


Introduction
Stream processing is about creating business value by applying logic to your data while it is in motion. Many times that involves combining data sources to enrich a data stream. Flink SQL does this and directs the results of whatever functions you apply to the data into a sink. Business use cases, such as fraud detection, advertising impression tracking, health care data enrichment, augmenting financial spend information, GPS device data enrichment, or personalized customer communication are great examples of using hive tables for enriching datastreams. Therefore, there are two common use cases for Hive tables with Flink SQL:
- A lookup table for enriching the data stream
- A sink for writing Flink results
There are also two ways to use a Hive table for either of these use cases. You may either use a Hive catalog, or the Flink JDBC connector used in Flink DDL. Let’s discuss how they work, and what their advantages and disadvantages are.
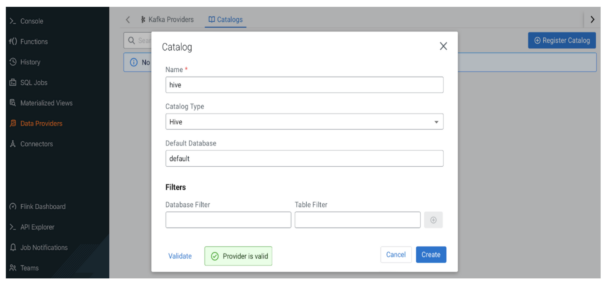
Registering a Hive Catalog in SQL Stream Builder
SQL Stream Builder (SSB) was built to give analysts the power of Flink in a no-code interface. SSB has a simple way to register a Hive catalog:
- Click on the “Data Providers” menu on the sidebar
- Click on “Register Catalog” in the lower box
- Select “Hive” as catalog type
- Give it a name
- Declare your default database
- Click “Validate”
- Upon successful validation, click on “Create”
After the above steps, your Hive tables will show up in the tables list after you pick it as the active catalog. Currently, via the catalog concept Flink supports only non-transactional Hive tables when accessed directly from HDFS for reading or writing.
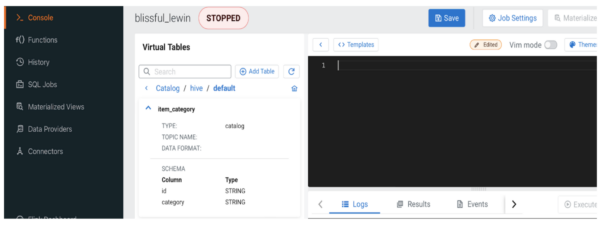
Using Flink DDL with JDBC connector
Using the Flink JDBC connector, a Flink table can be created for any Hive table right from the console screen, where a table’s Flink DDL creation script can be made available. This will specify a URL for the Hive DB and Table name. All Hive tables can be accessed this way regardless of their type. JDBC DDL statements can even be generated via “Templates”. Click “Templates” –> “jdbc” and the console will paste the code into the editor.
CREATE TABLE `ItemCategory_transactional_jdbc_2` ( `id` VARCHAR(2147483647), `category` VARCHAR(2147483647) ) WITH ( ‘connector’ = ‘jdbc’, ‘lookup.cache.ttl’ = ‘10s’, ‘lookup.cache.max.rows’ = ‘10000’, ‘tablename’ = ‘item_category_transactional’, ‘url’ = ‘jdbc:hive2://<host>:<port>/default’ )
Using a Hive table as a lookup table
Hive tables are often used as lookup tables in order to enrich a Flink stream. Flink is able to cache the data found in Hive tables to improve performance. FOR SYSTEM_TIME AS OF clause needs to be set to tell Flink to join with a temporal table. For more details check the relevant Flink doc.
SELECT t.itemId, i.category FROM TransactionsTable t LEFT JOIN ItemCategory_transactional_jdbc FOR SYSTEM_TIME AS OF t.event_time i ON i.id = t.itemId
Hive Catalog tables
For Hive Catalog tables, the TTL (time to live) of the cached lookup table can be configured using the property “lookup.join.cache.ttl” (the default of this value is one hour) of the Hive table like this from Beeline or Hue:

Pros: No DDL needs to be defined, a simple Hive catalog will work.
Cons: Only works with non-transactional tables
Flink DDL tables with JDBC connector
The default when using a Hive table with JDBC connector is no caching, which means that Flink would reach out to Hive for each entry that needs to be enriched! We can change that by specifying two properties in the DDL command, lookup.cache.max-rows and lookup.cache.ttl.
Flink will lookup the cache first, only send requests to the external database when cache is missing, and update cache with the rows returned. The oldest rows in cache will expire when the cache hits the max cached rows lookup.cache.max-rows or when the row exceeds the max time to live lookup.cache.ttl. The cached rows might not be the latest. Some users may wish to refresh the data more frequently by tuning lookup.cache.ttl but this may increase the number of requests sent to the database. Users will have to balance throughput and freshness of the cached data.
CREATE TABLE `ItemCategory_transactional_jdbc_2` ( `id` VARCHAR(2147483647), `category` VARCHAR(2147483647) ) WITH ( ‘connector’ = `jdbc’, ‘lookup.cache.ttl’ = ‘10s’, ‘lookup.cache.max-rows’ = ‘10000’, ‘table-name’ = ‘item_category_transactional’, ‘url’ = ‘jdbc:hive2://<host>:<port>/default’ )
Pros: All Hive tables can be accessed this way, and the caching is more fine-tuned.
Please note the caching parameters—this is how we ensure good JOIN performance balanced with fresh data from Hive, adjust this as necessary.
Using a Hive table as a sink
Saving the output of a Flink job to a Hive table allows us to store processed data for various needs. To do this one can use the INSERT INTO statement and write the result of their query into a specified Hive table. Please note that you may have to adjust checkpointing time-out duration of a JDBC sink job with Hive ACID table.
INSERT INTO ItemCategory_transactional_jdbc_2 SELECT t.itemId, i.category FROM TransactionsTable t LEFT JOIN ItemCategory_transactional_jdbc FOR SYSTEM_TIME AS OF t.event_time i ON i.id = t.itemId
Hive Catalog tables
No DDL needs to be written. Only non-transactional tables are supported, thus it only works with append-only streams.
Flink DDL tables with JDBC connector
With this option upsert type data can be written into transactional tables. In order to be able to do that a primary key should be defined.
CREATE TABLE `ItemCategory_transactional_jdbc_sink` ( `id` STRING, `category` STRING, PRIMARY KEY (`id`) NOT ENFORCED ) WITH ( ‘connector’ = ‘jdbc’, ‘table-name’ = ‘item_category_transactional_sink’, ‘url’ = ‘jdbc:hive2://<host>:<port>/default’ )
When this job executes, Flink will overwrite every record with the same primary key value if it is already present in the table. This also works for upsert streams as well with transactional Hive tables.
Conclusions
We’ve covered how to use SSB to enrich data streams in Flink with Hive tables as well as how to use Hive tables as a sink for Flink results. This can be useful in many business use cases involving enriching datastreams with lookup data. We took a deeper dive into different approaches of using Hive tables. We also discussed the pros and cons of different approaches and various caches related options to improve performance. With this information, you can make a decision about which approach is best for you.
If you would like to get hands on with SQL Stream Builder, be sure to download the community edition today!
Editor's Choice

