

Cloudera has a strong track record of providing a comprehensive solution for stream processing. Cloudera Stream Processing (CSP), powered by Apache Flink and Apache Kafka, provides a complete stream management and stateful processing solution. In CSP, Kafka serves as the storage streaming substrate, and Flink as the core in-stream processing engine that supports SQL and REST interfaces. CSP allows developers, data analysts, and data scientists to build hybrid streaming data pipelines where time is a crucial factor, such as fraud detection, network threat analysis, instantaneous loan approvals, and so on.
We are now launching Cloudera Stream Processing Community Edition (CSP-CE), which makes all of these tools and technologies readily available for developers and anyone who wants to experiment with them and learn about stream processing, Kafka and friends, Flink, and SSB.
In this blog post we’ll introduce CSP-CE, show how easy and quick it is to get started with it, and list a few interesting examples of what you can do with it.
For a complete hands-on introduction to CSP-CE, please check out the Installation and Getting Started guide in the CSP-CE documentation, which contain step-by-step tutorials on how to install and use the different services included in it.
You can also join the Cloudera Stream Processing Community, where you will find articles, examples, and a forum where you can ask related questions.
Cloudera Stream Processing Community Edition
The Community Edition of CSP makes developing stream processors easy, as it can be done right from your desktop or any other development node. Analysts, data scientists, and developers can now evaluate new features, develop SQL–based stream processors locally using SQL Stream Builder powered by Flink, and develop Kafka consumers/producers and Kafka Connect connectors, all locally before moving to production.
CSP-CE is a Docker-based deployment of CSP that you can install and run in minutes. To get it up and running, all you need is to download a small Docker-compose configuration file and execute one command. If you follow the steps in the installation guide, in a few minutes you will have the CSP stack ready to use on your laptop.
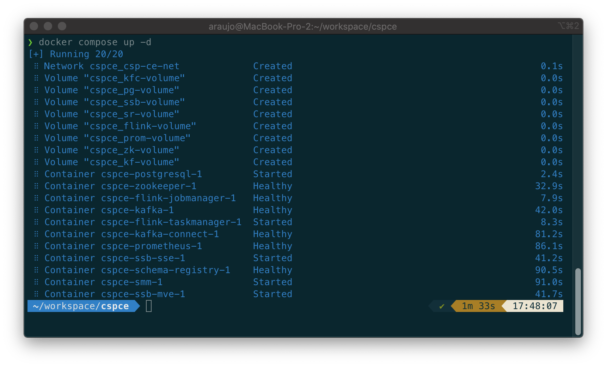
Installation and launching of CSP-CE takes a single command and just a few minutes to complete.
When the command completes, you will have the following services running in your environment:
- Apache Kafka: Pub/sub message broker that you can use to stream messages across different applications.
- Apache Flink: Engine that enables the creation of real-time stream processing applications.
- SQL Stream Builder: Service that runs on top of Flink and enables users to create their own stream processing jobs using SQL.
- Kafka Connect: Service that makes it really easy to get large data sets in and out of Kafka.
- Schema Registry: Central repository for schemas used by your applications.
- Stream Messaging Manager (SMM): Comprehensive Kafka monitoring tool.
In the next sections we’ll explore these tools in more detail.
Apache Kafka and SMM
Kafka is a distributed scalable service that enables efficient and fast streaming of data between applications. It is an industry standard for the implementation of event-driven applications.
CSP-CE includes a one-node Kafka service and also SMM, which makes it very easy to manage and monitor your Kafka service. With SMM you don’t need to use the command line to perform tasks like topic creation and reconfiguration, check the status of the Kafka service, or inspect the contents of topics. All of this can be conveniently done through a GUI that gives you a 360-degree view of the service.
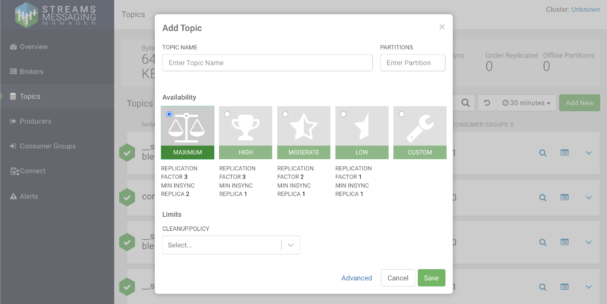
Creating a topic in SMM
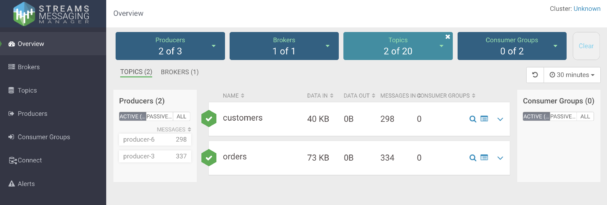
Listing and filtering topics
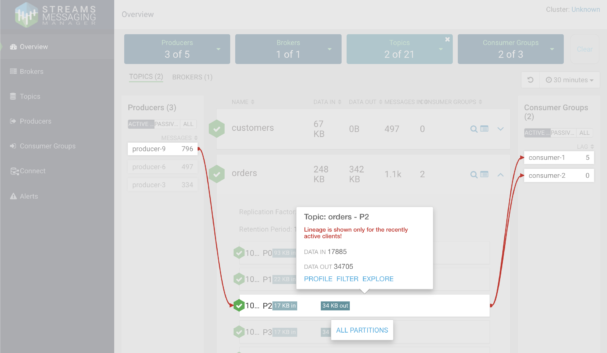
Monitoring topic activity, producers, and consumers
Flink and SQL Stream Builder
Apache Flink is a powerful and modern distributed processing engine that is capable of processing streaming data with very low latencies and high throughputs. It is scalable and the Flink API is very rich and expressive with native support to a number of interesting features like, for example, exactly-once semantics, event time processing, complex event processing, stateful applications, windowing aggregations, and support for handling of late-arrival data and out-of-order events.
SQL Stream Builder is a service built on top of Flink that extends the power of Flink to users who know SQL. With SSB you can create stream processing jobs to analyze and manipulate streaming and batch data using SQL queries and DML statements.
It uses a unified model to access all types of data so that you can join any type of data together. For example, it’s possible to continuously process data from a Kafka topic, joining that data with a lookup table in Apache HBase to enrich the streaming data in real time.
SSB supports a number of different sources and sinks, including Kafka, Oracle, MySQL, PostgreSQL, Kudu, HBase, and any databases accessible through a JDBC driver. It also provides native source change data capture (CDC) connectors for Oracle, MySQL, and PostgreSQL databases so that you can read transactions from those databases as they happen and process them in real time.
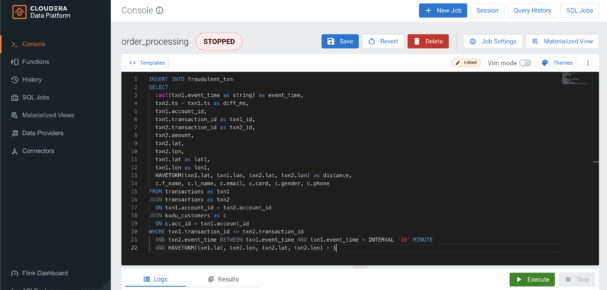
SSB Console showing a query example. This query performs a self-join of a Kafka topic with itself to find transactions from the same users that happen far apart geographically. It also joins the result of this self-join with a lookup table stored in Kudu to enrich the streaming data with details from the customer accounts
SSB also allows for materialized views (MV) to be created for each streaming job. MVs are defined with a primary key and they keep the latest state of the data for each key. The content of the MVs are served through a REST endpoint, which makes it very easy to integrate with other applications.
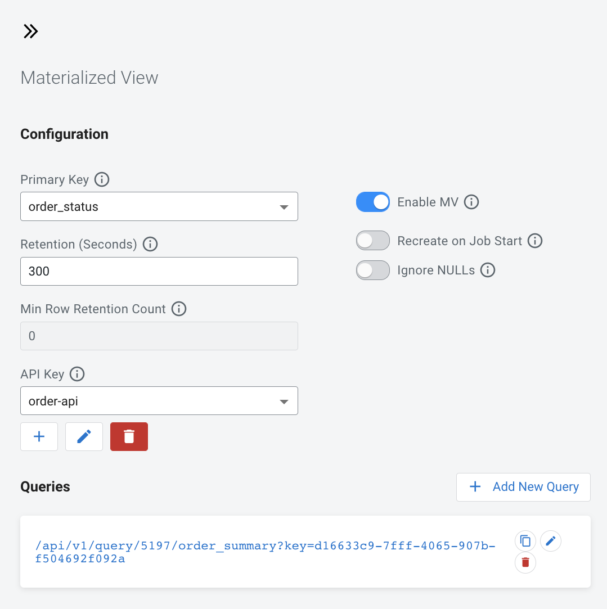
Defining a materialized view on the previous order summary query, keyed by the order_status column. The view will keep the latest data records for each different value of order_status
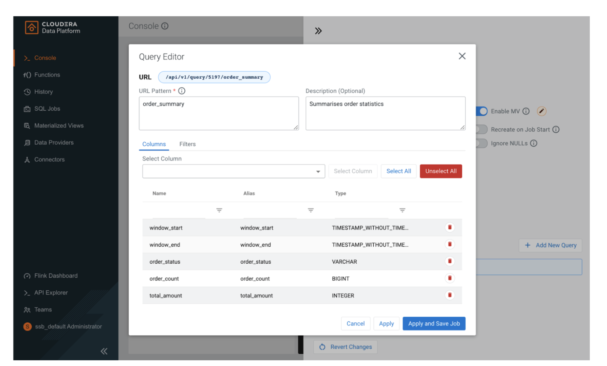
When defining a MV you can select which columns to add to it and also specify static and dynamic filters
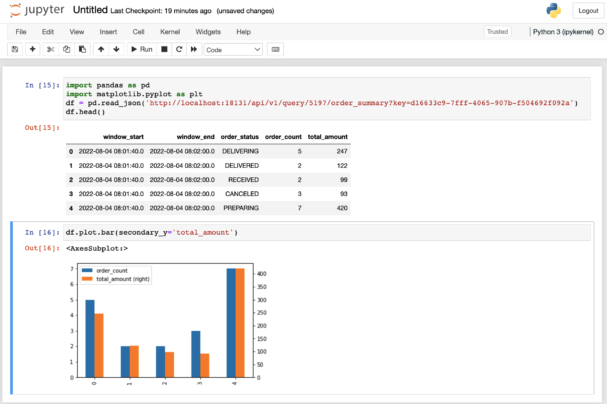
Example showing how easy it is to access and use the content of a MV from an external application, in the case a Jupyter Notebook
All the jobs created and launched in SSB are executed as Flink jobs, and you can use SSB to monitor and manage them. If you need to get more details on the job execution SSB has a shortcut to the Flink dashboard, where you can access internal job statistics and counters.
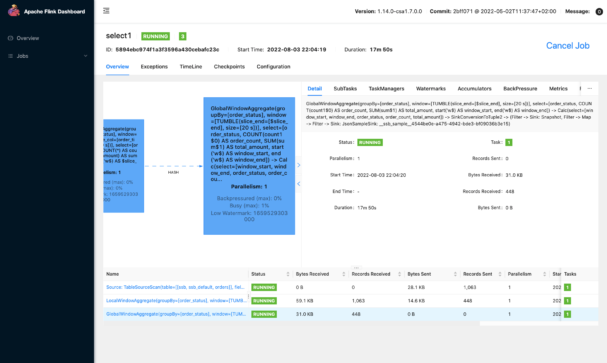
Flink Dashboard showing the Flink job graph and metric counters
Kafka Connect
Kafka Connect is a distributed service that makes it really easy to move large data sets in and out of Kafka. It comes with a variety of connectors that enable you to ingest data from external sources into Kafka or write data from Kafka topics into external destinations.
Kafka Connect is also integrated with SMM, so you can fully operate and monitor the connector deployments from the SMM GUI. To run a new connector you simply have to select a connector template, provide the required configuration, and deploy it.
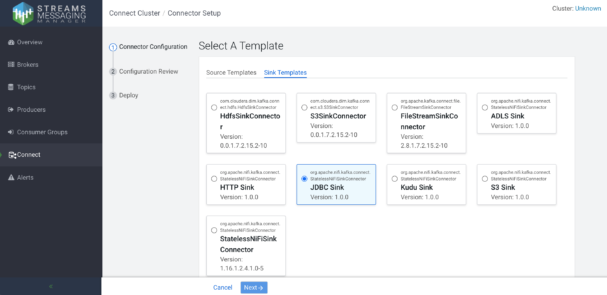
Deploying a new JDBC Sink connector to write data from a Kafka topic to a PostgreSQL table
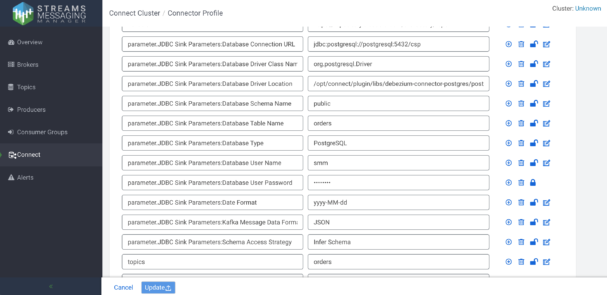
No coding is required. You only need to fill the template with the required configuration
Once the connector is deployed you can manage and monitor it from the SMM UI.
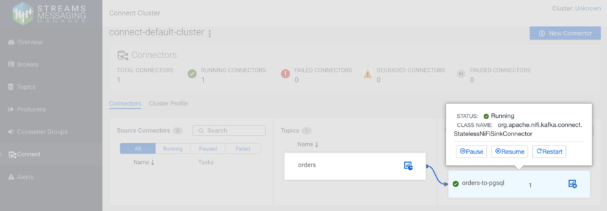
The Kafka Connect monitoring page in SMM shows the status of all the running connectors and their association with the Kafka topics
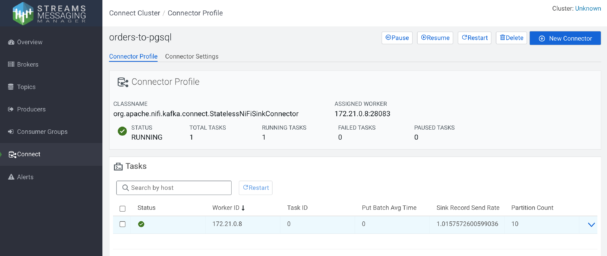
You can also use the SMM UI to drill down into the connector execution details and troubleshoot issues when necessary
Stateless NiFi connectors
The Stateless NiFi Kafka Connectors allow you to create a NiFi flow using the vast number of existing NiFi processors and run it as a Kafka Connector without writing a single line of code. When existing connectors don’t meet your requirements, you can simply create one in the NiFi GUI Canvas that does exactly what you need. For example, perhaps you need to place data on S3, but it has to be a Snappy-compressed SequenceFile. It’s possible that none of the existing S3 connectors make SequenceFiles. With the Stateless NiFi Connector you can easily build this flow by visually dragging, dropping, and connecting two of the native NiFi processors: CreateHadoopSequenceFile and PutS3Object. After the flow is created, export the flow definition, load it into the Stateless NiFi Connector, and deploy it in Kafka Connect.
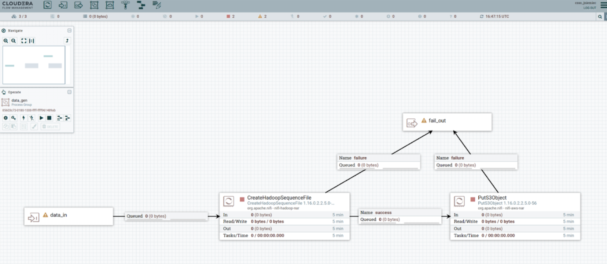
A NiFi Flow that was built to be used with the Stateless NiFi Kafka Connector
Schema Registry
Schema Registry provides a centralized repository to store and access schemas. Applications can access the Schema Registry and look up the specific schema they need to utilize to serialize or deserialize events. Schemas can be created in ethier Avro or JSON, and have evolved as needed while still providing a way for clients to fetch the specific schema they need and ignore the rest.
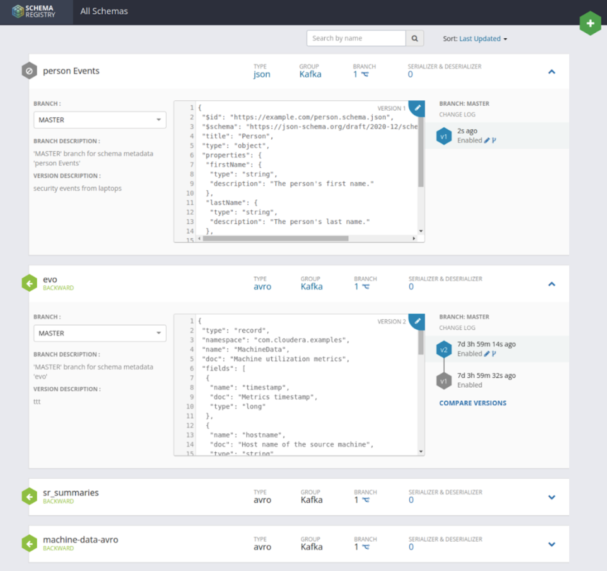
Schemas are all listed in the schema registry, providing a centralized repository for applications
Conclusion
Cloudera Stream Processing is a powerful and comprehensive stack to help you implement fast and robust streaming applications. With the launch of the Community Edition, it is now very easy for anyone to create a CSP sandbox to learn about Apache Kafka, Kafka Connect, Flink, and SQL Stream Builder, and quickly start building applications.
Give Cloudera Stream Processing a try today by downloading the Community Edition and getting started right on your local machine! Join the CSP community and get updates about the latest tutorials, CSP features and releases, and learn more about Stream Processing.
Editor's Choice

