

About this Blog
Data Discovery and Exploration (DDE) was recently released in tech preview in Cloudera Data Platform in public cloud. In this blog we will go through the process of indexing data from S3 into Solr in DDE with the help of NiFi in Data Flow. The scenario is the same as it was in the previous blog but the ingest pipeline differs. Spark as the ingest pipeline tool for Search (i.e. Solr) is most commonly used for batch indexing data residing in cloud storage, or if you want to do heavy transformations of the data as a pre-step before sending it to indexing for easy exploration. NiFi (as depicted in this blog) is used for real time and often voluminous incoming event streams that need to be explorable (e.g. logs, twitter feeds, file appends etc).
Our ambition is not to use any terminal or a single shell command to achieve this. We have a UI tool for every step we need to take.
Assumptions
The prerequisites to pull this feat are pretty similar to the ones in our previous blog post, minus the command line access:
- You have a CDP account already and have power user or admin rights for the environment in which you plan to spin up the services.
If you do not have a CDP AWS account, please contact your favorite Cloudera representative, or sign up for a CDP trial here. - You have environments and identities mapped and configured. More explicitly, all you need is to have the mapping of the CDP User to an AWS Role which grants access to the specific S3 bucket you want to read from (and write to).
- You have a workload (FreeIPA) password already set.
- You have DDE and Flow Management Data Hub clusters running in your environment. You can also find more information about using templates in CDP Data Hub here.
- You have AWS credentials to be able to access an S3 bucket from Nifi. Here is documentation on how to acquire AWS credentials and how to create a bucket and upload files to it.
- You have a sample file in an S3 bucket that is accessible for your CDP user.
- If you don’t have a sample file, here is a link to the one we used.
Note: the workflow discussed in this blog was written with the linked ‘films.csv’ file in mind. If you use a different one, you might need to do things slightly differently, e.g. when creating the Solr collection)
Pro Tip for the novice user: to download a CSV file from GitHub, view it by clicking the RAW button and then use the Save As option in the browser File menu.
- If you don’t have a sample file, here is a link to the one we used.
Workflow
To replicate what we did, you need to do the following:
- Create a collection using Hue.
- Build a dataflow in NiFi.
- Run the NiFi flow.
- Check if everything went well NiFi logs and see the indexed data on Hue.
Create a collection using Hue
You can create a collection using the solrctrl CLI. Here we chose to use HUE in the DDE Data Hub cluster:
1.In the Services section of the DDE cluster details page, click the Hue shortcut.

2. On the Hue webUI select Indexes> + ‘Create index’ > from the Type drop down select ‘Manually’> Click Next.
3. Provide a collection Name under Destination (in this example, we named it ‘solr-nifi-demo’).
4. Add the following Fields, using the + Add Field button:
| Name | Type |
| name | text_general |
| initial_release_date | date |
5. Click Submit.
6. To check that the collection has indeed been created, go to the Solr webUI by clicking the Solr Server shortcut on the DDE cluster details page.

7. Once there, you can either click on the Collections sidebar option or click Select an option > in the drop down you will find the collection you have just created (‘solr-nifi-demo’ in our example) > click the collection > click Query > Execute Query.
You should get something very similar:
{ "responseHeader":{ "zkConnected":true, "status":0, "QTime":0, "params":{ "q":"*:*", "doAs":"<querying user>", "_forwardedCount":"1", "_":"1599835760799"}}, "response":{"numFound":0,"start":0,"docs":[] }}
That is, you have successfully created an empty collection.
Build a flow in NiFi

Once you are done with collection creation, move over to Flow management Data Hub cluster.
In the Services section of the Flow Management cluster details page, click the NiFi shortcut.
Add processors
Start adding processors by dragging the ‘Processor’ button to the NiFi canvas.

To build the example workflow we did, add the following processors:
1. ListS3
This processor reads the content of the S3 bucket linked to your environment.
Configuration:
| Config name | Config value | Comments |
| Name | Check for new Input | Optional |
| Bucket | nifi-solr-demo | The S3 bucket where you uploaded your sample file |
| Access Key ID | <my access key> | This value is generated for AWS users. You may generate and download a new one from AWS Management Console > Services > IAM > Users > Select your user > Security credentials > Create access key. |
| Secret Access Key | <my secret access key> | This value is generated for AWS users, together with the Access Key ID. |
| Prefix | input-data/ | The folder inside the bucket where the input CSV is located. Be careful of the “/” at the end. It is required to make this work. |
You may need to fill in or change additional properties beside these such as region, scheduling etc. (Based on your preferences and your AWS configuration)
This processor filters objects read in the previous step, and makes sure only CSV files reach the next processor.
Configuration:
| Config name | Config value | Comments |
| Name | Filter CSVs | Optional |
| csv_file | ${filename:toUpper():endsWith(‘CSV’)} | This attribute is added with the ‘Add Property’ option. The routing will be based on this property. See in the connections section. |
FetchS3 object reads the content of the CSV files it receives.
Configuration
| Config name | Config value | Comments |
| Name | Fetch CSV from S3 | Optional |
| Bucket | nifi-solr-demo | The same as provided for the ListS3 processor |
| Object Key | ${filename} | It’s coming from the Flow File |
| Access Key ID | <My Access Key Id> | The same as provided for the ListS3 processor |
| Secret Access Key | <My Secret Access Key> | The same as provided for the ListS3 processor |
The values for Bucket, Access Key, and Secret Key are the same as in case of the List3 processor. The Object key is autofilled by NiFi, It comes as an input from the previous processors.
Configuration
| Config name | Config value | Comments |
| Name | Index Data to DDE | Optional |
| Solr Type | Cloud | We will provide ZK ensemble as Solr location so this is required to be set to Cloud. |
| Solr Location | <ZK_ENSEMBLE> | You find this value on the Dashboard of the Solr webUI, as the zkHost parameter value. |
| Collection | solr-nifi-demo-collection | Here we use the collection which has been created above. If you specified a different name there then put the same here. |
| Content Stream Path | /update | Be careful of the leading “/”. |
| Content-Type | application/csv | Any content type that Solr can process may be provided here. In this example we use CSV. |
| Kerberos principal | <my kerberos username> | Since we use direct URL to Solr, Kerberos authentication needs to be used here. |
| Kerberos password | <my kerberos password> | Password for the Kerberos principal. |
| SSL Context Service | Default NiFi SSL Context Service | Just choose it from the drop down. The service is created by default from the Workflow Management template. |
5. LogMessage (x4)
We created four LogMessage processors too to track if everything happens as expected.
a) Log Check
| Log message | Object checked out: ${filename} |
b) Log Ignore
| Log message | File is not csv. Ignored: ${filename} |
c) Log Fetch
| Log message | Object fetched: ${filename} |
d) Log Index
| Log message | Data indexed from: ${filename} |
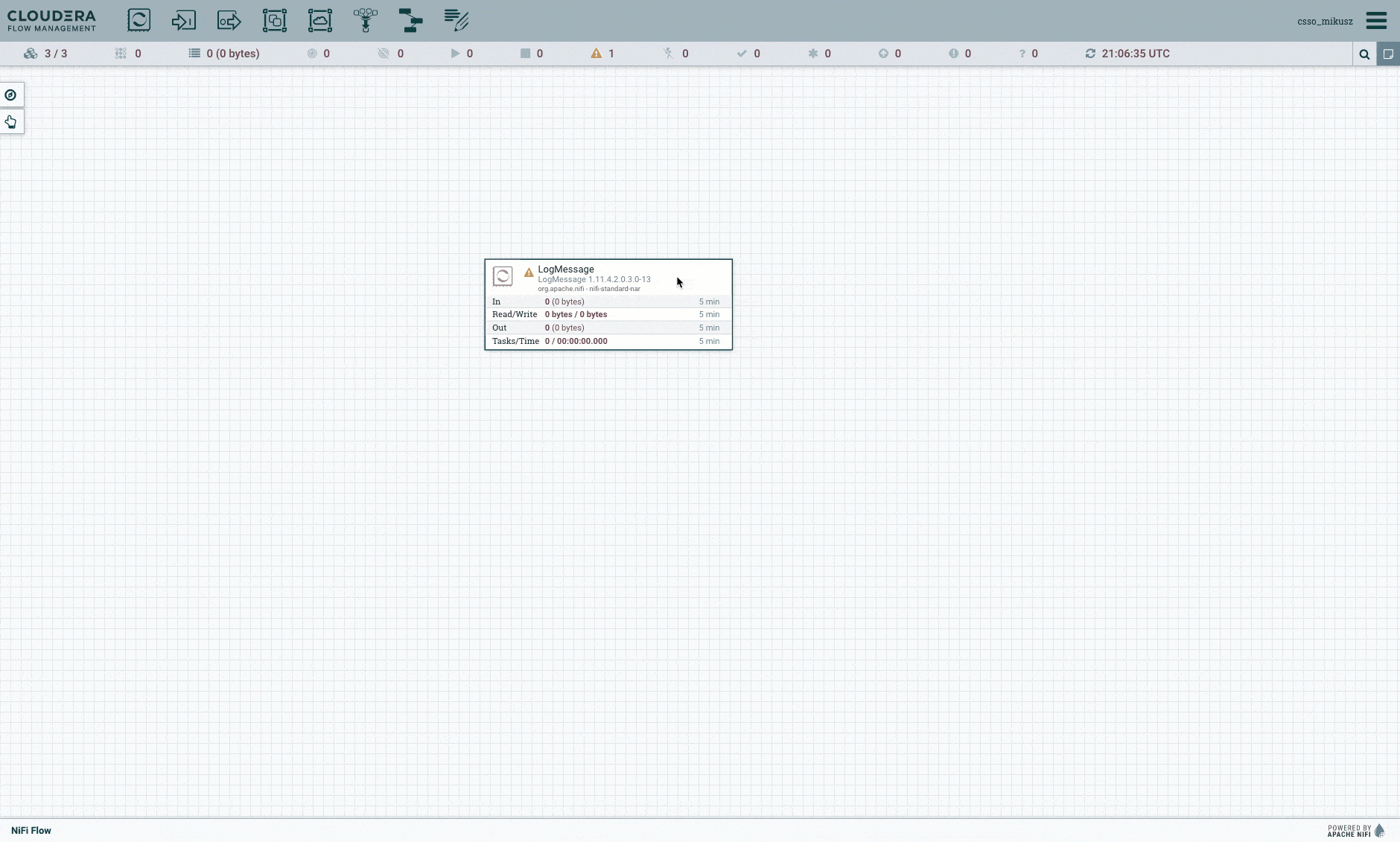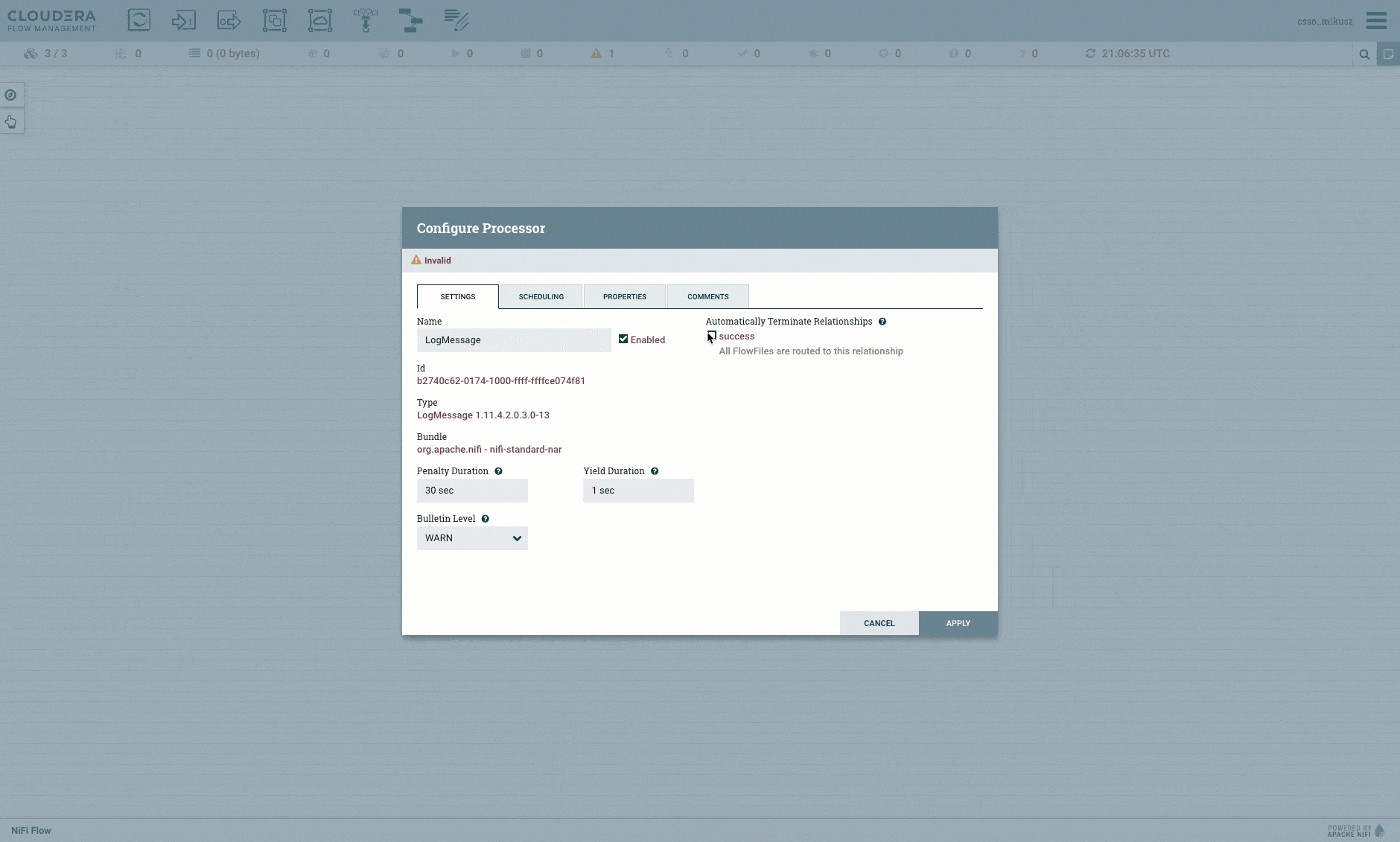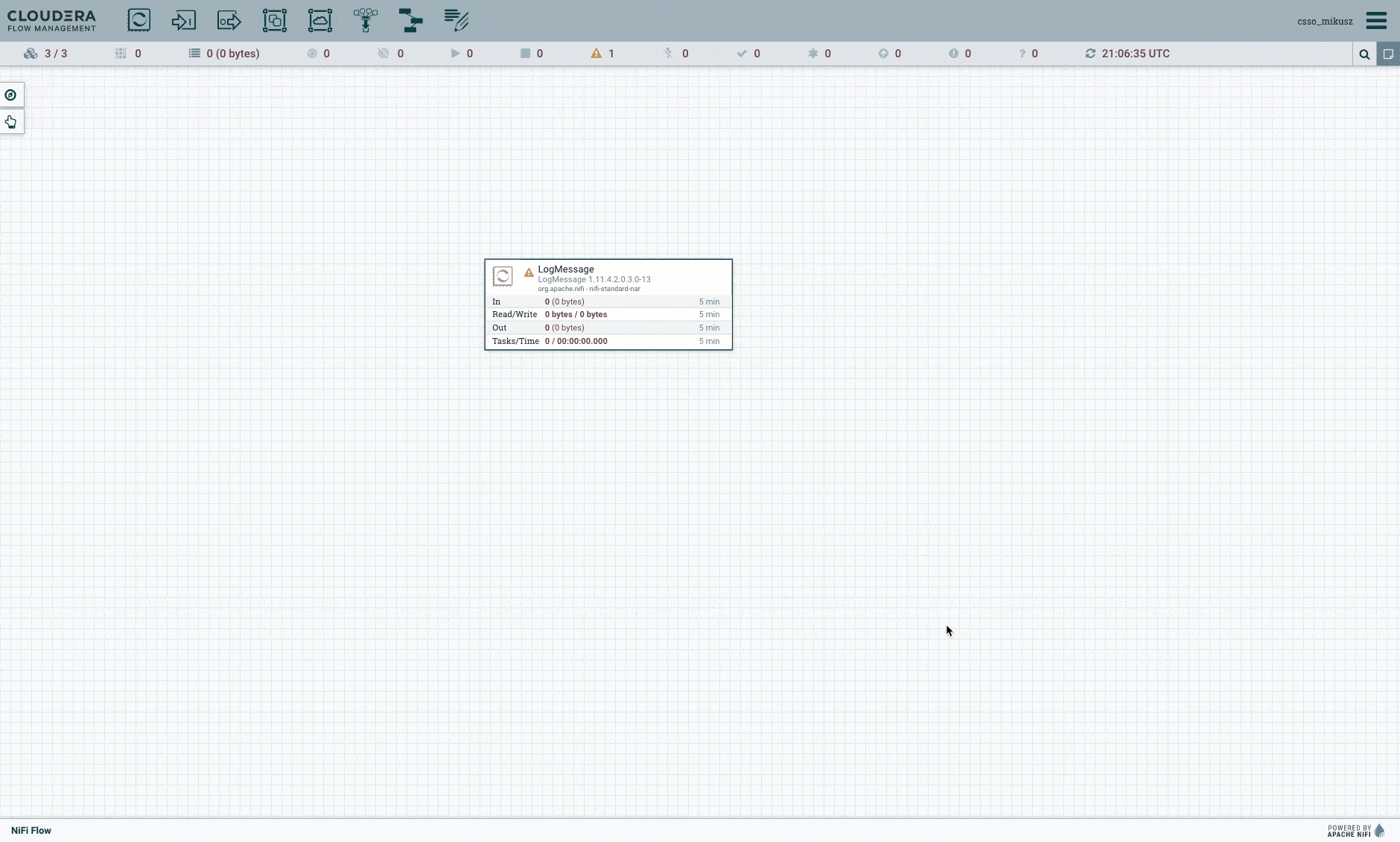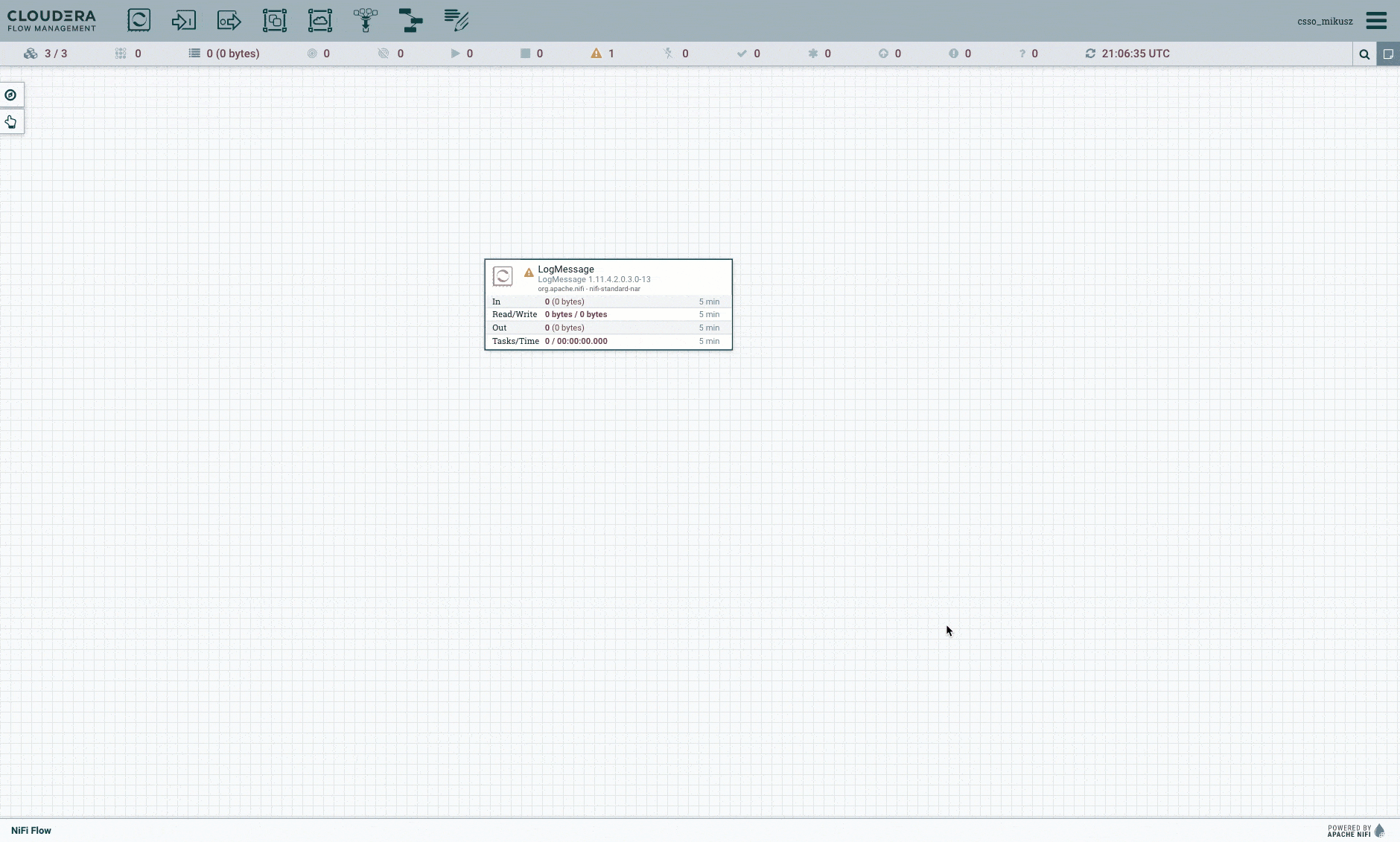
6. In this workflow, the log processors are the dead ends, so pick the “Automatically Terminate Relationships” option on them like this:
In this example, all properties not mentioned above were left with their default values during processor setup. Depending on your AWS and environment setup, you may need to set things differently.
After setting up the processors you shall see something like this:
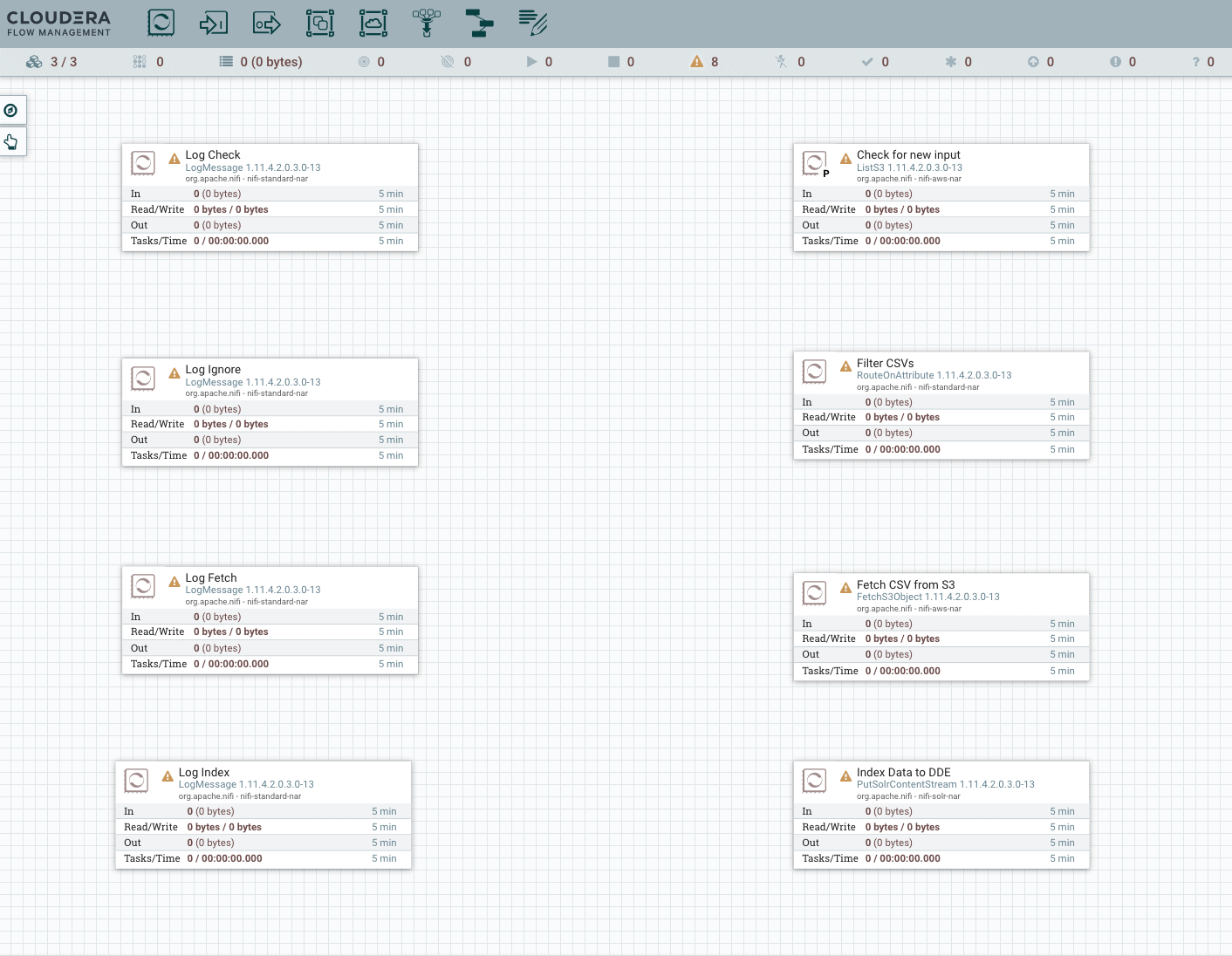
Create connections
Use your mouse to create flow between the processors.
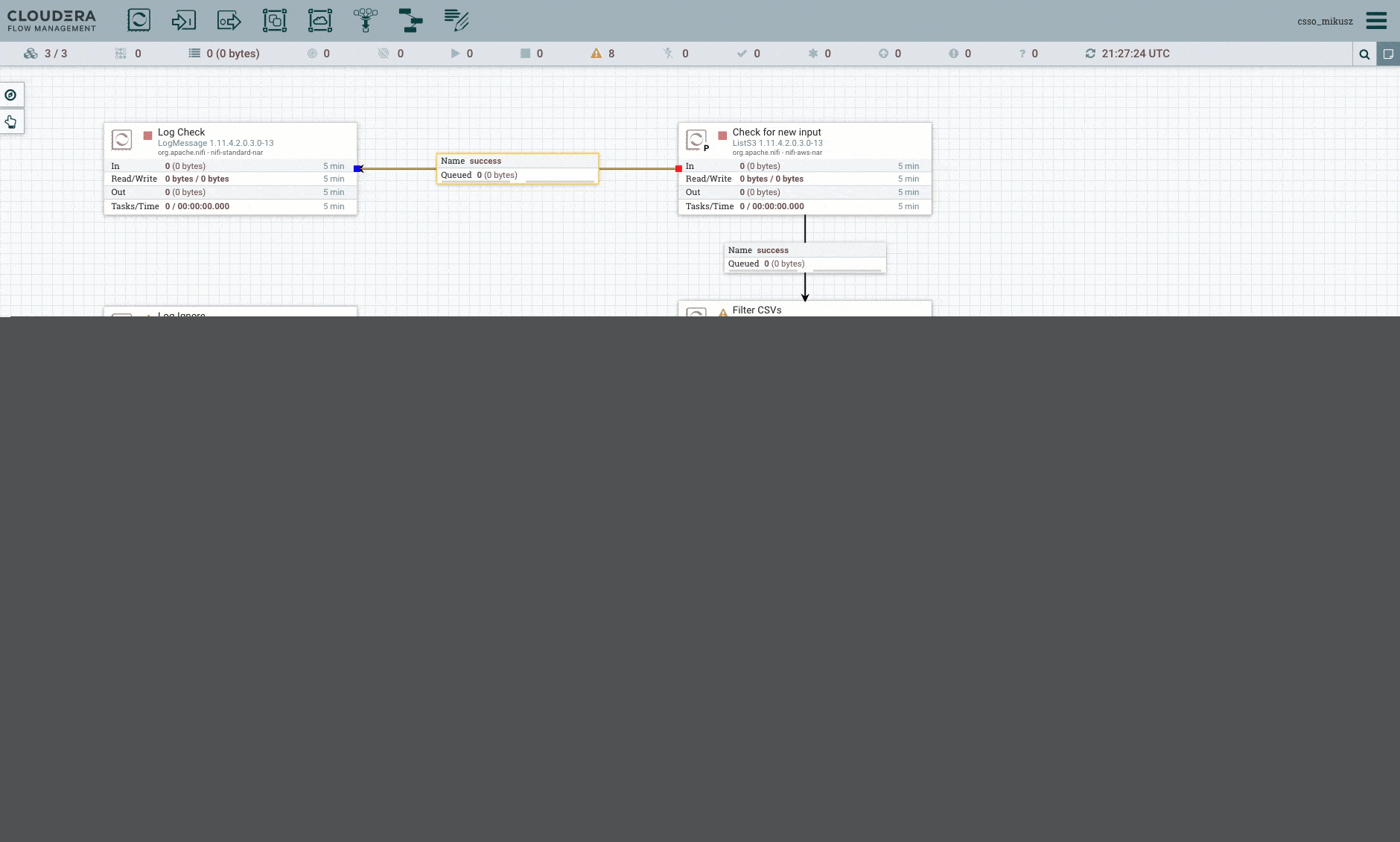
The connections between the boxes are the successful paths, except for the RouteOnAttribute processor: It has the csv_file and the unmatched routes. The FetchS3Object and the PutSolrContentStream processors have failure paths as well: direct them back to themselves, creating a retry mechanism on failure. This may not be the most sophisticated, but it serves its purpose.
This is what your flow will look like after setting the connections:
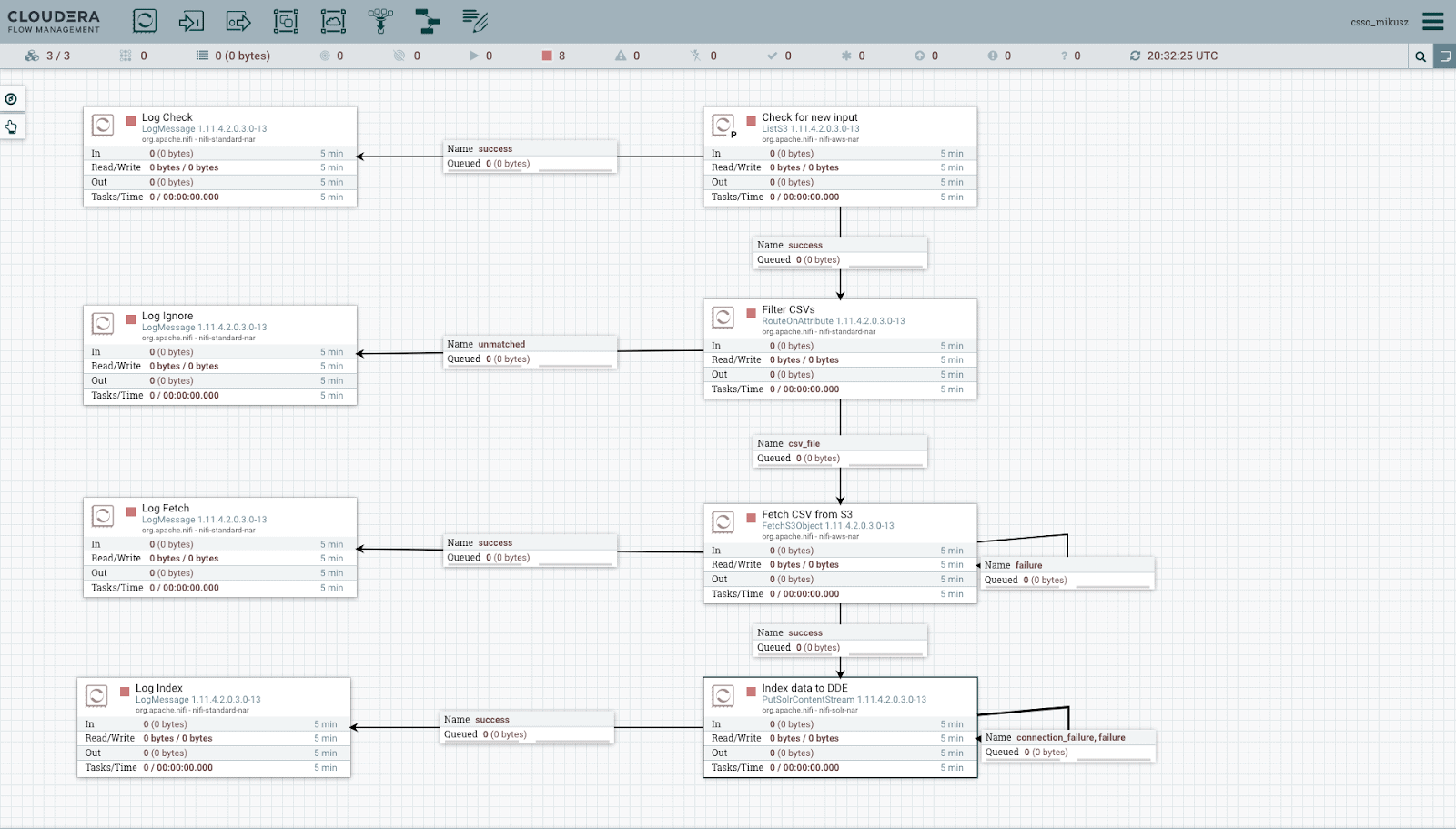
Run the NiFi Flow
You may start the processors one by one, or you may start the entire flow at once. If no processor is selected, by clicking the “Play” icon on the left side in the NiFi Operate Palette starts the flow. If you did the setup exactly as it is in the beginning of this post, two object are almost instantly checked out (depending, of course, on your scheduling settings if you set those too):
- input-data/ – The input folder also matches with the prefix provided for the ListS3 processor. But no worries, as in the next step it will be filtered out so it won’t go further as it’s not a CSV file.
- films.csv – this goes to our collection if you did everything right.
After starting your flow the ListS3 command based on the scheduling polls your S3 bucket and searches for changes based on the “Last modified” timestamp. So if you put something new in your input-data folder it will be automatically processed. Also if a file changes it’s rechecked too.
Check the results
After the CSV has been processed, you can check your logs and collection for the expected result.
Logs
1. In the Services section of the Flow Management cluster details page, click the Cloudera Manager shortcut.

2. Click on the name of your compute cluster >Click NiFi in the Compute Cluster box. > Under Status Summary click NiFi Node > Click on one of the nodes and click Log Files in the top menu bar. > Select Role Log File. If everything went well you will see similar log messages:

Indexed data
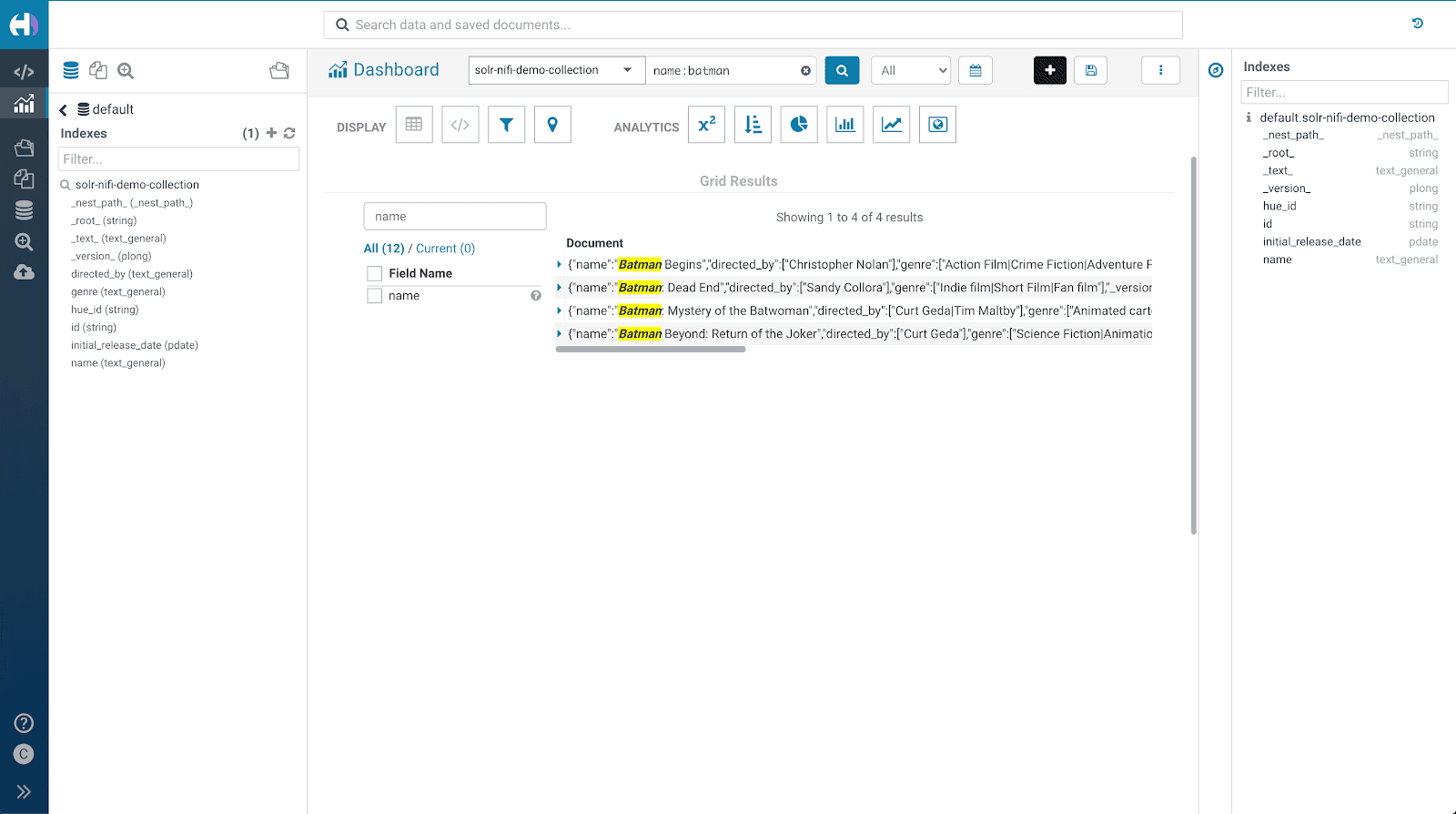
Indexed data appears in our collection.
Here is what you should see on Hue:
Summary
In this post, we demonstrated how Cloudera Data Platform components can collaborate with each other, while still being resource isolated and managed separately. We created a Solr collection via Hue, built a data ingest workflow in NiFi to connect our S3 bucket with Solr, and in the end, we have the indexed data ready for searching. There is no terminal magic in this scenario, we’ve only used comfortable UI features. Having our indexing flow and our Solr sitting in separate clusters, we have more options in areas like scalability, the flexibility of routing, and decorating data pipelines for multiple consuming workloads, and yet with consistent security and governance across. Remember, this was only one simple example. This basic setup, however, offers endless opportunities to implement way more complex solutions. Feel free to try Data Discovery and Exploration in CDP on your own and play around with more advanced pipelines and let us know how it goes! Alternatively, contact us for more information.
Editor's Choice

