context around all the new features for diverse workloads as part of YARN in HDP 2.2.
Introduction
When it comes to managing resources in YARN, there are two aspects that we, the YARN platform developers, are primarily concerned with:
- Resource allocation: Application containers should be allocated on the best possible nodes that have the required resources and
- Enforcement and isolation of Resource usage: On any node, don’t let containers exceed their promised/reserved resource-allocation
From its beginning in Hadoop 1, all the way to Hadoop 2 today, the compute platform has always supported memory based allocation and isolation. Specifically with YARN, applications can (a) specify the amount of memory required for each of their containers, and after that, (b) allocations occur on nodes that have the requisite amount of free memory, taking into account more scheduling dimensions like data-locality, queue utilization etc.
For applications such as MapReduce, this model works very well – most MapReduce applications are memory hungry, primarily disk bound and contention for CPU is relatively low. However, as more and more variety of workloads have started moving to run on top of YARN, the need for the compute platform to support CPU as a first-class resource rose rapidly.
Identifying CPU as a first-class resource
A few important questions that come up when considering CPU as a resource are
- How does an application inform its CPU requirements to the platform?
- How does a NodeManager (NM) tell the ResourceManager (RM) as to how much CPU is available for consumption by all YARN containers?
- In clusters with heterogeneous hardware, how does one account for nodes with faster CPUs?
The answer to the above questions is the introduction of a new concept called ‘vcores’ – short for virtual cores. Number of vcores has to be set by an administrator in yarn-site.xml on each node. The decision of how much it should be set to is driven by the type of workloads running in the cluster and the type of hardware available. The general recommendation is to set it to the number of physical cores on the node, but administrators can bump it up if they wish to run additional containers on nodes with faster CPUs.
When NMs startup, they report this value to the RM which in turn uses it to make calculations about allocation of CPU resources in the cluster. On the other hand, applications specify vcores as part of their allocation-requests as well. This lets the RM know about their resource requirements from a CPU perspective.
Pluggable resource-vector in YARN scheduler
The CapacityScheduler has the concept of a ResourceCalculator – a pluggable layer that is used for carrying out the math of allocations by looking at all the identified resources. This includes utilities to help make the following decisions:
- Does this node have enough resources of each resource-type to satisfy this request?
- How many containers can I fit on this node, sorting a list of nodes with varying resources available.
There are two kinds of calculators currently available in YARN – the DefaultResourceCalculator and the DominantResourceCalculator.
The DefaultResourceCalculator only takes memory into account when doing its calculations. This is why CPU requirements are ignored when carrying out allocations in the CapacityScheduler by default. All the math of allocations is reduced to just examining the memory required by resource-requests and the memory available on the node that is being looked at during a specific scheduling-cycle.
Supporting CPU scheduling through DominantResourceCalculator
The support for CPU as a resource has existed for a while in the CapacityScheduler in the form of another calculator – the DominantResourceCalculator – that takes CPU also into account when doing its calculations.
When you have two dimensions (memory and CPU), how do you make scheduling decisions? The solution to this comes from the Dominant Resource Fairness (DRF) [1] policy – at every point make decisions based on what the dominant/bottleneck resource is and create allocations based on that.
The following picture depicts the resource distribution on one node where the resources – both memory and CPU – are allocated:
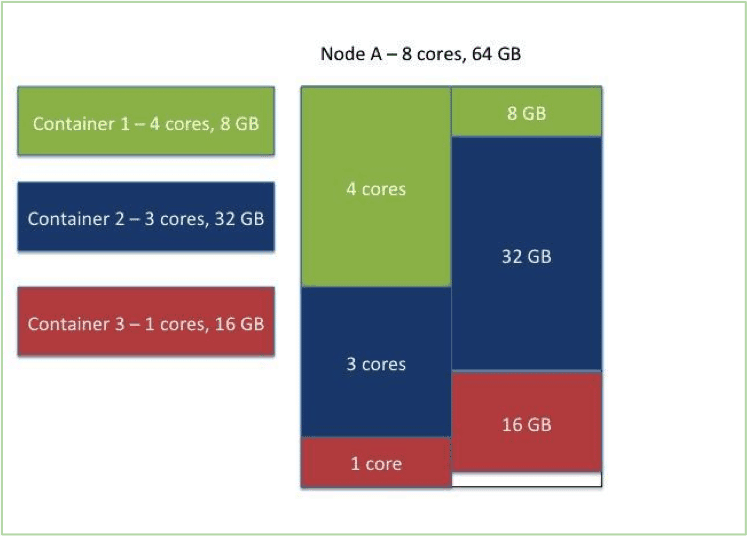
The DominantResourceCalculator uses the dominant resource calculations with support only for memory and CPU as of now – in the future this can be extended to respect other resource-types as well.
Note that YARN’s CapacityScheduler doesn’t really use the fairness policy part in DRF, it uses the concept of dominant-resource in its calculations so as to decide if an application fits on a node or not. Once that decision is made, other scheduling policies that already exist in the scheduler (like queue capacities, FIFO ordering, user-limits) take over control of the ultimate container placement.
Impact on application-level scheduling
The introduction of CPU as a resource may have an impact on applications running in a YARN cluster – specifically applications that carry out their own second-level scheduling. Applications do not really know at run-time whether the RM is using the DefaultResourceCalculator or the DominantResourceCalculator. This leaves applications uninformed when they themselves are trying to schedule container requests to framework level entities like tasks.
MapReduce (MR) for example does not request resources for all the maps and reducers at once – it initially requests containers for maps and then starts requesting containers for reducers as the maps finish. Sometimes, due to hanging or stuck maps, it needs to give up some of the reducers so that it can re-launch the stuck maps. When RM uses DefaultResourceCalculator, MR AM simply looks at the memory required to launch the maps and gives up an appropriate amount of reducers. However, when the RM uses the DominantResourceCalculator – this could lead to a problem – the AM gives up the right amount of memory but how can it release the right amount of CPU? Similarly, if the AM gives up both memory and CPU, it may potentially give up too many resources if the RM is using the DefaultResourceCalculator.
To help address this, YARN in HDP 2.2 now exposes to applications the resource-types being considered during allocation. The AMs can now determine at run-time if the RM respects both memory and CPU resources or just memory. This allows applications to make smarter decisions when scheduling. The resource types are returned as part of the RegisterApplicationMasterResponse and can be accessed using the getSchedulerResourceTypes API. More details can be found in the YARN API documentation.
Some applications like the DistributedShell don’t carry out their own second-level scheduling – they simply ask the RM for all the containers they need, wait until the containers are allocated and then simply run the tasks on the individual containers. Such applications are not impacted by the introduction of CPU as a resource.
Cluster capacity-planning with multiple resource-types
On a cluster running the CapacityScheduler with the DefaultResourceCalculator, if the operator decides to switch to the DominantResourceCalculator – one can potentially see a drop in throughput. Why? The cluster may always have been bottlenecked on CPU resource even though the scheduler never recognized it in practice.
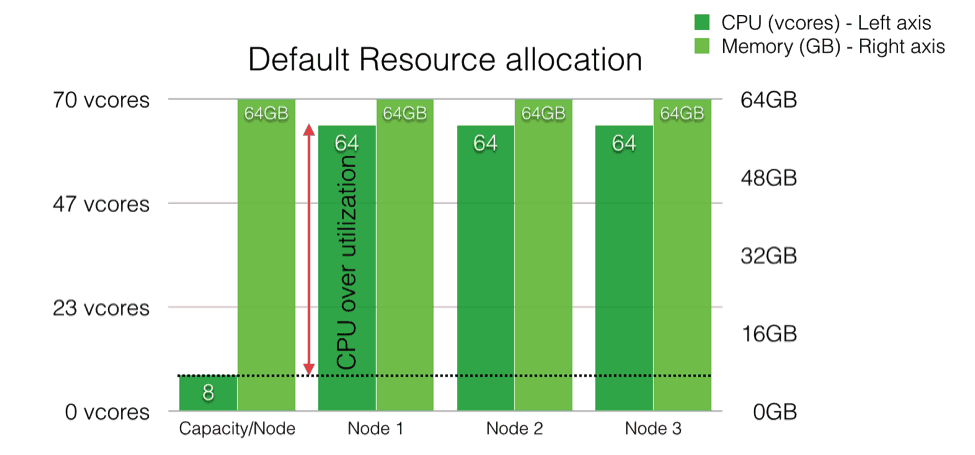
For instance, take clusters that have nodes with large amounts of memory and fewer cores (for a concrete example, nodes with 8 cores and 64GB RAM). If you take the default YARN container allocation sizes (1GB memory), you can potentially run 64 containers on this node with the DefaultResourceCalculator setup. Obviously, in this case, it is very likely that the cluster’s CPU resources are over-utilized as is shown above.
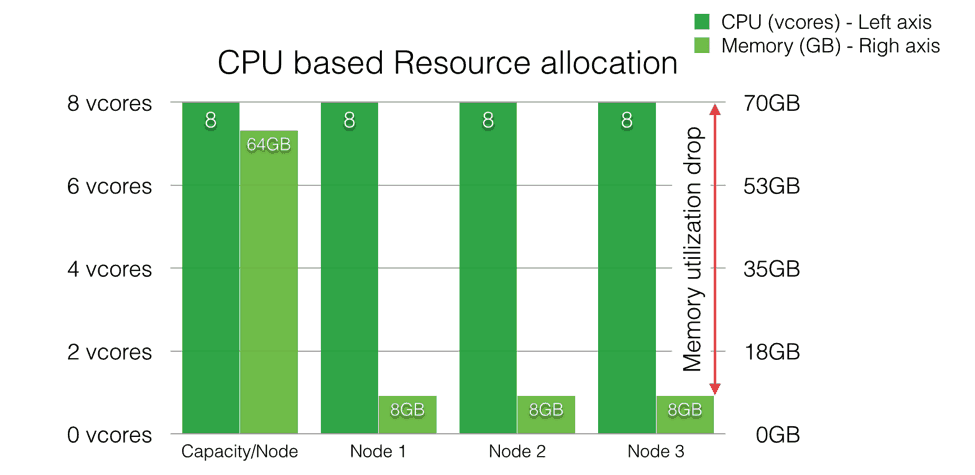
However, if you switch to the DominantResourceCalculator, you are restricted to running only 8 containers (since every container requires a minimum of 1 vcore) as shown below. Please be aware of this potential drop in utilization & throughput and run needed validation tests to ensure that your application SLAs aren’t adversely affected.
Configuration details
In order to enable CPU scheduling, there are some configuration properties that administrators and users need to be aware of.
- scheduler.capacity.resource-calculator: To enable CPU scheduling in CapacityScheduler, this should be set to org.apache.hadoop.yarn.util.resource.DominantResourceCalculator in capacity-scheduler.xml file.
- nodemanager.resource.cpu-vcores: Set to the appropriate number in yarn-site.xml on all the nodes. This is strictly dependant on the type of workloads running in a cluster, but the general recommendation is that admins set it to be equal to the number of physical cores on the machine.
MapReduce framework has its own configurations that users should use in order to take advantage of CPU scheduling in YARN.
- map.cpu.vcores: Set to the number of vcores required for each map task.
- reduce.cpu.vcores: Set to the number of vcores required for each reduce task.
- yarn.app.mapreduce.am.resource.cpu-vcores: Set to the number of vcores the MR AppMaster needs.
Conclusion
In this post, we talked about the addition of CPU as a first class resource-type from a scheduler perspective, how it can be used as well as any potential impact on applications. One key element that we’ve not yet covered is resource-isolation: how does the platform ensure that containers don’t exceed their allocated CPU. That will be covered in a separate follow-up blog post.
References
[1] Ghodsi et al. Dominant Resource Fairness: Fair Allocation of Multiple Resource Types
Editor's Choice


Could you please elaborate on how the resource allocations are enforced? The scheduler part ensures that the resources asked by the jobs currently running don’t exceed the available budget, but how exactly is it ensured that the jobs running don’t exceed the amount provisioned to them. Does Hadoop leverage cgroups for this?