

Impala is designed to deliver insight on data in Apache Hadoop in real time. As data often lands in Hadoop continuously in certain use cases (such as time-series analysis, real-time fraud detection, real-time risk detection, and so on), it’s desirable for Impala to query this new “fast” data with minimal delay and without interrupting running queries.
In this blog post, you will learn an approach for continuous loading of data into Impala via HDFS, illustrating Impala ability to query quickly-changing data in real time. (Note: Kudu, the new columnar store for Hadoop that is currently in beta, is designed to achieve this goal in a much more streamlined and performant manner. In the meantime, the solution described below is a suitable workaround.)
Design Goals
As foreshadowed previously, the goal here is to continuously load micro-batches of data into Hadoop and make it visible to Impala with minimal delay, and without interrupting running queries (or blocking new, incoming queries). Because loading happens continuously, it is reasonable to assume that a single load will insert data that is a small fraction (<10%) of total data size.
For the purposes of this solution, we define “continuously” and “minimal delay” as follows:
- Continuously: batch loading at an interval of one minute or longer
- Minimal delay: batch loading delay + a few minutes
This process must also provide the following consistency guarantees:
- Single-table reference consistency: a table referenced in a query would either see the entire batch of data or no new data. No table reference will see part of the batch. However, if a table is referenced more than once (i.e. a self-join), then one table reference might see the new batch of data while the other does not. In other words, the table in the self-join is not guaranteed to be consistent. This is due to the fact that neither Impala nor Apache Hive use a snapshot of metadata during query planning. Therefore, changes in metadata (i.e. a new data file) during query planning can cause this inconsistency.
- Within a same connection (session), if a query sees the new batch of data, all subsequent queries will continue to see the data. However, this guarantee does not apply across sessions due to the “eventual consistency” of metadata in Impala. (It can be synchronized by using the query option sync DDL; see this link for more details.) Therefore, some queries might see the new data and some might not if they’re coming from a different session.
Solution Overview
Typically, data can be loaded directly into HDFS via Apache Flume, Apache Sqoop, Flafka, or HDFS put. (The details about how to trigger a data load is outside our scope here.) An ingestion frequency lower than once per minute is achievable. Because each ingestion will create some small files, frequent ingestion will create lots of small files, which are usually in Apache Avro or text format. Periodically, a compaction process is needed to combine these small files into bigger ones and convert them into a more efficient columnar format (such as Apache Parquet). The compaction frequency (perhaps every few hours) depends on a number of factors, such as the number of files generated.
Managing concurrent compaction and ingestion/query can be a challenge. The compaction process depends on an INSERT query, and it must read data from a directory that is not being actively written to (that is, the landing table)—otherwise, the source directory will have to be compacted again later. Furthermore, compaction must not overwrite a directory that is being actively read (the landing table and the base table, for example). Otherwise, the existing query will fail and newly loaded data will be lost.
The solution to this challenge is to use two landing tables; only one table is active for ingestion at a time but both are active for the read query initially. Compaction will read from the non-active one. The destination of the compaction will be a new directory that is not actively queried. Once the compaction completes, the pre-compacted data directory should be removed from the inactive landing table and the compacted data directory added to the base table.
Because the remove and add are DDL operations and a small window in-between the two DDLs can cause data inconsistency, a new base table points to existing data from the base table and the compacted directories, which contains all the data from the inactive landing table. Then a new view is created to encapsulate both the new table and the active landing table. Therefore, the existing query will continue to read from the pre-compacted table without any interruption. New queries will read the compacted data and won’t see the pre-compacted files. When all the existing queries are finished, the pre-compacted data can be dropped.
Example
To help illustrate the approach, let’s walk through an example. First, create a store_sales schema:
Create table store_sales( txn_id int, item_id int, sales double, … ) partitioned by ( sales_date string, store_id int ) stored as parquet location ‘/user/hive/warehouse/store_sales/’;
To prepare for ingestion, create a landing table, just like the store_sales table.
Create store_sales_landing_tbl like store_sales location ‘/user/hive/warehouse/store_sales_landing_tbl/’ stored as avro;
In this example, the landing data format is Avro, but it can also be text or Parquet. Make sure that the directory is created in HDFS and accessible (both read and write) to Impala.
Introduce a view to encapsulate both store_sales and the store_sales_landing_tbl.
Create view store_sales_view_1 as select * from store_sales union all store_sales_landing_tbl;
All queries will query against view store_sales_view_1.
Ingestion (Frequency: Once per Minute)

Load data into store_sales_landing_tbl directly. Let’s say you load data into the following two partitions:
/store_sales_landing_tbl/sales_date=20150512/store_id=123 /store_sales_landing_tbl/sales_date=20150512/store_id=256
If the loading is done outside of Impala (e.g., via Flume), you need to add the partitions for the newly created directory. Using Hive’s msck repair store_sales_landing_tbl command will detect the new directories and add the missing partitions. Because Impala caches table metadata (such as the list of partitions), you need to refresh the table metadata in Impala using refresh store_sales_landing_tbl. That means, if the ingestion is happening once per min, the msck repair and refresh need to be run every minute. (Note: Impala recently added a new alter table recover partitions command as well; see IMPALA-1568.)
The landing table only has one day’s worth of data and shouldn’t have more than ~500 partitions, so msck repair table should complete in a few seconds. The time spent in msck repair table is proportional to the number of partitions. If you go over 500 partitions, it will still work, but it’ll take more time.
Update Stats
As noted previously, because loading is frequent, it is unlikely that a single load will add a substantial fraction (>10%) of the partition. Based on this assumption, we recommend updating the row-count stats hourly using a background job. To get the new row count, you need to know the existing row count and the number of new rows. Since there are only ~500 partitions to track, the ingestion process can track the row count in a text file in HDFS. However, if the ingestion process can’t tell the number of new rows (i.e. hdfs put <file>), you need to issue a query to get the row count:
select store_id, count(*) from store_sales_landing_tbl
where sales_date=20150512 group by store_id;
Once you get the row count (for example, 7,012 for store 123 and 3,451 for store 256), use this SQL statement to update the row count for the table and each affected partition manually:
alter table store_sales_landing_tbl partition(sales_date=20150512, store_id=123) set tblproperties(‘numRows=’7012’, STATS_GENERATED_VIA_STATS_TASK’=’true’); alter table store_sales_landing_tbl partition(sales_date=20150512, store_id=256) set tblproperties(‘numRows=’3451’, STATS_GENERATED_VIA_STATS_TASK’=’true’);
See how Impala uses stats via this link.
Preparing for Compaction
Using store_sales_landing_tbl helps achieve a high ingestion frequency. One side effect of frequent ingestion is that it will create lots of small files. File compaction is a well-understood process, but we are trying to achieve “online” compaction here: compacting files while queries and ingestion are running. To achieve that, you need a few more views/tables. The following diagram shows the proper setup.
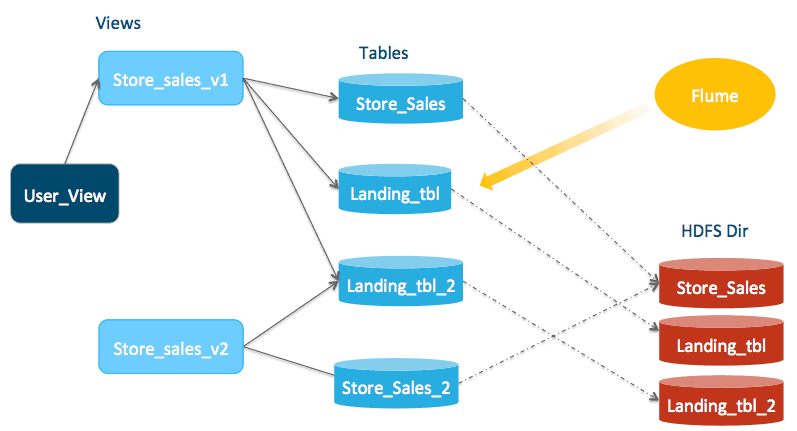
First, create a pair of tables (store_sales_2 and store_sales_landing_tbl_2). They should have the same structure and metadata as store_sales. Store_sales_2 should have exactly the same data as store_sale by pointing to the same data location as store_sales. The store_sales_landing_tbl_2 table is empty initially.
Here are the create table statements:
In Hive:
Create store_sales_2 like store_sales location ‘/user/hive/warehouse/store_sales/’;
Msck repair store_sales_2
(Because store_sales_2 and store_sales share the same directory, msck repair store_sales_2 will add all partitions in store_sales to store_sales_2.)
In Impala:
Invalidate Metadata store_sales_2;
Create store_sales_landing_tbl_2 like store_sales_landing_tbl location ‘/user/hive/warehouse/store_sales_landing_tbl_2/’;
Make sure that the directories are created in HDFS and accessible (both read and write) to Impala.
Now, the original view store_sales_view_1 needs to encapsulate store_sales, store_sales_landing_tbl and store_sales_landing_tbl_2.
In Hive:
create or replace view store_sales_view_1
select * from store_sales
union all
select * from store_sales_landing_tbl
union all
select * from store_sales_landing_tbl_2;
Create another view, store_sales_view_2, that points to store_sales_2 and landing_table_2.
In Hive:
create or replace view store_sales_view_2
select * from store_sales_2
union all
select * from store_sales_landing_tbl_2;
Users query store_sales_view_1 via yet another view, store_sales_store_sales_view.
In Hive:
create or replace view store_sales_store_sales_view
select * from store_sales_view_1;
After executing the above “create or replace view in Hive”, we need to propagate the new metadata to Impala via issuing the following:
In Impala:
invalidate metadata store_sales_view_1; invalidate metadata store_sales_view_2; invalidate metadata store_sales_store_sales_view;
Here’s the state of the view/table:
store_sales_store_sales_view -> store_sales_view_1 store_sales_view_1 -> store_sales, store_sales_landing_tbl, store_sales_landing_tbl_2 store_sales_view_2 -> store_sales_2, store_sales_landing_tbl_2
Compaction (Frequency: Daily)
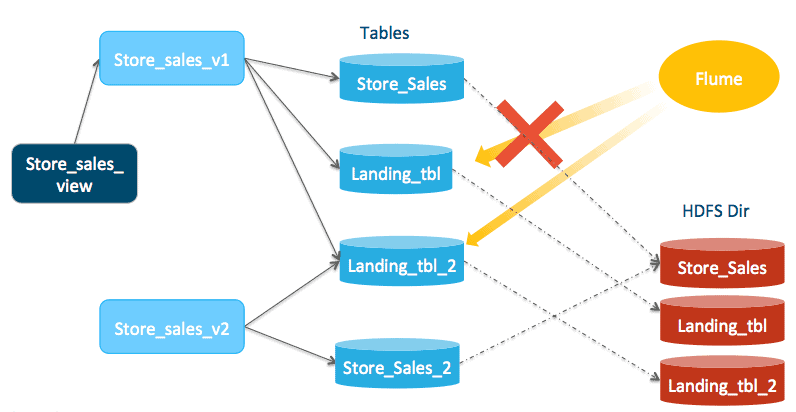
Point the ingestion to store_sales_landing_tbl_2. Ingestion can continue without any interruption but only against the _2 tables; that is, new ingestion writes to /store_sales_landing_tbl_2/, execute msck repair store_sales_landing_tbl_2, and then refresh store_sales_landing_tbl_2 in Impala. Wait for the last ingestion that operates on store_sales_landing_tbl to finish (wait for the last refresh store_sales_landing_tbl to finish) before proceeding to the next step.
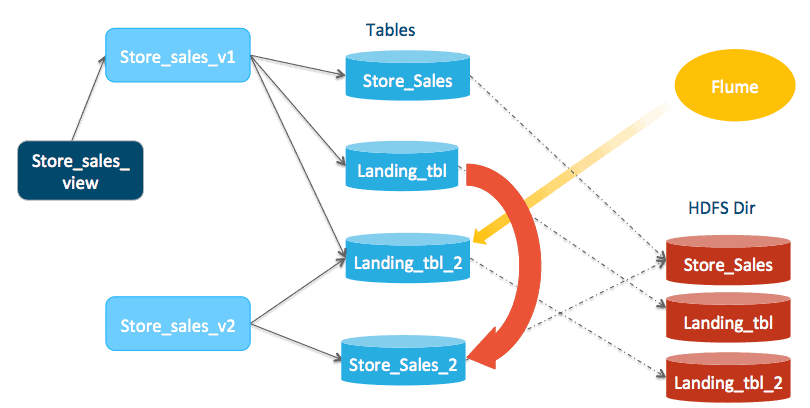
Copy and compact the data from store_sales_landing_tbl to store_sales_2.
INSERT INTO store_sales_2 [shuffle] select * from store_sales_landing_tbl;
Update the row count stats for each partition in store_sales_2 that are modified. The list of modified partitions in store_sales_2 is identical to that from store_sales_landing_tbl. So, using show partitions store_sales_landing_tbl, we know which partitions of store_sales_2 are modified.
Following the example above, we have two partitions in store_sales_landing_tbl. So, execute the following:
alter table store_sales_2 partition(sales_date=20150512, store_id=123) set tblproperties(‘numRows=’7012’, STATS_GENERATED_VIA_STATS_TASK’=’true’); alter table store_sales_2 partition(sales_date=20150512, store_id=256) set tblproperties(‘numRows=’3451’, STATS_GENERATED_VIA_STATS_TASK’=’true’);
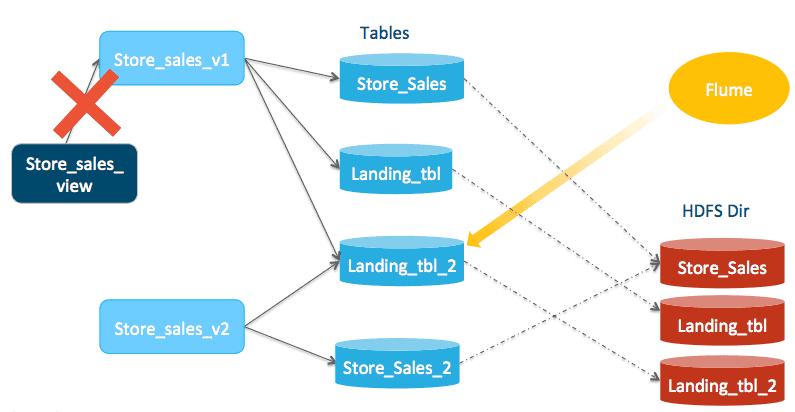
Next, point the store_sales_view to view store_sales_view_2. (In Hive) Create or replace view store_sales_view as select * from store_sales_view_2; (In Impala) invalidate metadata store_sales_view; newly incoming queries will now see the compacted data as well as data in the store_sales_landing_tbl_2. Any existing running query is unaffected and will continue to read from tables pointed by store_sales_view_1.
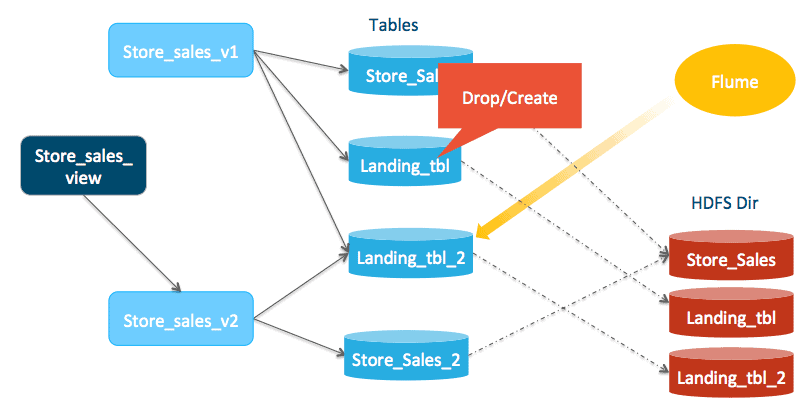
Now we clean up the small files in store_sales_landing_tbl once all queries against store_sale_view_1 cease. Let’s say the longest query that read from store_sale_store_sales_view won’t be longer than 15 minutes. After that period, no query will be reading from view store_sales_view_1 (i.e. store_sales and store_sales_landing_tbl). Delete the original small files in store_sales_landing_tbl after 15 minutes by dropping and re-creating table store_sales_landing_tbl. It is important to do drop/re-create rather than TRUNCATE because we need to drop all partitions.
drop table store_sales_landing_tbl;
Create store_sales_landing_tbl like store_sales
location ‘/user/hive/warehouse/store_sales_landing_tbl’
stored as avro;
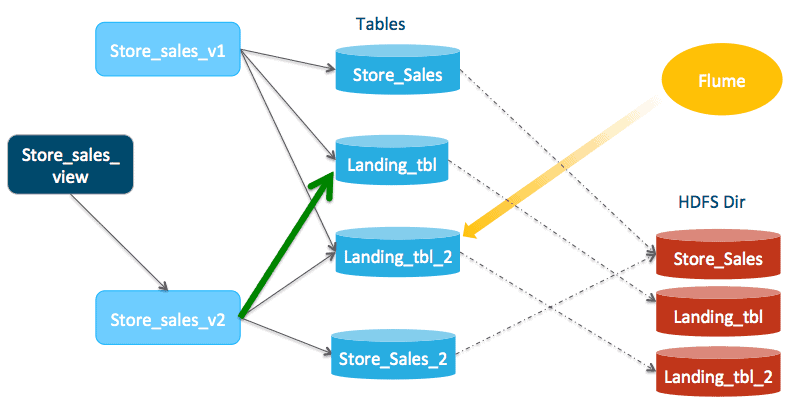
Add store_sales_landing_tbl back to store_sales_view_2.
In Hive:
Create or replace view store_sales_view_2
select * from store_sales_2
union all
select * from store_sales_landing_tbl
union all
select * from store_sales_landing_tbl_2;
In Impala:
invalidate metadata store_sales_view_2;

Synchronize the metadata (list of partitions) of store_sales with store_sales_2. For each partition that is added to store_sales_2, add it back to store_sales and update the row count of the newly added partition.
You’ve already identified the list of modified partition of store_sales_2 in a previous step. Using the same list, execute the following command:
alter table store_sales add partition(sales_date=20150512, store_id=123); alter table store_sales add partition(sales_date=20150512, store_id=256); alter table store_sales partition(sales_date=20150512, store_id=123) set tblproperties(‘numRows=’7012’, STATS_GENERATED_VIA_STATS_TASK’=’true’); alter table store_sales partition(sales_date=20150512, store_id=256) set tblproperties(‘numRows=’3451’, STATS_GENERATED_VIA_STATS_TASK’=’true’)
Because both tables share the same data location, after this step, both store_sales and store_sales_2 will have the same data set again.
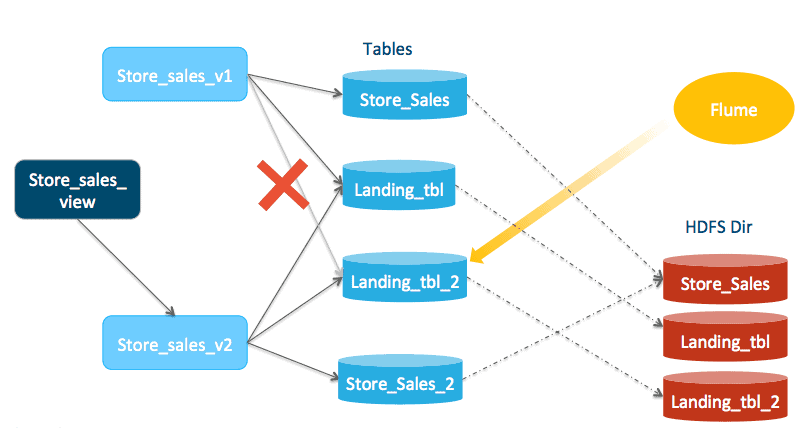
Next, remove store_sales_landing_tbl_2 from view store_sales_view_1.
In Hive:
Create or replace view store_sales_view_1 select * from store_sales union all select * from store_sales_landing_tbl;
In Impala:
invalidate metadata store_sales_view_1;
Now the state of all the views/tables is identical to what it was initially except that it is swapped with the _2 tables! Here’s the current state:
store_sales_view -> store_sales_view_2 store_sales_view_1 -> store_sales, store_sales_landing_tbl store_sales_view_2 -> store_sales_2, store_sales_landing_tbl_2, store_sales_landing_tbl
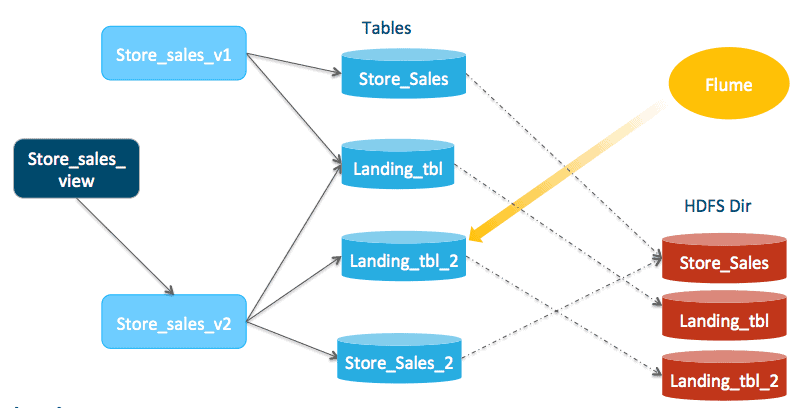
Note on Ingestion and Compaction Frequency
Cloudera recommends a loading frequency of no more than once per minute; a higher frequency could put an excessive load on the Hive metastore and Impala’s catalog service. It will also likely increase compaction frequency, which consumes more system resources.
Usually, the ideal data compaction frequency is once per day. However, right before compaction happens the landing table will have lots of small files, so it’s recommended that you verify that query response time, throughput, and system resource utilization requirements remain satisfied. Otherwise, data compaction might have to happen more frequently.
Conclusion
In this post, we presented a method for continuously loading micro-batches of data into HDFS for use by Impala. As explained in the introduction, this post also highlights a use case for Kudu, which is designed to provide a more elegant solution than the complex approach described here. But in the meantime, this current method should work well.
Alan Choi is a Software Engineer at Cloudera working on Impala. Before joining Cloudera, he worked at Greenplum on the Greenplum-Hadoop integration. Prior to that, Alan worked extensively on PL/SQL and SQL at Oracle.
Updated 12/16/2016 to add clarity to which commands were performed in Hive vs Impala.
Editor's Choice

