

From a-z in 10 minutes!
It is hard to believe if you have had previous experience with setting up, sizing, and deploying a distributed search engine service that this is possible. Imagine how many times IT has lost valuable time spending hours trying to understand Apache Solr application requirements and map them into how to best size and deploy the Solr service. Time that is lost to Line of Business as well.
We wanted to do something about this search-engine deployment-related pain point and created a pre-configured service template to expedite the ditch-rich path of getting to a reliable Solr service, deployed for application developers to start using in just minutes.
What is ‘Data Discovery and Exploration’ in CDP Data Hub?
The Data Discovery and Exploration (DDE) template in CDP Data Hub was released as Tech Preview a few weeks ago. DDE is a new template flavor within CDP Data Hub in Cloudera’s public cloud deployment option (CDP PC). It is designed to simplify deployment, configuration, and serviceability of Solr-based analytics applications. DDE also makes it much easier for application developers or data workers to self-service and get started with building insight applications or exploration services based on text or other unstructured data (i.e. data best served through Apache Solr).
What does DDE entail?
The Data Discovery and Exploration template contains the most commonly used services in search analytics applications. See the snapshot below.

More specifically:
| HDFS | Stores source documents. Solr indexes source documents to make them searchable. Files that support Solr, such as Lucene index files and write-ahead logs, are also stored in HDFS. Using HDFS provides simpler provisioning on a larger base, redundancy, and fault tolerance. With HDFS, Solr servers are essentially stateless, so host failures have minimal consequences. HDFS also provides snapshotting, inter-cluster replication, and disaster recovery. |
| Hue | Includes a drag-n-drop style, GUI-based Search Dashboard Designer. You can use this to build simple dashboards for PoC or other exploratory purposes, out of the box. The dashboard applications in HUE use standard Solr APIs and can interact with data indexed and stored in HDFS. The application provides support for the Solr standard query language and visualization of faceted search functionality.
Hue also has a Index Creation Designer – but we do not recommend using this until after GA. It is under reconstruction at the moment. |
| Knox | Provides perimeter security. Knox is a stateless reverse proxy framework. By encapsulating Kerberos, it eliminates the need for client software or client configuration, simplifying the access model. It intercepts REST/HTTP calls and provides authentication, authorization, audit, URL rewriting, web vulnerability removal and other security services through a series of extensible interceptor pipelines. |
| Solr | Solr is a standard and open source, commonly adopted text search engine with rich query APIs for performing analytics over text and other unstructured data. |
| Spark | The CrunchIndexerTool can use Spark to read data from HDFS files into Apache Solr for indexing, and run the data through a so-called morphline for extraction and transformation in an efficient way. |
| Yarn | YARN allows you to use various data processing engines for batch, interactive, and real-time stream processing of data stored in HDFS or cloud storage like S3 and ADLS. You can use different processing frameworks for different use-cases, for example, you can run Hive for SQL applications, Spark for in-memory applications, and Storm for streaming applications, all on the same Hadoop cluster. |
| ZooKeeper | Coordinates distribution of data and metadata, also known as shards. It provides automatic failover to increase service resiliency. |
In addition, DDE is certified with all Data Hub Flow Management templates in CDP Data Hub, in case you want to ingest data to Solr via NiFi, for instance, useful in cases where events or log data is what you need to make it searchable, in real-time.
Before you Get Started
For the examples presented in this blog, we assume you have a CDP account already. We also require you to have power user or admin rights for the environment in which you plan to spin up this service. We further assume you have environments and identities mapped and configured. More explicitly, all you need is to have the mapping of the CDP User to an AWS Role which grants access to the specific cloud storage location you eventually want to read from (and write to).
Although not elaborated on in this blog post, it is possible to use a CDP Data Hub Data Engineering cluster for pre-processing data via Spark, and then post to Solr on DDE for indexing and serving. It is also possible to use CDP Data Hub Data Flow for real-time events or log data coming in that you want to make searchable via Solr. The advantage of CDP and its separated, yet integrated, architecture is of course that you can scale and maintain every part of the data lifecycle and pipeline with the best-optimized resources and capacity for the task in the workflow at hand.
Get your DDE instance up and running
- Log in to the CDP web interface (i.e. your CDP account, using your account credentials).
- Navigate to the Management Console > Environments > click on an environment where you would like to create a cluster > click Create Data Hub. The following page is displayed:
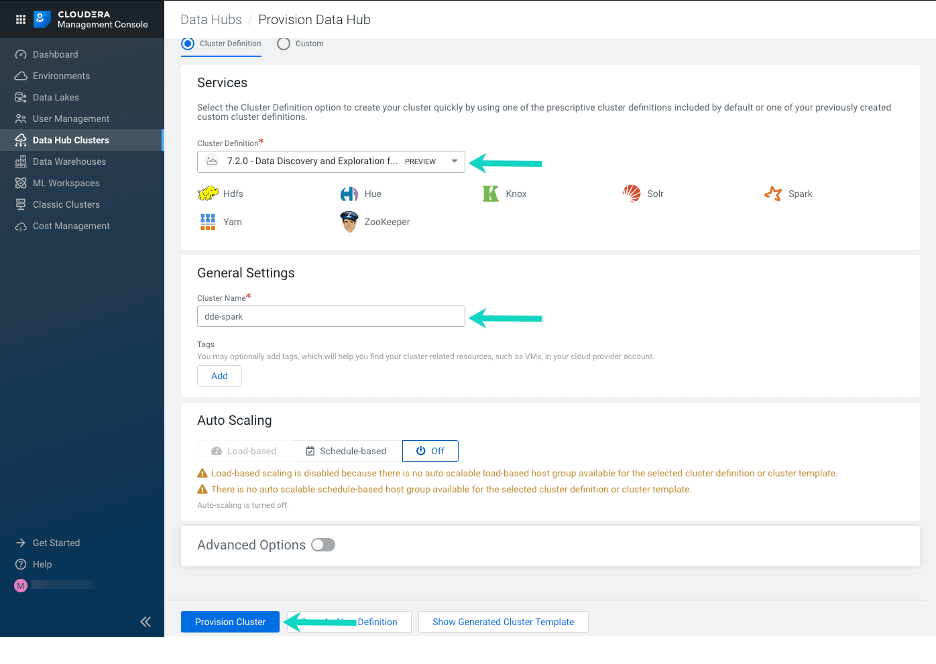
- From the Cluster Definitions dropdown, select ‘Data Discovery and Exploration for AWS – PREVIEW’
- Under General Settings define a cluster name.
- Click Provision Cluster.
If you rather want to create your own cluster definition, you can read how to in our product documentation.
Built-in Cost Efficiency
The advantage with cloud is of course the transient allocation of resources. If you want to save service costs or serve temporary projects more easily without impacting data centers or existing production capacity you can with the simplification of DDE. If your Solr service does not require 24/7 service uptime, you can suspend your DDE cluster by simply stopping it. Now this means that no new data will be indexed in the cluster during the downtime, but you also won’t incur any costs.
Stopping the DDE cluster
If you want to temporarily stop the DDE cluster you need to:
- Navigate to Management Console > Data Hub Clusters > Click on your DDE cluster.
- Click Stop.

NOTE: Stopping the DDE cluster may result in external services that rely on one or more services within the cluster failing. For this reason, shut your DDE cluster down only if you are positive there are no other clusters that depend on it.
Resuming the DDE cluster
Resuming a cluster is just as simple as stopping it:
- Navigate to Management Console > Data Hub Clusters > Click on your DDE cluster.
- Click Start.

The status of the cluster changes to Start in Progress. Once the status is promoted to Running, you may resume using your cluster.
Permanently Delete
In some cases it may make more sense to ‘DELETE’ your DDE cluster entirely.
- Navigate to Management Console > Data Hub Clusters > Click on your DDE cluster.
- Click Actions>Delete.
- Click Yes.
Back up and Restore your Collections
If you intend to revisit the indexed data at a later point in time, before you delete the cluster, you should backup your existing indexes to S3 or ADLS, so you can reload them to a new DDE cluster at a later time. This is not currently automatic in the tech preview, so you have to remember to do this yourself.
Prerequisites
You need to configure the backup repository in solr xml to point to your cloud storage location (in this example your S3 bucket).
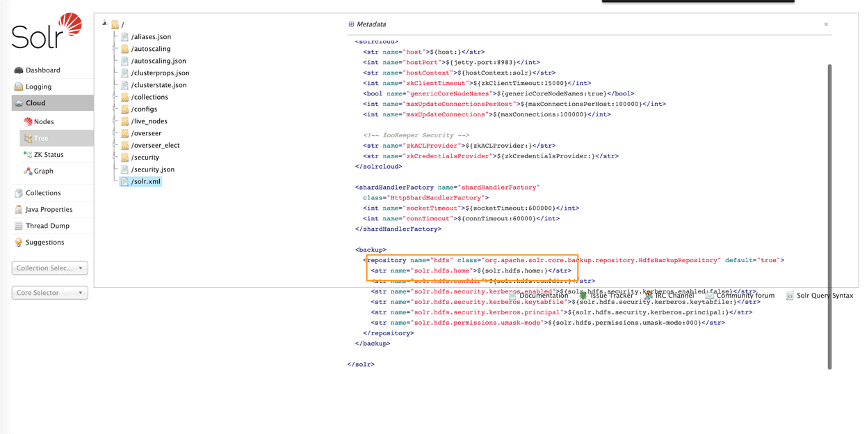
The solr.hdfs.home of the hdfs backup repository must be set to the bucket we want to place the snapshots. In this example: s3a://dde-bucket
Backup a collection
Create a backup directory:
mkdir backups aws s3 cp --recursive backups/ s3://dde-bucket/backups/
Create a snapshot of your collection:
solrctl collection --create-snapshot my-snap -c my-own-logs
Export the snapshot to S3:
solrctl collection --export-snapshot my-snap -c my-own-logs -d s3://dde-bucket/backups/
(Optional) After exporting a snapshot it can be deleted from hdfs:
solrctl collection --delete-snapshot my-snap -c my-own-logs
Restore a collection
If you later want to restore a collection from cloud storage (in this case S3), you can do the following:
solrctl collection --restore books_restored -l s3a://dde-bucket/backups -b my-snap -i req_0
-i option is not required but if specified the request status can be checked after executing the command
solrctl collection --request-status req_0
Summary
We hope you are as excited about our new DDE template in CDP Data Hub as we are and will try how easy it is to spin up your own cluster in CDP (in Azure or AWS) and start playing with discovering data in cloud storage. We also hope that you are very successful in your continued journey on building powerful insight applications involving text and other unstructured data. Our goal is that the Data Discovery and Exploration template makes the journey 10x easier and faster to get from a to z. Get in touch with your account team directly if you are interested in being part of the tech preview or learning more about this capability. Additionally, we welcome your feedback via the comments section below on what you wish to see in the future.
We hope you enjoyed this blog post and that you no longer have to wait for anyone else to get to those deeper insights or to understand data better – with DDE you can self-service your search analytics application lifecycle!
Editor's Choice

