

This blog was originally published on Medium
The Data Cloud — Powered By Hadoop
One key aspect of the Cloudera Data Platform (CDP), which is just beginning to be understood, is how much of a recombinant-evolution it represents, from an architectural standpoint, vis-à-vis Hadoop in its first decade. I’ve been having a blast showing CDP to customers over the past few months and the response has been nothing short of phenomenal…
Through these discussions, I see that the natural proclivity is to imagine that CDP is just another “distro” (i.e. “unity distro”) of the two-parent distros (CDH & HDP). To some extent, that is true: we had to pick one (e.g. as we did with Ranger) or use both (Hive-LLAP/Impala or Atlas/Navigator) as appropriate. However, in many ways, it couldn’t be further from the truth. Some folks (staring at you: Andrew Brust) are already there, but the understanding of the present and clear future is unevenly distributed! 🙂
I thought it would be helpful to lay it all down and chart the evolution to get a better feel for where the community is taking the ecosystem. Buckle-up!
Philosophically Speaking…
Let’s take a moment to recap my previous post on the topic to get our bearings… Hadoop, to me personally, has been the result of a philosophy towards a modern architecture for managing and analyzing data based on the following tenets:
- Disaggregate the software stack — storage, compute, security and governance
- Build for extremely large-scale using distributed systems and commodity infrastructure
- Leverage open source for open standards and community scale
- Continuously evolve the ecosystem for innovation at every layer, independently
Decade 1 — Hadoop in the Data-Center
In decade-one, the community delivered a data platform which had the following key characteristics based on the frontier of technologies and constraints then:
0. Co-located compute and storage — networking (at scale) was expensive and slow relative to data volumes and caching (RAM & SSDs) being expensive (at scale).
1. Large-scale, multi-tenant clusters as a shared resource with clusters exceeding 5,000 nodes at the high-end with strong focus on resource management across millions of batch applications (YARN) and nascent attempts at providing multi-tenancy for data-warehousing (Hive-LLAP/Impala), serving (HBase) etc.
2. Software to be downloaded and used on shared clusters.
3. In on-prem deployments, enterprises were able to use approaches like network perimeter security and physical access control as the key pillars of security. In many cases, customers found such simplistic security enforcement to be sufficient and prioritized simplicity of deployment over more robust security mechanisms.
Thus, the architecture of Hadoop deployments had the following feel:
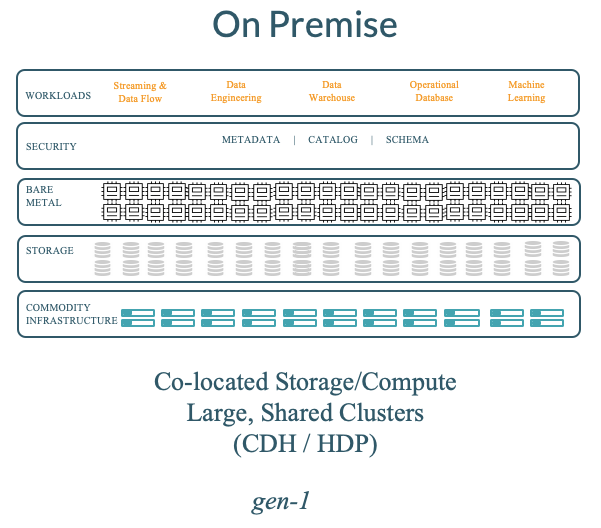
The big, unfortunate, side-effect of the above was the complexity of upgrading the cluster:
- Large, shared clusters with shrink-wrapped software meant that the upgrade was a big-bang i.e. every tenant had to upgrade at the same time and the exposure was very broad.
- The organizational effort to coordinate the upgrade across hundreds of tenants and thousands of applications was extremely high.
- The co-located architecture didn’t distinguish between upgrades of the storage layer (risk) and the compute layer (coordination).
Decade 1 — Hadoop in the Public Cloud
What was then state-of-the-art got adopted to the public cloud (Amazon EMR, Microsoft HDInsight etc.) in the following manner for a first-generation architecture:
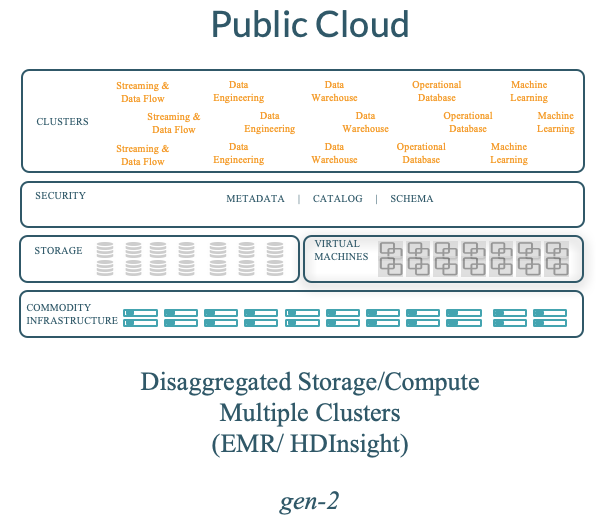
- Leveraged cloud object stores were decoupled from compute. The community built connectors to S3, WASB etc. using the Hadoop Compatible FileSystem (HCFS) APIs.
- Used VMs to spin up compute-only Hadoop clusters which were largely ephemeral; however, the relatively high overhead of spinning up VMs themselves (nearly 10 mins) led to the need to keep clusters up-and-running — an expensive proposition.
- With the ephemerality of compute clusters, there wasn’t a good way to manage long-lived metadata, security policies etc. which also led to expensive long-running clusters.
Decade 2 — Hadoop Powered Data Clouds
By the end of the first decade, we needed a fundamental rethink — not just for the public cloud, but also for on-premises. It’s also helpful to cast an eye on the various technological forces driving Hadoop’s evolution over the next decade:
- Cloud experiences fundamentally changed expectations for easy to use, self-service, on-demand, elastic consumption of software and apps as services.
- Separation of compute and storage is now practical in both public and private clouds, significantly increasing workload performance.
- Containers and kubernetes are ubiquitous as a standard operating environment that is more flexible and agile.
- The integration of streaming, analytics and machine learning — the data lifecycle — is recognized as a prerequisite for nearly every data-driven business use case.
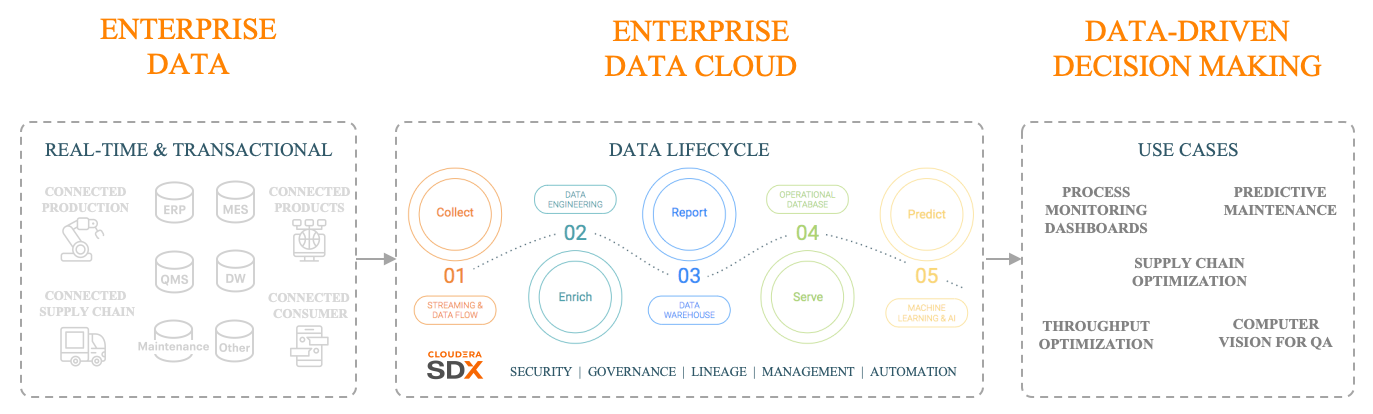
With the above context, here is what the architecture of the platform has shaped up to be for decade two:

0. Disaggregated storage, metadata/security/governance and compute layers. In particular, the ever widening use of RAM and SSDs for relatively cheap caching means that we can provide interactive performance even when storage is disaggregated i.e. take compute to storage.
1. Software in a services form-factor, not shrink-wrapped.
2. A new approach to multi-tenancy, driven by the emergence of containers, where every tenant can be provisioned as an isolated private service (e.g. warehouse) and leverage Kubernetes for software management.
3. Extremely strong focus on security across on-premise and public cloud. No more corporate firewalls for hybrid deployments.
4. Increased awareness of data privacy and emergence of stringent regulations (GDPR/EU, CCPA/California, PDPB/India) led to the requirement of richer governance including lineage, provenance and more across data migration (cloud, on-prem etc.) and the entire lifecycle of data including streaming, data engineering, reporting, predicting and serving.
The new architecture leads to several benefits:
0. Ease of management due to de-coupling of storage/metadata and compute stacks. Even in situations, such as on-premises, where it might make sense to co-locate data and compute for efficiency purposes they are managed independently (at least until the next generation shift of hardware, networks etc.).
1. Ease-of-use due to the strong focus on ‘it’s a service’ — which leads to persona-focused UX for warehousing, machine learning, data engineering, streaming, and data-flow.
2. Faster provisioning with containers and Kubernetes dramatically speeding up provisioning and simplifying management (i.e. eliminates management) of services such as data warehouse, ML, streaming etc.
3. Strong security and governance with SDX across the entire data & analytical life-cycle enabling data-driven decision making.
Existing practitioners have already been asking for improved manageability, more stringent multi-tenancy & isolation capabilities and better security/governance. As a result, helping enterprises understand the above benefits of CDP gets them really excited — not just for CDP on the public cloud but also for CDP in a private cloud form-factor which arrives later this year. It’s an overused term, both the product-market fit for CDP (especially for existing customers who are really looking ahead to CDP Private Cloud) and timing (adoption of Kubernetes, our work with OpenShift RedHat/IBM) and seems extremely timely. Exciting times!
Summary
Here is a quick recap of the evolution of data architectures, powered by Hadoop.
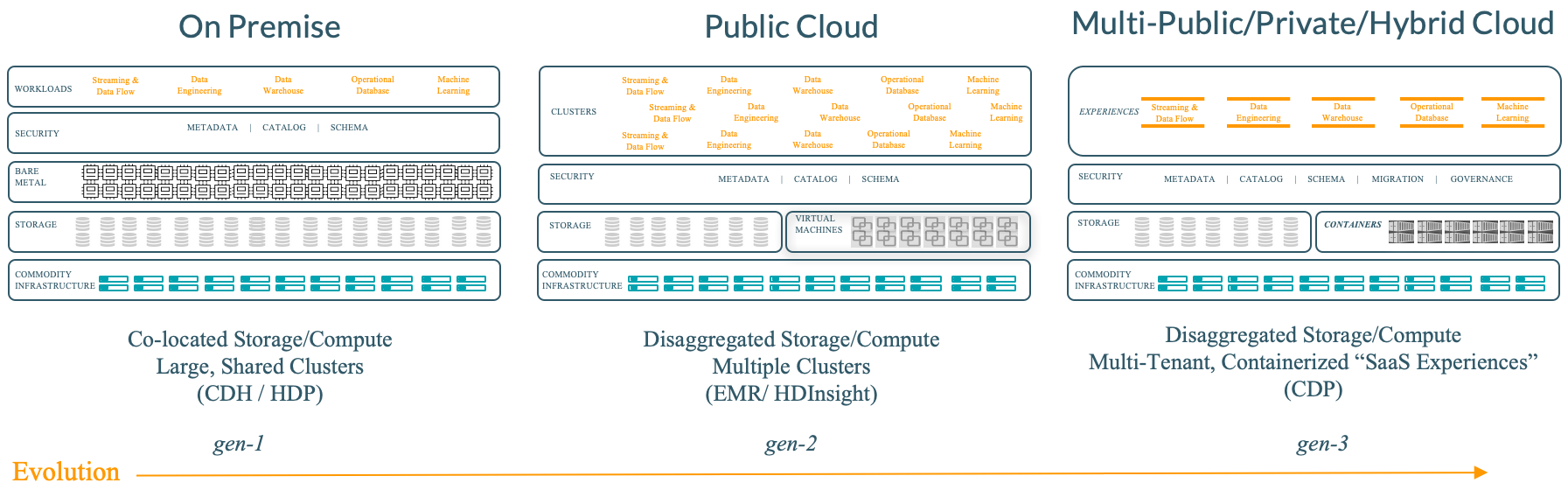
As we enter decade-two, here’s a summary illustrating how architectural considerations are changing with the new reality of managing data and workloads across on-premise, multiple public clouds and hybrid/private cloud,
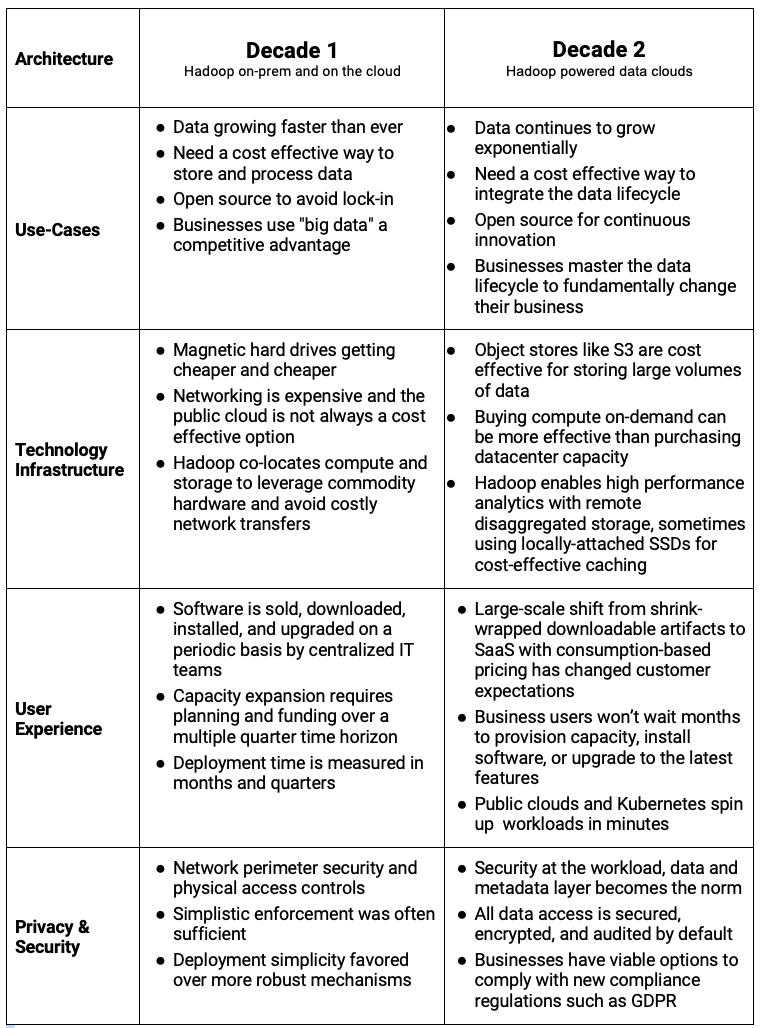
Personally, I’m extremely excited to see how the platform has evolved to meet the needs of business for the coming decade. CDP is the data architecture for the cloud. It delivers a consistently secure and governed data platform to help enterprises control the entire lifecycle of data. And it’s built 100% with Hadoop — the philosophy, of course.
I look forward to this decade’s journey with Hadoop powered data clouds… and beyond!
* I don’t disagree with Bezos on the Day One philosophy, I just can’t help but start the count at 0! 😉
Editor's Choice

