

This blog post was published on Hortonworks.com before the merger with Cloudera. Some links, resources, or references may no longer be accurate.
Overview
As more and more workloads are being brought onto modern hardware in the cloud, it’s important for us to understand how to pick the best databases that can leverage the best hardware. Amazon has introduced instances with directly attached SSD (Solid state drive). Both Apache HBase and Apache Cassandra are popular key-value databases. In this benchmark, we hope to learn more about how they leverage the directly attached SSD in a cloud environment.
Design of the benchmark
The benchmark is designed for running Apache HBase and Apache Cassandra in an optimal production environment. This means using machine tailored for high-io operations with directly attached SSD. We’ve placed write-ahead-logs/commit log as well as data storage on SSDs. Previously, numerous benchmarks have already confirmed both solutions can scale linearly, thus scaling test is out of the scope of this benchmark.
Results
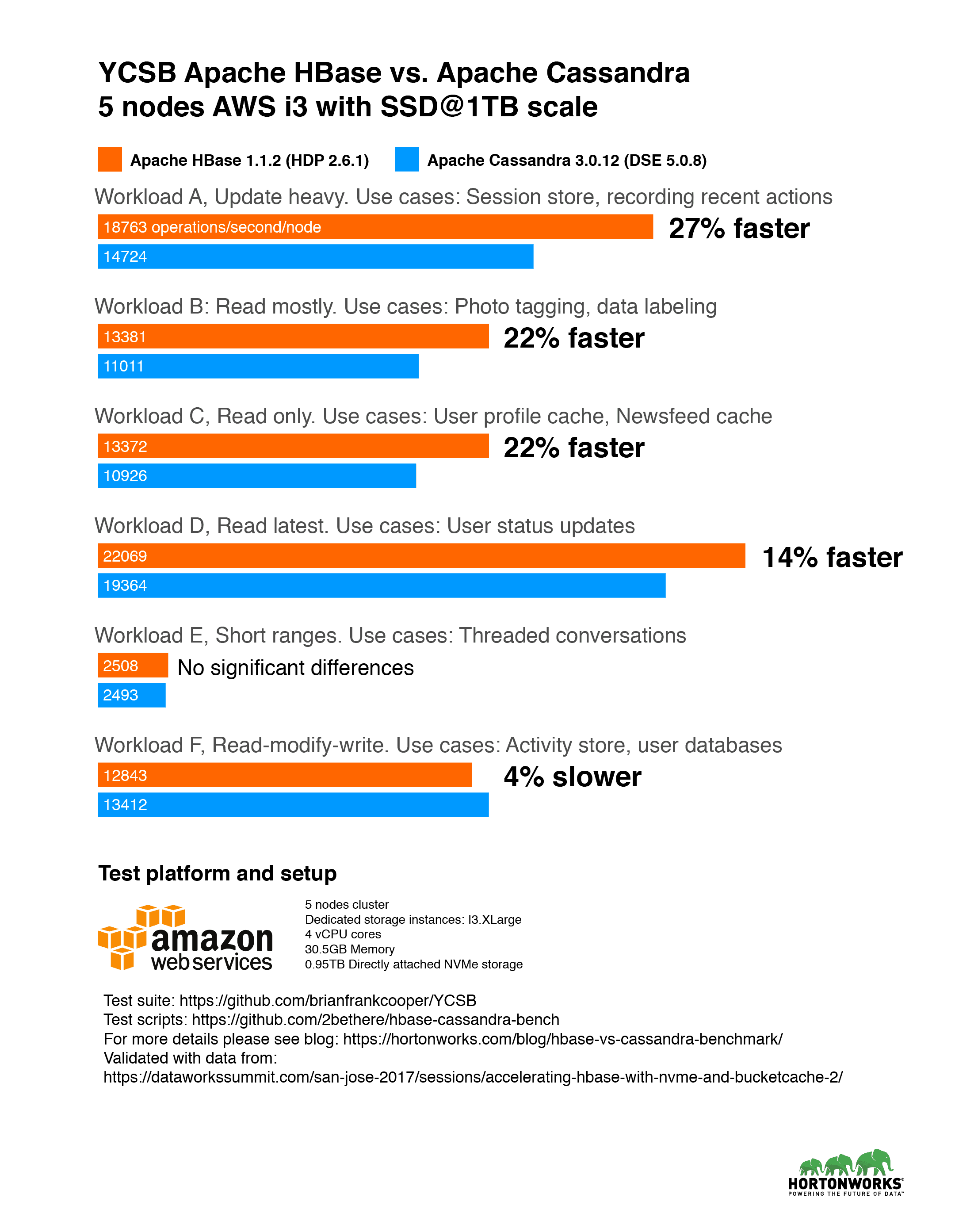
Analysis
Throughout our benchmark, we’ve seen HBase consistently outperforming Cassandra on read-heavy workloads. This aligns well with the key use cases of HBase such as search engines, high-frequency transaction applications, log data analysis and messaging apps. HBase shines at workloads where scanning huge, two-dimensional tables is a requirement. On the other hand, Cassandra worked well on write-heavy workload trading off with consistency. Thus it’s more suitable for analytics data collection or sensor data collection when consistency over time is acceptable.
One other factor to consider when picking solutions is also whether there are corresponding toolsets for analyzing the data. In the case of HBase, being built on top of Apache Hadoop platform, it supports Map Reduce and a variety of connectors to other solutions such as Apache Hive and Apache Spark to enable larger aggregation queries and complex analytics.
Test setup
Machine:
The test cluster consists of 5 machines. Machine details:
AWS I3.xlarge
60GB GP2 to run OS
Directly attached NVMe storage, 0.95TB
4 vCPU, each vCPU (Virtual CPU) is a hardware hyper-thread on an Intel E5-2686 v4 (Broadwell) processor running at 2.3 GHz.
30.5GB RAM
To minimize noisy neighbor issues, we ran the tests on AWS dedicated instances.
Benchmark software:
Test dataset: 1TB generated via YCSB
Test suite: https://github.com/brianfrankcooper/YCSB
Test script: https://github.com/2bethere/hbase-cassandra-bench
Software and environment:
HDP 2.6.1
DSE 5.0.8
CentOS 7
Java 8
To fully utilize the hardware, we’ve changed Number of Handlers per RegionServer in HBase to 120. All other settings are left as default. Full set of configuration listings are available at the end of this post.
During deployment, we also followed the Cassandra optimization guide posted here: http://docs.datastax.com/en/dse/5.1/dse-admin/datastax_enterprise/config/configRecommendedSettings.html
YCSB clients are located on each of the 5 nodes and ran simultaneously to generate the load. During dataset generation, we’ve lowered the thread count to 40.
Test methodology
We are loading the dataset with 40 threads for each workload given the dataset distribution is different for each benchmark. After loading, we wait for all compaction operations to finish before starting workload test. Each workload was run 3 times with 5,000,000 operations. The average number is taken from 3 tests to produce the final number.
About YCSB
YCSB, or Yahoo! Cloud Serving Benchmark is a commonly used benchmark tool. It provides comparative results across different solutions. We’ve run the default workload provided by YCSB.
Workload A: Update heavy
Application example: Session store, recording recent actions
Workload B: Read mostly
Application example: Photo tagging; add a tag is an update, but most operations are to read tags
Workload C: Read only
Application example: user profile cache, where profiles are constructed elsewhere (e.g., Hadoop)
Workload D: Read latest workload
Application example: User status updates; people want to read the latest info
Workload E: Short ranges
Application example: threaded conversations, where each scan is for the posts in a given thread (assumed to be clustered by thread id)
Workload F: Read-modify-write workload
Application example: user database, where user records are read and modified by the user or to record user activity.
Editor's Choice

