

This blog post was published on Hortonworks.com before the merger with Cloudera. Some links, resources, or references may no longer be accurate.
If you’re interested in learning more, go to our recap blog here!
This blog is also co-authored by Zian Chen and Sunil Govindan from Hortonworks.
Introduction – Apache Hadoop 3.1, YARN, & HDP 3.0
GPUs are increasingly becoming a key tool for many big data applications. Deep-learning / machine learning, data analytics, Genome Sequencing etc all have applications that rely on GPUs for tractable performance. In many cases, GPUs can get up to 10x speedups. And in some reported cases (like this), GPUs can get up to 300x speedups! Many modern deep-learning applications directly build on top of GPU libraries like cuDNN (CUDA Deep Neural Network library). It’s not a stretch to say that many applications like deep-learning cannot live without GPU support.

Without speed up with GPUs, some computations take forever!
(Image from Movie – “Howl’s Moving Castle”)
Starting Apache Hadoop 3.1 and with HDP 3.0, we have a first-class support for operators and admins to be able to configure YARN clusters to schedule and use GPU resources.
Previously, without first-class GPU support, YARN has a not-so-comprehensive story around GPU support. Without this new feature, users have to use node-labels (YARN-796) to partition clusters to make use of GPUs, which simply puts machines equipped GPUs to a different partition and requires jobs to be submitted that need GPUs to the specific partition. For a detailed example of this pattern of GPU usage, see Yahoo!’s blog post about Large Scale Distributed deep-learning on Hadoop Clusters.
Without a native and more comprehensive GPU support, there’s no isolation of GPU resources also! For example, multiple tasks compete for a GPU resource simultaneously which could cause task failures / GPU memory exhaustion, etc.
To this end, the YARN community looked for a comprehensive solution to natively support GPU resources on YARN.
First class GPU support on YARN
GPU scheduling using “extensible resource-types “in YARN
We need to recognize GPU as a resource type when doing scheduling. YARN-3926 extends the YARN resource model to a more flexible model which makes it easier to add new countable resource-types. It also considers the related aspect of “resource profiles” which allow users to easily specify the resources they need for containers. Once we have GPUs type added to YARN, YARN can schedule applications on GPU machines. By specifying the number of requested GPU to containers, YARN can find machines with available GPUs to satisfy container requests.
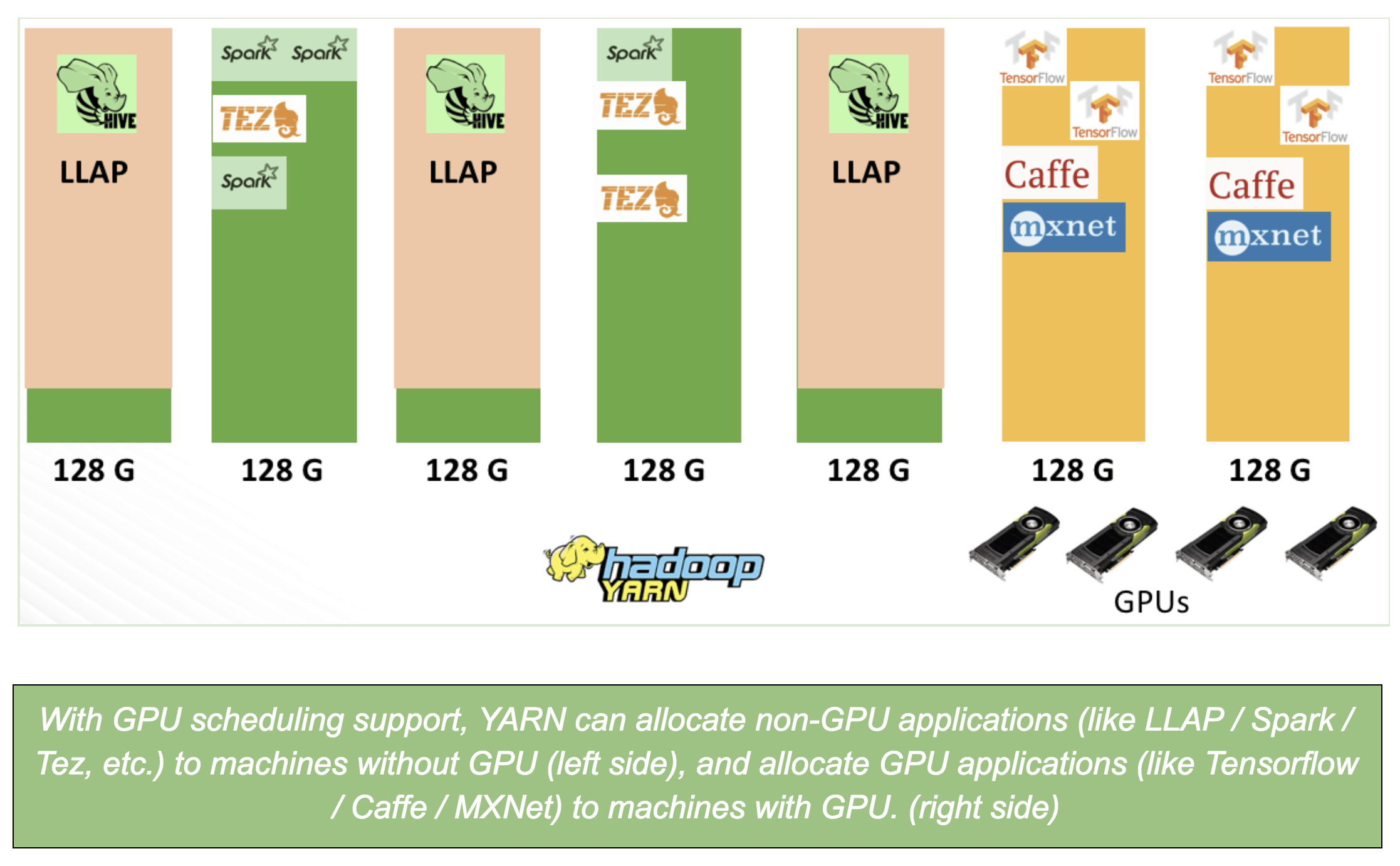
GPU isolation
With GPU scheduling support, containers with GPU request can be placed to machines with enough available GPU resources. We still need to solve the isolation problem: When multiple applications use GPU resources on the same machine, they should not affect each other.
Even if GPU has many cores, there’s no easy isolation story for processes sharing the same GPU. For instance, Nvidia Multi-Process Service (MPS) provides isolation for multiple process access the same GPU, however, it only works for Volta architecture, and MPS is not widely support by deep learning platforms yet. ,So our isolation, for now, is per-GPU device: each container can ask for an integer number of GPU devices along with memory, vcores (for example 4G memory, 4 vcores and 2 GPUs). With this, each application uses their assigned GPUs exclusively.
We use cgroups to enforce the isolation. This works by putting a YARN container – a process tree – into a cgroup that allows access to only the prescribed GPU devices. When Docker containers are used on YARN, nvidia-docker-plugin – an optional plugin that admins have to configure – is used to enforce GPU resource isolation.
GPU discovery
For properly doing scheduling and isolation, we need to know how many GPU devices are available in the system. Admins can configure this manually on a YARN cluster. But it may also be desirable to discover GPU resources through the framework automatically. Currently, we’re using Nvidia system management interface (nvidia-smi) to get number of GPUs in each machine and usages of these GPU devices. An example output of nvidia-smi looks like below:
+-----------------------------------------------------------------------------+ | NVIDIA-SMI 375.66 Driver Version: 375.66 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | |===============================+======================+======================| | 0 Tesla P100-PCIE... Off | 0000:04:00.0 Off | 0 | | N/A 30C P0 24W / 250W | 0MiB / 12193MiB | 0% Default | +-------------------------------+----------------------+----------------------+ | 1 Tesla P100-PCIE... Off | 0000:82:00.0 Off | 0 | | N/A 34C P0 25W / 250W | 0MiB / 12193MiB | 0% Default | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: GPU Memory | | GPU PID Type Process name Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+
Web UI
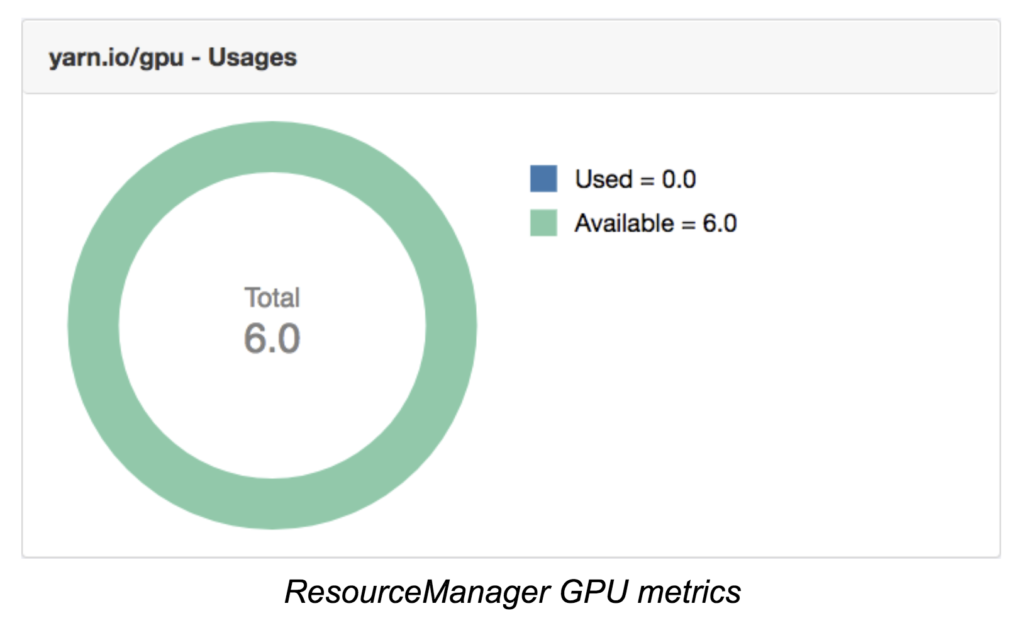
We also added GPU information to the new YARN web UI. On ResourceManager page, we show total used and available GPU resources across the cluster along with other resources like memory / cpu.
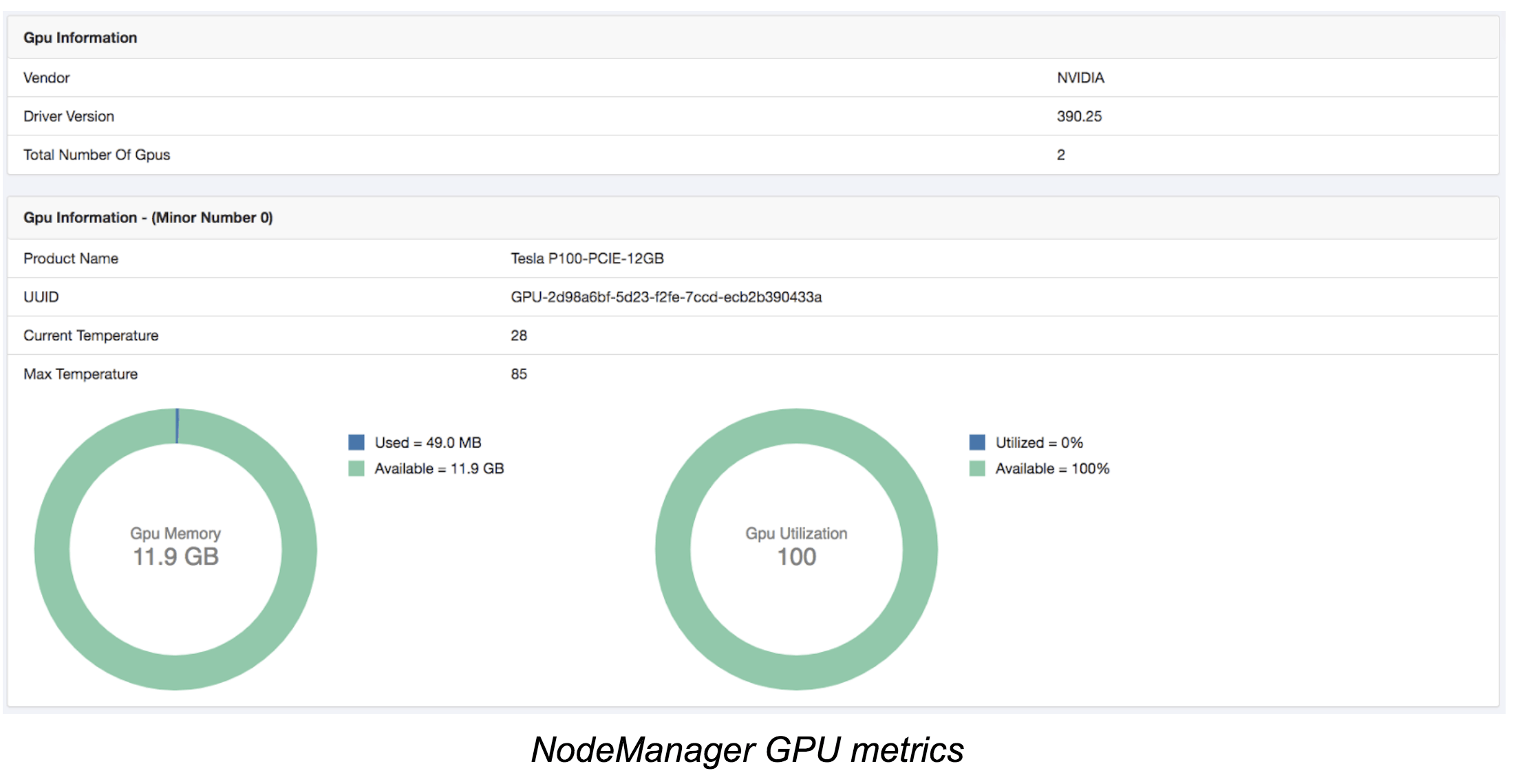
On NodeManager page, YARN shows per-GPU device usage and metrics:
Configurations
To enable GPU support in YARN, administrators need to set configs for GPU Scheduling and GPU isolation.
GPU Scheduling
(1) yarn.resource-types in resource.type.xml
This gives YARN a list of available resource types supported for user to use. We need to add “yarn.io/gpu” here if we want to support GPU as a resource type
(2) yarn.scheduler.capacity.resource-calculator in capacity-scheduler.xml
DominantResourceCalculator MUST be configured to enable GPU scheduling. It has to be set to, org.apache.hadoop.yarn.util.resource.DominantResourceCalculator
GPU Isolation
(1) yarn.nodemanager.resource-plugins in yarn-site.xml
This is to enable GPU isolation module on NodeManager side. By default, YARN will automatically detect and config GPUs when above config is set. It should also add “yarn.io/gpu”
(2) yarn.nodemanager.resource-plugins.gpu.allowed-gpu-devices in yarn-site.xml
Specify GPU devices which can be managed by YARN NodeManager, split by comma Number of GPU devices will be reported to RM to make scheduling decisions. Set to auto (default) to let YARN automatically discover GPU resource from system.
Manually specify GPU devices if auto detect GPU device failed or admin only wants a subset of GPU devices to be managed by YARN. When manually specifying minor numbers, admin needs to include indices of GPUs as well, format is index:minor_number[,index:minor_number…].
(3) yarn.nodemanager.resource-plugins.gpu.path-to-discovery-executables in yarn-site.xml
When yarn.nodemanager.resource.gpu.allowed-gpu-devices=auto is set, YARN NodeManager needs to run GPU-discovery binary (now only support nvidia-smi) to get GPU-related information. When value is empty (default), YARN NodeManager will try to locate discovery executable itself. An example of the config value is: /usr/local/bin/nvidia-smi
(4) yarn.nodemanager.linux-container-executor.cgroups.mount in yarn-site.xml
GPU isolation uses CGroup devices controller to do per-GPU device isolation. Following configs should be set to true to yarn-site.xml to automatically mount CGroup sub-devices, otherwise, admin has to manually create devices subfolder in order to use this feature.
(5) Changes required in container-executor.cfg
[gpu] module.enabled=true [cgroups] # This should be same as # yarn.nodemanager.linux-container-executor.cgroups.mount-path inside yarn-site.xml root=/sys/fs/cgroup # This should be same as yarn.nodemanager.linux-container-executor. # cgroups.hierarchy inside yarn-site.xml yarn-hierarchy=yarn |
For more details about GPU-related configs, please refer to the community documentation.
Auto configure GPUs in Apache Ambari
So far, we just listed some of the most important configuration items needed to be set when a user wants to enable GPU feature support on YARN. Since there are several other configs that need to be set as well, it demands a lot of work for the admin to do manually. Apache Ambari 2.7.0 supports one-click button to enable/disable general GPU scheduling & isolation support as well as GPU support on docker. Through Ambari YARN UI config page, a user just needs to switch two toggle buttons to enable/disable GPU related features. One is called “GPU scheduling & isolation” for general GPU support.

Try it
Once GPU on YARN is configured, the following command can be used to do a smoke test of the feature.
With native YARN container
yarn jar <path/to/hadoop-yarn-applications-distributedshell.jar> \ -jar <path/to/hadoop-yarn-applications-distributedshell.jar> \ -shell_command nvidia-smi \ -container_resources memory-mb=3072,vcores=1,yarn.io/gpu=2 \ -num_containers 2
With Docker YARN container
yarn jar <path/to/hadoop-yarn-applications-distributedshell.jar> \ -jar <path/to/hadoop-yarn-applications-distributedshell.jar> \ -shell_env YARN_CONTAINER_RUNTIME_TYPE=docker \ -shell_env YARN_CONTAINER_RUNTIME_DOCKER_IMAGE=<docker-image-name> \ -shell_command nvidia-smi \ -container_resources memory-mb=3072,vcores=1,yarn.io/gpu=2 \ -num_containers 2
Conclusion
In this post, we have given an overview of YARN’s GPU isolation and scheduling mechanism, how it works and how to config GPU on YARN. For more details, please see the Apache JIRA ticket YARN-6223 (YARN GPU support umbrella). We’re also continuously improving GPU support in YARN. In the near future, we plan to add a few more things. Once YARN-3409 (node attribute) finishes, for heterogeneous GPU cluster which has different types of GPUs in the cluster: YARN can support GPU scheduling with specified GPU types and models. For example, a user can ask GPUs with driver version equaling to 390.25 and GPU model is (Tesla P100) More efforts are in progress. Given that all computation intensive applications can potentially benefit by GPU, so improving GPU support on YARN is always an ongoing effort!
Acknowledgments
We would like to thank all those who contributed patches to GPU on YARN support: Jun Gong, Jonathan Hung (besides the authors of this post). Thanks also to Saumitra Buragohain, Chris Douglas, Subramaniam Krishnan, Arun Suresh, Devaraj K, Zhankun Tang, Zhe Zhang, Keqiu Hu for their help with use cases and reviews! And thanks to Sumana Sathish, Yesha Vora who helped with testing the feature in great detail.
Editor's Choice


This is fantastic job! now the muscle and brains can really combine – good for bigdata + deep learning engineers!