

In recent years, Ethical AI has become an area of increased importance to organisations. Advances in the development and application of Machine Learning (ML) and Deep Learning (DL) algorithms, require greater care to ensure that the ethics embedded in previous rule-based systems are not lost. This has led to Ethical AI being an increasingly popular search term and the subject of many industry analyst reports and papers. However, to understand what Ethical AI is, we need to have at least a basic understanding of ML, ML models and the data science lifecycle and how they are related. This blog post hopes to provide this foundational understanding.
What is Machine Learning
Machine learning is a promising subfield of Artificial Intelligence (AI), where models are not explicitly predefined. Instead, they are learned by training a model on data. Model performance generally improves with access to more data. The model training phase consists of applying a ML algorithm to training data and determining optimal model parameters.

Figure 01: Artificial Intelligence – One Page Summary
ML and the subfield of DL can be applied to a growing number of use cases. These include customer sentiment analysis, predictive maintenance, vehicle autopilot systems, fraud detection and chatbots. Each of these use cases requires solving one or more families of problems. Some of the more common problems include classification, Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs), regression, clustering, reinforcement learning and anomaly detection. Each of these is covered in more detail in this concise cheat-sheet.
What is A Machine Learning Model
A ML model takes input data (text, numbers, images, etc) and outputs data based on the behaviour of what is being modelled to deliver a prediction.
Figure 02: How a ML model works
For example, imagine a model that predicts the expected sale price of a property. A simple model may take inputs such as the property’s location, the number of rooms, the size of the property and output the expected sale value. This is a regression model as the output is a numerical prediction, the expected sale value.
For a model to be classified as a ML model, it must have been created using a ML algorithm and training data. In the case of the property sale price example, we typically follow a supervised learning approach, where the training data contains both the inputs and output values.
The model is trained through an iterative process of comparing some error between what the model predicts (the estimated sale value) and what it actually should be, based on the training data. At each iteration, parameters controlling the model’s behaviour are adjusted to make the next iteration of predictions more accurate.
Model Training as Part of the Data Science Lifecycle
Before an ML model can be trained, data needs to be collected and prepared, often from multiple sources. This may include removing outliers, dealing with missing values and dealing with bias. We also need to understand the domain or context of what is being modelled, and explore the data to look for meaningful distributions and correlations. With this foundational understanding, we then need to evaluate and compare the performance of different ML algorithms, train the best performing model or combine the models in an ensemble. We then deploy the model and measure its ongoing performance. Collectively these stages make up the iterative data science lifecycle as summarised in figure 03 below.
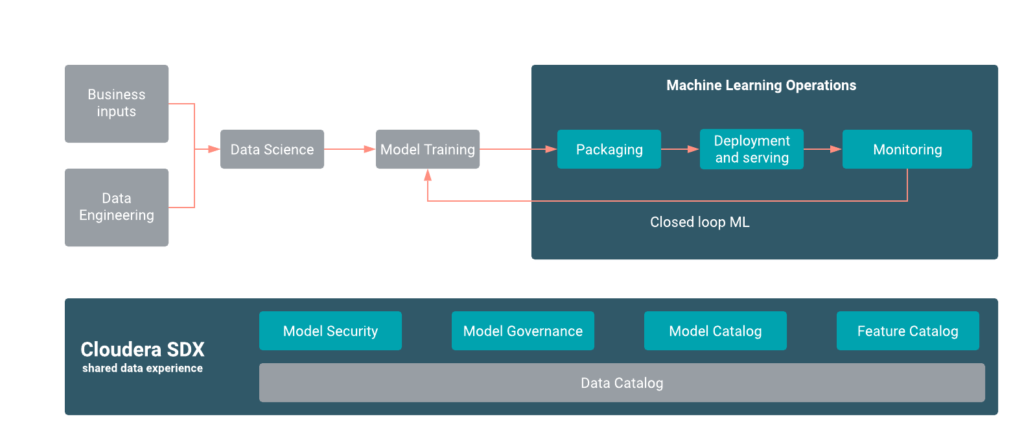
Figure 03: The Data Science Lifecycle
At each stage of the process, if we change the input data, how the data is prepared, the ML algorithm used to build the model or how the model is tuned, the resulting model will almost certainly be different. These activities are generally a function of ML Operations (ML Ops).
If we have a clear and complete picture of each stage of the data science lifecycle for a model, that constitutes the model’s lineage. Over time, as new models are trained, each will have its own unique lineage. Model lineage allows us to trace a model back to its origin and have confidence in its predictions.
Why is model lineage important
Model lineage is one of five key components that contribute to model governance. It is quite possibly the most important. Together with model visibility, explainability, interpretability and reproducibility, they form part of the foundation required to perform Ethical AI.
My next blog post will build on what we have just discussed and go into greater detail about the five components of model governance. It will also explore how Cloudera Machine Learning (CML) supports strong model governance and briefly introduce some elements of how CML supports effective ML Ops at Enterprise scale.
To learn more about Machine Learning, head over to Cloudera’s Fast Forward Labs or connect with us directly.
Editor's Choice

