


Introduction
In the previous blog post we covered the high availability feature of Cloudera Operational Database (COD) in Amazon AWS. Cloudera recently released a new version of COD, which adds HA support to Microsoft Azure-based databases in the Cloud. In this post, we’ll perform a similar test to validate that the feature works as expected in Azure, too. We will not repeat ourselves, so it’s assumed that technologies and concepts like HA, Multi-AZ, and operational databases are already known to the reader through the previous blog post.
Preparation
“Availability zones” in Azure are slightly different from AWS. Unlike in AWS, one cannot just utilize the subnets to assign resources to the availability zone. Virtual networks and subnets are zone redundant in Azure so the availability zone needs to be specified for virtual machines and public IPs to distribute the VMs across availability zones. See Azure availability zones. See Azure zone service and regional support to understand the regions and services that support availability zones.
To use the Multi-AZ feature for every component in the platform, the following prerequisites need to be met:
- Azure PostgreSQL Flexible Server: The Azure region that you select should support Azure PostgreSQL Flexible Server and the instance types to be used. See Flexible Server Azure Regions.
- Zone-Redundant Storage (ZRS): The ADLS gen two storage account should be created as zone-redundant storage (ZRS). To specify ZRS via Azure CLI during storage account creation, the –sku option should be set to Standard_ZRS. Below is the Azure CLI command:

Cloudera allows FreeIPA servers, enterprise data lake, and data hub to be configured as Multi-AZ deployment. To set up a Multi-AZ deployment, availability zones need to be configured at the environment level. We can optionally specify an explicit list of availability zones as part of CDP environment creation. If not given, all availability zones, i.e. 1, 2, and 3, will be used.
Below is the CDP CLI command for the same:

For existing environments, we can use CLI to configure a list of AZs. Below is the CLI command:

The list of configured availability zones can be verified on the summary page for the environment on CDP UI:

We can also update the list of availability zones via CDP UI. While updating the list of availability zones for an environment, it can only be extended, which means we cannot remove the availability zones.
To configure FreeIPA as Multi-AZ, it needs to be specified as part of environment creation via CLI or GUI. Below is the CLI command:

To configure the data lake as Multi-AZ, it needs to be specified as part of data lake creation via CLI or GUI. Below is the CLI command:

Note: Only enterprise data lake can be configured as Multi-AZ.
For the Multi-AZ data lake, nodes for each instance group will be distributed across configured availability zones. This can be verified by looking at nodes on CDP UI as shown below for the core host group:
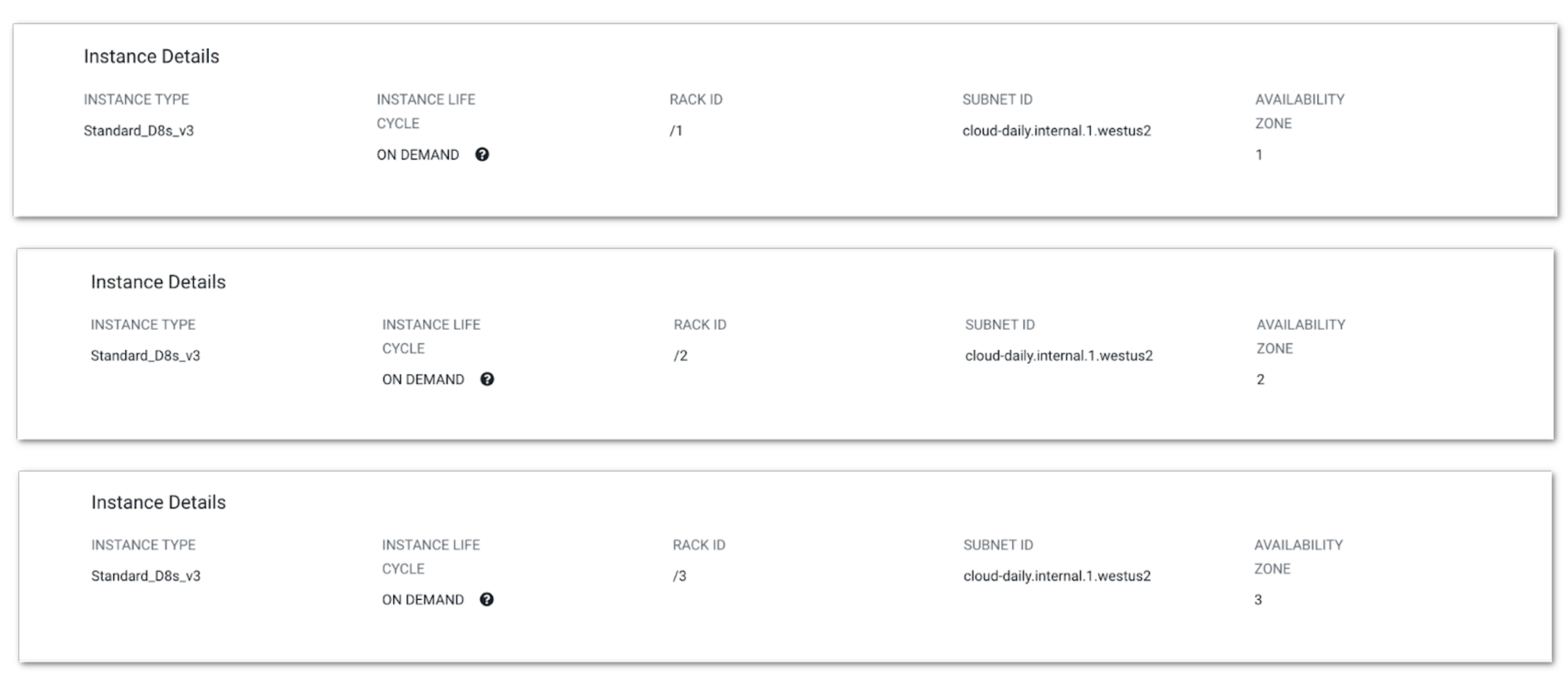
Multi-AZ data lake will also use Postgres Flexible Server since it supports HA.
In addition to the Multi-AZ option, we can also specify the list of AZs for specific instance groups if needed. The list of availability zones for specific instances needs to be a subset of AZs configured at the environment level. If not specified, AZs configured for the environment will be used. For the Multi-AZ data hub, nodes for each instance group will be distributed across configured availability zones for the instance group. This can be verified by looking at nodes on CDP UI.
To create a Multi-AZ COD cluster, use the following CLI command:

COD automates the data hub creation completely: assuming we already have the required entitlements in COD, we can just create a new database that will be automatically allocated to all available AZs. Our test cluster has been created with the light duty option, meaning it has nine nodes (two masters, one leader, one gateway, and five workers) accommodated in three AZs. Pop the hood and see what it looks like in Azure portal:
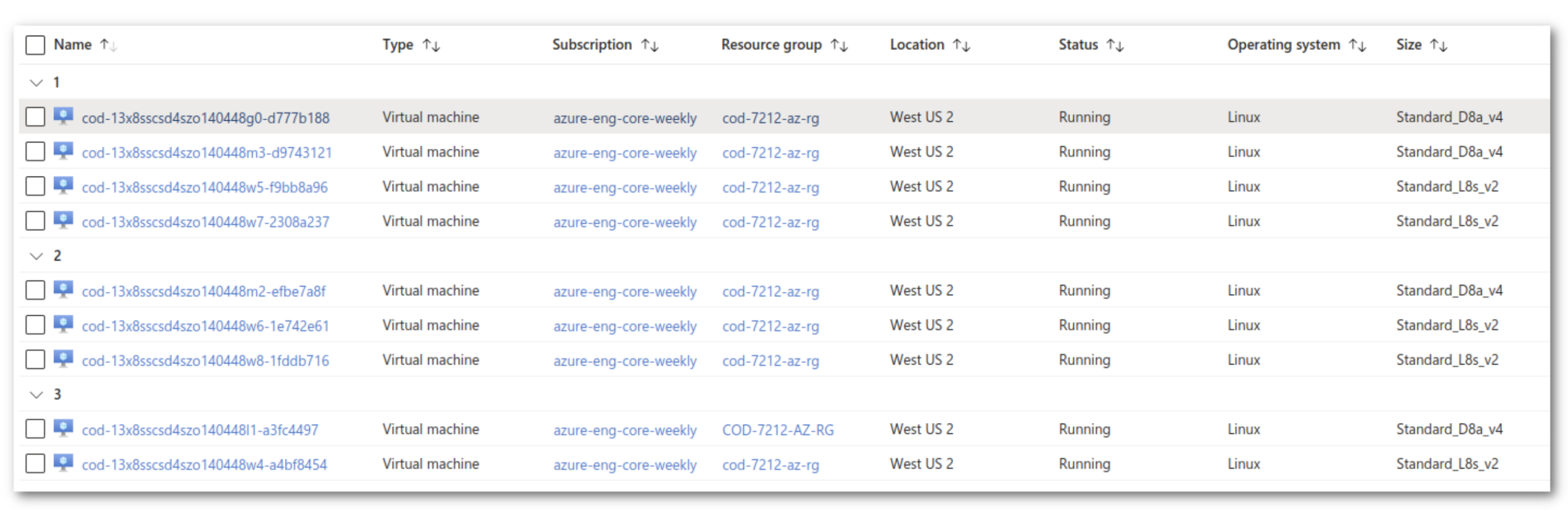
Names of virtual machines are a bit cryptic. The allocation looks like this:
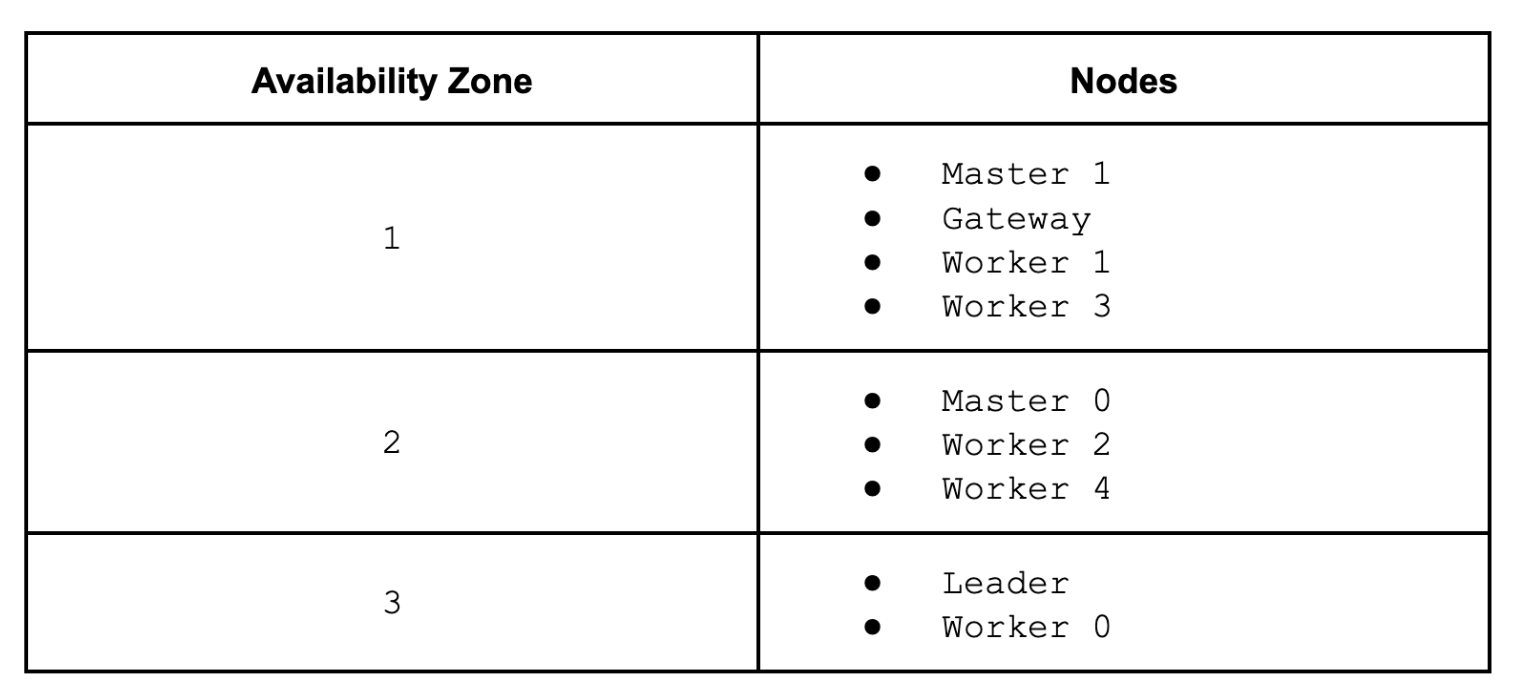
In the simulation we’re going to stop virtual machines in AZ number 2, which will also bring down the HBase active master (master 0), so the backup master (master 1) has to take over the role. The way we do the simulation is different from the AWS test case because we cannot define a similar network rule to block the traffic. Instead, we just gracefully stop and restart the nodes on Azure portal, but it is still suitable to verify HBase failover behavior.
Test client
We use the same command line to start the standard HBase load test tool as a test client which will send write requests to the cluster while we’re simulating a failure:
hbase ltt -write 10:1024:10 -num_keys 10000000

Demo
COD is showing a green state, so we can start.
First, we stop the virtual machines on the Azure portal screen and see what happens. The client starts to experience the failure at 13:46 with exceptions: timeout, unable to access region, and no route to host errors.

The backup master takes over the master role and finishes the boot process at 13:50. It’s showing we only have three live region servers.

Once RITs (region in transition) processes are finished, the client recovers and starts making progress at 13:52.

The COD console shows we have node failure and the cluster is running on degraded performance.

We restart the nodes now. The client doesn’t experience any change and keeps progressing. Performance is not impacted in this test scenario, because this single client does not put enough load on the five or three workers.
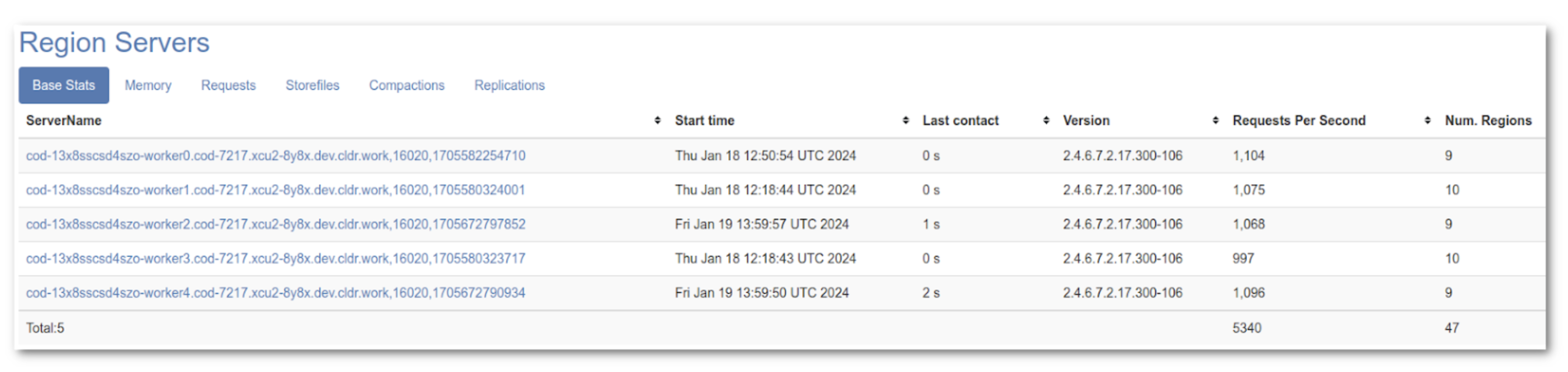
All five region servers have joined the cluster and have started receiving write requests.
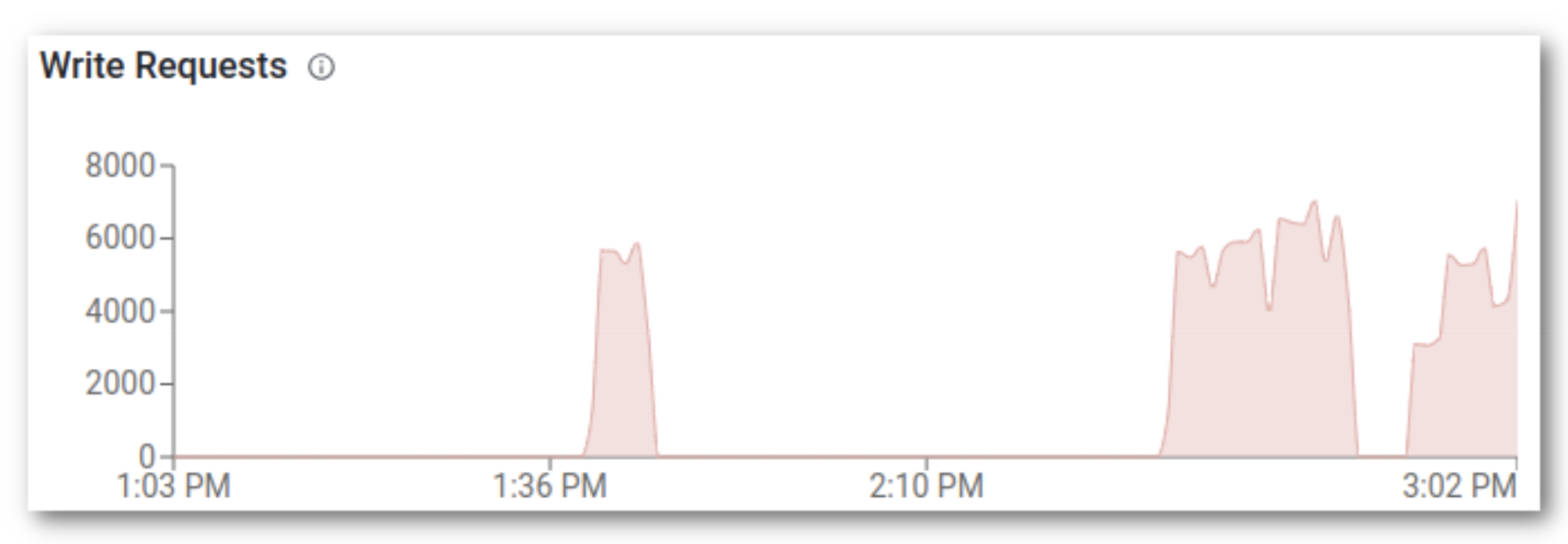
The COD console shows that we’re back in business and had a six-minute outage in write requests.
Summary
In this blog post we simulate an availability zone failure in the Microsoft Azure cloud environment with Cloudera Operation Database service. We’ve confirmed that HBase can detect the failure and recover the service by booting the backup master to take over the master role in a few minutes and transition unavailable regions to live region servers. The client also noticed the failure and experienced a seven to eight minute outage, but after HBase recovered it was able to continue processing without manual intervention.
However, there are a few things to note regarding the test. First, it’s impossible to simulate a real-world AZ outage in any cloud environment. Cloud providers simply don’t support that, unfortunately, so we can only try to approach it as closely as possible. A real-world outage would be different in some regard. For instance, for our simulation we did a graceful stop command on VMs. In a real-world scenario, it could take more time for HBase to detect the failure and recover.
Second, performance is a critical aspect of an operational database and it’s severely impacted by an entire availability zone failure. This must be closely monitored and manually addressed by reducing the load or bringing up new worker nodes in the available regions. COD has the auto-scaling feature that comes to the rescue in a situation like this.
Editor's Choice

