

This blog post was published on Hortonworks.com before the merger with Cloudera. Some links, resources, or references may no longer be accurate.
This is the 8th blog of the Hadoop Blog series (part 1, part 2, part 3, part 4, part 5, part 6, part 7). In this blog, we will discuss how NameNode Federation provides scalability and performance benefits to the cluster.
The Apache Hadoop Distributed File System (HDFS) is highly scalable and can support petabyte-sizes clusters. However, the entire Namespace (file system metadata) is stored in memory. So even though the storage can be scaled horizontally, the namespace can only be scaled vertically. It is limited by the how many files, blocks and directories can be stored in the memory of a single NameNode process.
Federation was introduced in order to scale the name service horizontally by using multiple independent Namenodes/ Namespaces. The Namenodes are independent of each other and there is no communication between them. The Namenodes can share the same Datanodes for storage.
Key Benefits
Scalability: Federation adds support for horizontal scaling of Namespace
Performance: Adding more Namenodes to a cluster increases the aggregate read/write throughput of the cluster
Isolation: Users and applications can be divided between the Namenodes
1. Use Case Examples
The benefits provided by Federation in terms of scalability, performance and isolation creates many use cases for it. We will discuss a few of them here.
1.1. Hive on Federation
Hive organizes table data into partitions to improve query performance. It stores the partitions in different locations. This opens up the opportunity to store and manage hive data in different namespaces. Using federated clusters, we can store different tables in different namespaces or store different partitions of the same table in different namespaces.
For example, we can store archival data which is not accessed frequently in a separate namespace and keep current data in a separate namespace. This would increase the performance efficiency of the namespace serving current data as its load is now reduced.
Let’s say we have a hive table partitioned on the year and we want to store all the data from the year 2000 onwards in one namespace (current) and rest of the data in another namespace (archived). This can be achieved using federation.
The figure below shows that the table Students has the partition ‘year=2018’ in NS1.
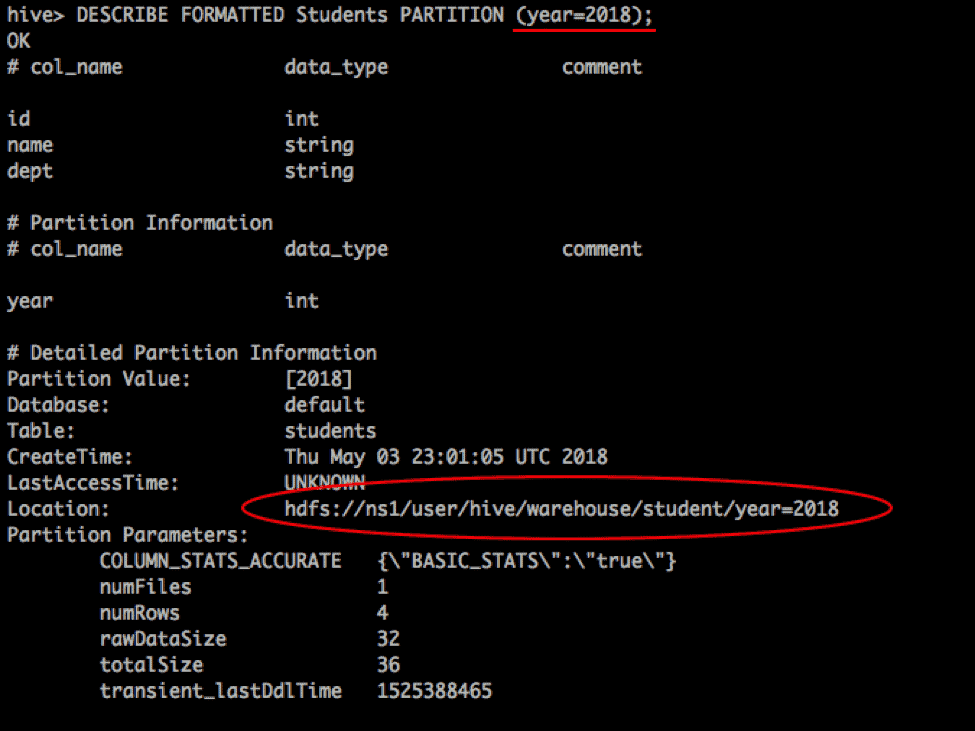
Now, if we want to store records for the year 1990 in NS2, we have to alter the table to set its location to NS2.
| hive> ALTER TABLE Students SET LOCATION ‘hdfs://ns2/user/hive/warehouse/student’; |
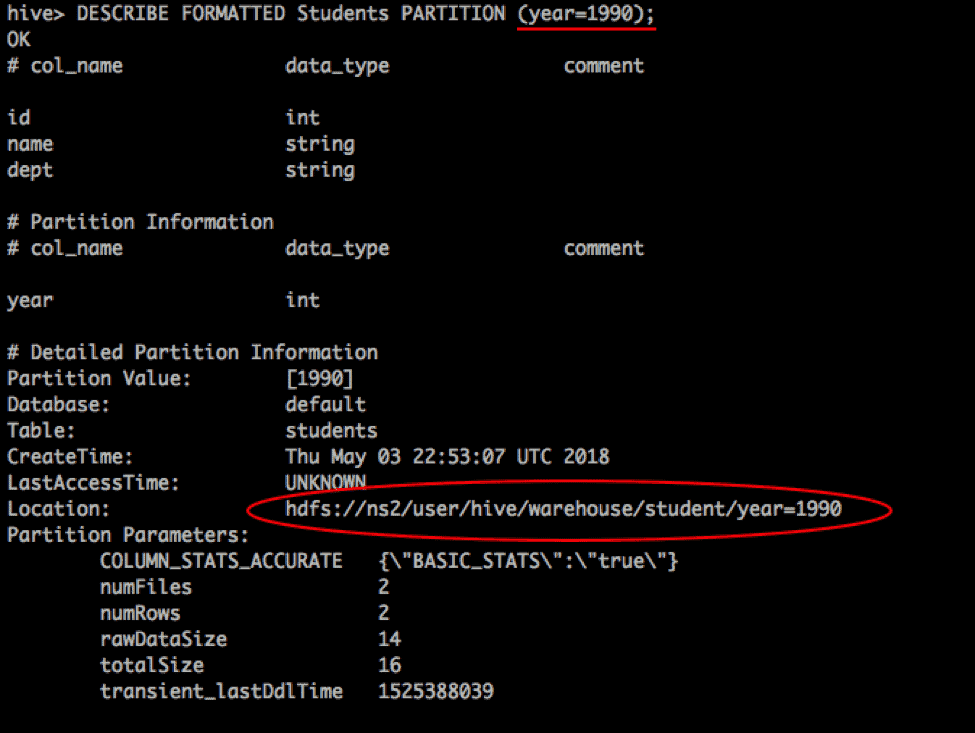
After changing the table’s location to the new namespace NS2, we can insert the data into required partitions. These partitions will now be created in NS2.
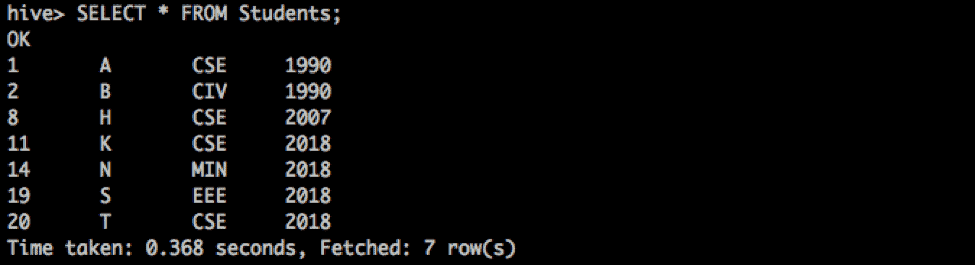
We can perform operations spanning multiple partitions in different namespaces in the same query. For example, a ‘SELECT *’ on the table would return records from partitions across different namespaces.
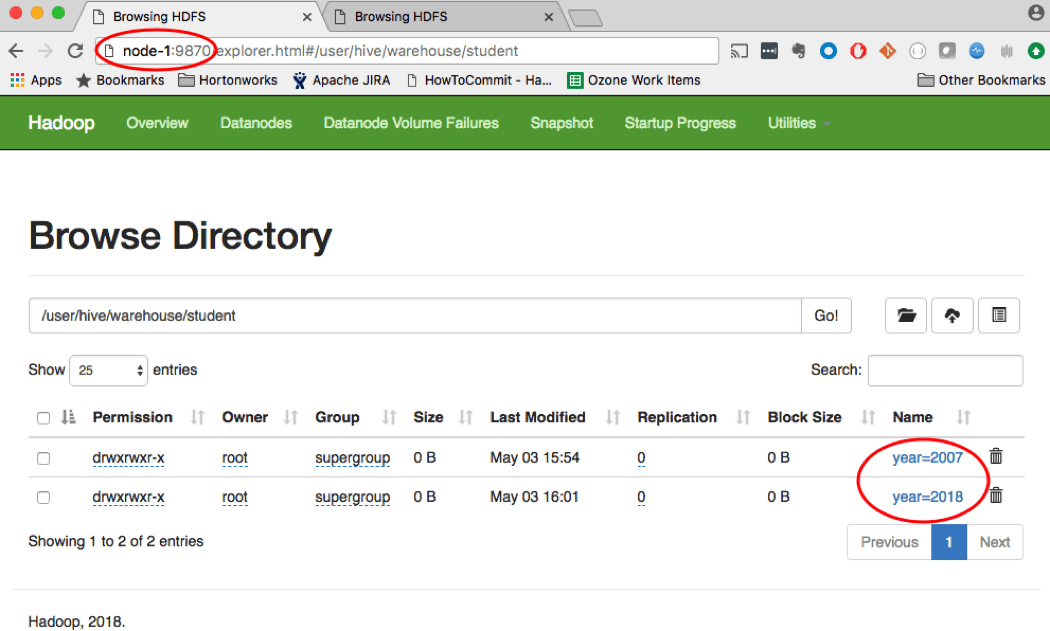
The figure below shows hive partitioned data for years 2007 and 2018 stored in nameservice NS1 (namenode running on node-1).
The archived data for the year 1990 is stored in NS2 (with namenode running on node-3), as shown below.
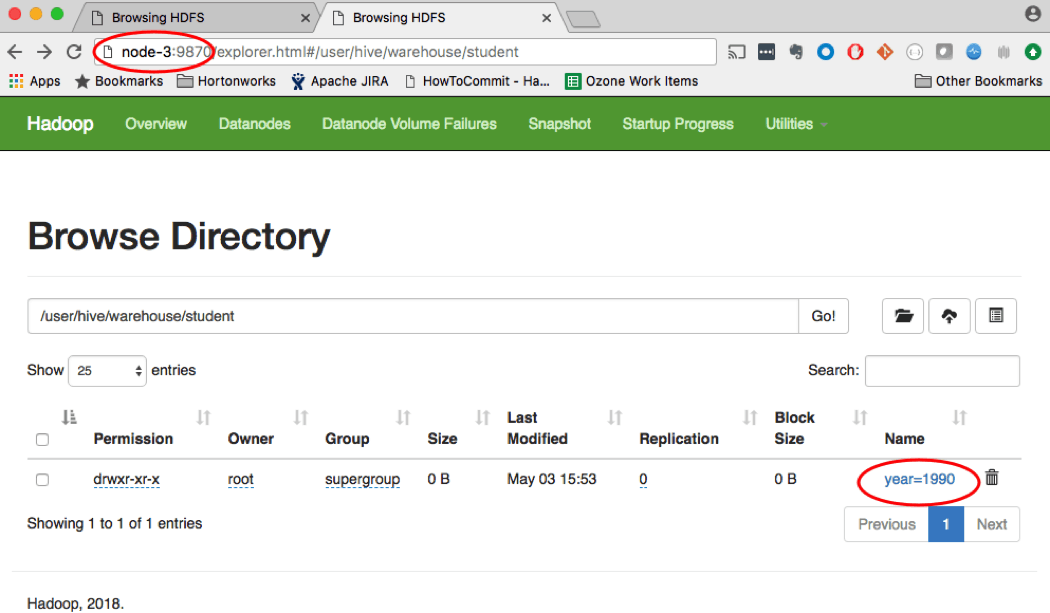
1.2. Isolating Applications
Let’s say we have a high intensity application, which blocks a large number of resources on the Namenode.This effects the latency of other applications. With federation, we can move such applications to a different namespace.
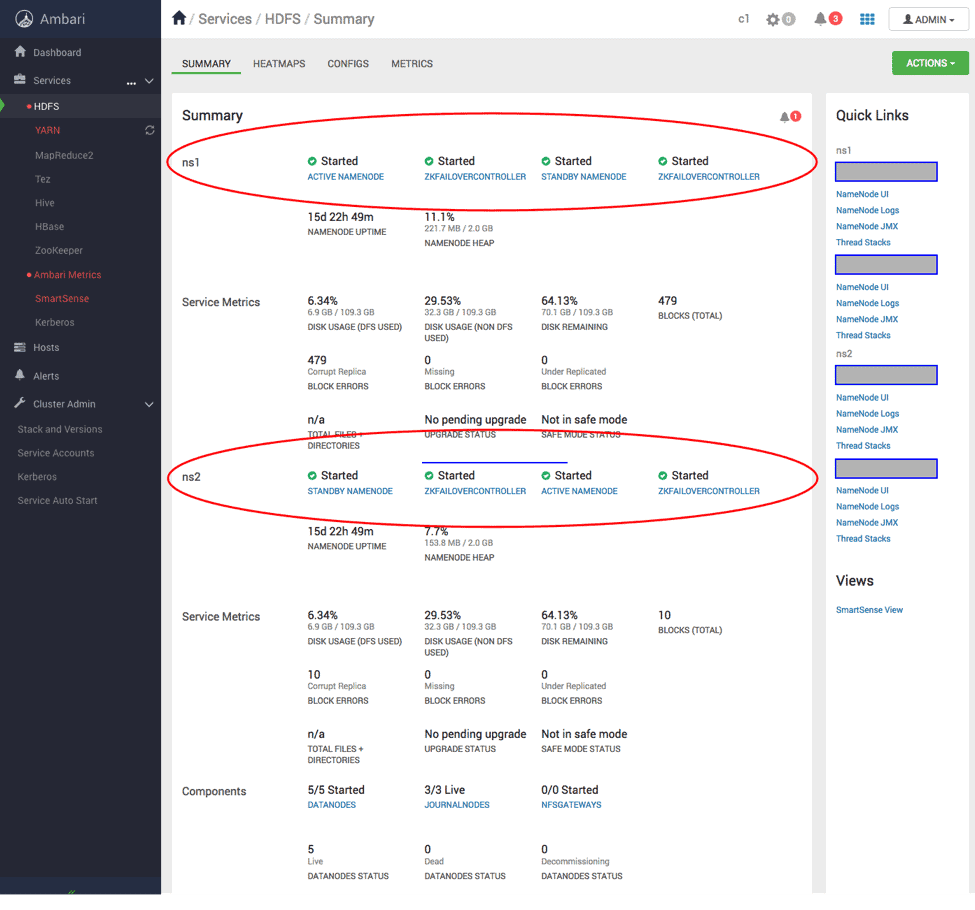
2. Ambari overview
A federated cluster view in Ambari will be shown below. The two nameservices will each have their corresponding components and metrics information. Other components such as Datanodes and Journalnodes will be shared by the two nameservices. All the config changed required to enable federation, as mentioned in the next section, are automatically taken care of by Ambari.
3. Config changes
To enable Federation and have more than one namespace in the cluster, some configuration changes are required in hdfs-site.xml. If you use Ambari to install your federated cluster, then it will set up the following configuration automatically. However, it can be helpful to understand how federation is configured under the covers. Let us take an example of a cluster with two Nameservices – NS1 and NS2.
3.1. NameserviceIDs
This configuration should be added to hdfs-site.xml with a comma separated list of NameserviceIDs.
<property> <name>dfs.nameservices</name> <value>ns1,ns2</value> </property> |
3.2. NamenodeIDs
For a Nameservice with HA setup, we need to specify the NamenodeIDs for the Namenodes belonging to that Nameservice. This is done by adding a comma separated list of NamenodeIDs to the key dfs.ha.namenodes suffixed with the NameserviceID.
<property> <name>dfs.ha.namenodes.ns1</name> <value>nn1,nn2</value> </property> <property> <name>dfs.ha.namenodes.ns2</name> <value>nn3,nn4</value> </property> |
3.3. RPC Addresses
The RPC and Service-RPC address should be configured for each Namenode in the cluster using the config keys – dfs.namenode.rpc-address and dfs.namenode.servicerpc-address (optional). This is done by suffixing the config key with NameserviceID and the NamenodeID.
<property> <name>dfs.namenode.rpc-address.ns1.nn1</name> <value>node-1.example.com:8020</value> </property> <property> <name>dfs.namenode.servicerpc-address.ns1.nn1</name> <value>node-1.example.com:8040</value> </property> <property> <name>dfs.namenode.rpc-address.ns1.nn2</name> <value>node-2.example.com:8020</value> </property> <property> <name>dfs.namenode.servicerpc-address.ns1.nn2</name> <value>node-2.example.com:8040</value> </property> <property> <name>dfs.namenode.rpc-address.ns2.nn3</name> <value>node-3.example.com:8020</value> </property> <property> <name>dfs.namenode.servicerpc-address.ns2.nn3</name> <value>node-3.example.com:8040</value> </property> <property> <name>dfs.namenode.rpc-address.ns2.nn4</name> <value>node-4.example.com:8020</value> </property> <property> <name>dfs.namenode.servicerpc-address.ns2.nn4</name> <value>node-4.example.com:8040</value> </property> |
3.4. HTTP Addresses
The HTTP and HTTPS addresses (dfs.namenode.http-address and dfs.namenode.https-address) are optional parameters which can be configured similar to RPC addresses.
<property> <name>dfs.namenode.http-address.ns1.nn1</name> <value>node-1.example.com:50070</value> </property> <property> <name>dfs.namenode.https-address.ns1.nn1</name> <value>node-1.example.com:50072</value> </property> <property> <name>dfs.namenode.http-address.ns1.nn2</name> <value>node-2.example.com:50070</value> </property> <property> <name>dfs.namenode.https-address.ns1.nn2</name> <value>node-2.example.com:50072</value> </property> <property> <name>dfs.namenode.http-address.ns2.nn3</name> <value>node-3.example.com:50070</value> </property> <property> <name>dfs.namenode.http-address.ns2.nn4</name> <value>node-4.example.com:50070</value> </property> |
3.5. Other Nameservice specific Keys
The following keys can be configured per nameservice by suffixing the key name with the NameserviceID.
- dfs.namenode.keytab.file
- dfs.namenode.name.dir
- dfs.namenode.edits.dir
- dfs.namenode.checkpoint.dir
- dfs.namenode.checkpoint.edits.dir
- dfs.secondary.namenode.keytab.file
- dfs.namenode.backup.address
4. Cluster Setup
All the Namenodes in the federated cluster should have the same clusterID. The following command should be used to format one namenode. A unique clusterID should be chosen such that it does not conflict with other clusters in the environment. If the clusterID is not provided, a unique ID is auto-generated.
[hdfs]$ $HADOOP_HOME/bin/hdfs namenode -format [-clusterId <clusterID>] |
All the other namenodes in the cluster must be formatted with the same clusterID as is for the first namenode.
[hdfs]$ $HADOOP_HOME/bin/hdfs namenode -format -clusterId <clusterID> |
If adding a new nameservice to an existing cluster, the new namenodes should be formatted with the same clusterID as is for the existing namenodes. The clusterID can be retrieved from the VERSION file in the Namenode.
5. References
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/Federation.html
Editor's Choice

