

Apache Hive supports transactional tables which provide ACID guarantees. There has been a significant amount of work that has gone into hive to make these transactional tables highly performant. Apache Spark provides some capabilities to access hive external tables but it cannot access hive managed tables. To access hive managed tables from spark Hive Warehouse Connector needs to be used.
We are happy to announce Spark Direct Reader mode in Hive Warehouse Connector which can read hive transactional tables directly from the filesystem. This feature has been available from CDP-Public-Cloud-2.0 (7.2.0.0) and CDP-DC-7.1 (7.1.1.0) releases onwards.
Hive Warehouse Connector (HWC) was available to provide access to managed tables in hive from spark, however since this involved communication with LLAP there was an additional hop to get the data and process it in spark vs the ability of spark to directly read the data from FileSystem for External tables. This leads to performance degradation in accessing data from managed tables vs external tables. Additionally a lot of use cases for HWC were associated with ETL jobs where a super user was running these jobs to update data in multiple tables hence authorization was not a strong business need for this case. HWC Spark Direct Reader is an additional mode available in HWC which tries to address the above concerns. This article describes the usage of spark direct reader to consume hive transactional table data in a spark application. It also introduces the methods and APIs to read hive transactional tables into spark dataframes. Finally, it demonstrates the transaction handling and semantics while using this reader.
HWC Spark Direct Reader is derived from Qubole Spark Acid Connector.
Prerequisites
Following are the prerequisites to be able to query hive managed tables from Spark Direct Reader –
- Connectivity to HMS (Hive Metastore) which means the spark application should be able to access hive metastore using thrift URI. This URI is determined by hive config hive.metastore.uris
- The User launching spark application must have Read and Execute permissions on hive warehouse location on the filesystem. The location is determined by hive config hive.metastore.warehouse.dir
Use cases
This section focuses on the usage of the Spark Direct Reader to read transactional tables.
Consider that we have a hive transactional table emp_acid which contains information about the employees.
With auto-translate extension enabled
The connector has an auto-translate rule which is a spark extension rule which automatically instructs spark to use spark direct reader in case of managed tables so that the user does not need to specify it explicitly.
See employee data in table emp_acid
scala> spark.sql("select * from emp_acid").show +------+----------+--------------------+-------------+--------------+-----+-----+-------+ |emp_id|first_name| e_mail|date_of_birth| city|state| zip|dept_id| +------+----------+--------------------+-------------+--------------+-----+-----+-------+ |677509| Lois|lois.walker@hotma… | 3/29/1981| Denver | CO|80224| 4| |940761| Brenda|brenda.robinson@g...| 7/31/1970| Stonewall | LA |71078| 5| |428945| Joe|joe.robinson@gmai… | 6/16/1963| Michigantown| IN |46057| 3| ………. ………. ……….
Using transactional tables in conjunction with other data sources
Spark direct reader works seamlessly with other data sources as well, like in the below example we are joining emp_acid table with an external table dept_ext to find out corresponding departments of employees.
scala> sql("select e.emp_id, e.first_name, d.name department from emp_acid e join dept_ext d on e.dept_id = d.id").show +------+----------+-----------+ |emp_id|first_name| department| +------+----------+-----------+ |677509| Lois | HR | |940761| Brenda| FINANCE| |428945| Joe | ADMIN |
Here direct reader is used to fetch the data of emp_acid table since it’s transactional table, the data of dept_ext table is fetched by spark’s native reader
scala> sql("select e.emp_id, e.first_name, d.name department from emp_acid e join dept_ext d on e.dept_id = d.id").explain == Physical Plan == *(2) Project [emp_id#288, first_name#289, name#287 AS department#255] +- *(2) BroadcastHashJoin [dept_id#295], [id#286], Inner, BuildRight :- *(2) Filter isnotnull(dept_id#295) : +- *(2) Scan HiveAcidRelation(org.apache.spark.sql.SparkSession@1444fa42,default.emp_acid,Map(transactional -> true, numFilesErasureCoded -> 0, bucketing_version -> 2, transient_lastDdlTime -> 1594830632, transactional_properties -> default, table -> default.emp_acid)) [emp_id#288,first_name#289,dept_id#295] PushedFilters: [IsNotNull(dept_id)], ReadSchema: struct<emp_id:int,first_name:string,dept_id:int> +- BroadcastExchange HashedRelationBroadcastMode(List(cast(input[0, int, true] as bigint))), [id=#169] +- *(1) Project [id#286, name#287] +- *(1) Filter isnotnull(id#286) +- *(1) FileScan orc default.dept_ext[id#286,name#287] Batched: true, Format: ORC, Location: InMemoryFileIndex[hdfs://anurag-hwc-1.anurag-hwc.root.hwx.site:8020/warehouse/tablespace/external..., PartitionFilters: [], PushedFilters: [IsNotNull(id)], ReadSchema: struct<id:int,name:string>
- Configurations to enable auto-translate
To turn on auto translate feature, we need to specify spark sql extension like
- spark.sql.extensions=com.qubole.spark.hiveacid.HiveAcidAutoConvertExtension
Using Hive Warehouse Connector executeQuery() API
If you are already using Hive Warehouse Connector in your spark application then you can continue to use executeQuery() API and switch to Spark Direct Reader just by adding some configurations.
Code is similar to what we need to use with Hive Warehouse Connector. Queries shown in sections 3.1.1 and 3.1.2 can be done like the following.
scala> val hive = com.hortonworks.hwc.HiveWarehouseSession.session(spark).build() scala> hive.executeQuery("select * from emp_acid").show scala> hive.executeQuery("select e.emp_id, e.first_name, d.name department from emp_acid e join dept_ext d on e.dept_id = d.id").show
- Configurations to use Spark Direct Reader via Hive Warehouse Connector API
- spark.datasource.hive.warehouse.read.via.llap=false
- spark.sql.hive.hwc.execution.mode=spark
- spark.sql.extensions=com.qubole.spark.hiveacid.HiveAcidAutoConvertExtension
Behind the scenes – Read Architecture
Spark Direct Reader is built on top DataSource V1 APIs exposed by spark which allows us to plug in custom data sources to spark. In our case the custom data source is the layer which enables us to read hive ACID tables.
Following diagram depicts the high level read process and transaction management in connector
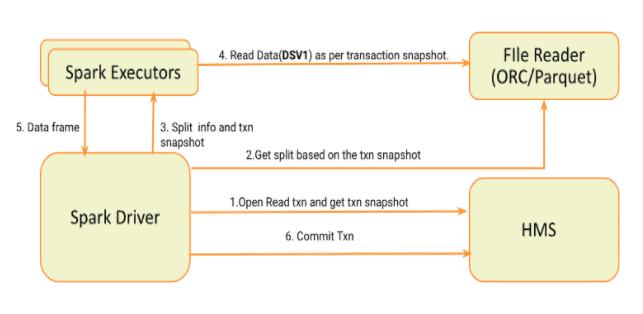
- Spark Driver parses the query and for each ACID table starts a read txn.
- Transaction snapshot for each table is stored separately and is used for generating the split.
- Spark driver serializes and sends the partition info and txn snapshot to executors.
- Executors read the specific split using the transaction snapshot.
- Processed and transformed data is sent back to the driver.
- Driver commits the read transactions started.
Note on transactions
Currently the connector only supports single table transaction consistency i.e. one new transaction is opened for each table involved in query. This means if multiple tables are involved in the query then all may not use the same snapshot of data.
- Transactions when single table t1 is involved
scala> spark.sql(“select * from t1”).show
20/07/08 05:41:39 INFO transaction.HiveAcidTxn: Begin transaction {"id":"174","validTxns":"174:9223372036854775807::"} 20/07/08 05:41:39 INFO transaction.HiveAcidTxn: Lock taken for lockInfo com.qubole.spark.hiveacid.transaction.LockInfo@37f5c5fd in transaction with id 174 .... .... 20/07/08 05:41:47 INFO transaction.HiveAcidTxn: End transaction {"id":"174","validTxns":"174:9223372036854775807::"} abort = false
- Transactions when multiple tables t3 and t4 are involved
scala> spark.sql("select * from default.t3 join default.t4 on default.t3.a = default.t4.a").show 20/07/08 05:43:36 INFO transaction.HiveAcidTxn: Begin transaction {"id":"175","validTxns":"175:9223372036854775807::"} 20/07/08 05:43:36 INFO transaction.HiveAcidTxn: Lock taken for lockInfo com.qubole.spark.hiveacid.transaction.LockInfo@67cc7aee in transaction with id 175 .... .... 20/07/08 05:43:36 INFO transaction.HiveAcidTxn: Begin transaction {"id":"176","validTxns":"176:175:175:"} 20/07/08 05:43:36 INFO transaction.HiveAcidTxn: Lock taken for lockInfo com.qubole.spark.hiveacid.transaction.LockInfo@a8c0c6d in transaction with id 176 .... .... 20/07/08 05:43:53 INFO transaction.HiveAcidTxn: End transaction {"id":"175","validTxns":"175:9223372036854775807::"} abort = false 20/07/08 05:43:53 INFO transaction.HiveAcidTxn: End transaction {"id":"176","validTxns":"176:175:175:"} abort = false
Notice different transactions 175 and 176 when two different tables t3 and t4 are present in the query.
- API to close transactions explicitly
To commit or abort transactions, we have a sql listener which does it whenever a dataframe operation or spark sql query finishes. In some cases when .explain() / .rdd() / .cache() are invoked on a dataframe, it opens a transaction and never closes it since technically they are not spark sql queries so the sql listener does not kick in. To handle this scenario and to be able to close the transactions manually, an explicit API is exposed which can be invoked like the following.
scala> com.qubole.spark.hiveacid.transaction.HiveAcidTxnManagerObject.commitTxn(spark)
Or if you are using Hive Warehouse Connector’s session (say ‘hive’ is the instance)
scala> hive.commitTxn
Configuration Summary
To use Spark Direct Reader, we need the following configurations.
| Property | Value | Description |
| spark.hadoop.hive.metastore.uris | thrift://<host>:<port> | Hive metastore URI |
| spark.sql.extensions | com.qubole.spark.hiveacid.HiveAcidAutoConvertExtension | Extension needed to auto-translate to work |
| spark.kryo.registrator | com.qubole.spark.hiveacid.util.HiveAcidKyroRegistrator | For using kryo serialization. |
| spark.sql.hive.hwc.execution.mode | spark | |
| spark.datasource.hive.warehouse.read.via.llap | false |
Hive Warehouse connector jar should be supplied to spark-shell or spark-submit using –jars option while launching the application. For instance, spark-shell can be launched like the following.
spark-shell --jars /opt/cloudera/parcels/CDH/lib/hive_warehouse_connector/hive-warehouse-connector-assembly-<version>.jar \ --conf "spark.sql.extensions=com.qubole.spark.hiveacid.HiveAcidAutoConvertExtension" \ --conf "spark.datasource.hive.warehouse.read.via.llap=false" \ --conf "spark.sql.hive.hwc.execution.mode=spark" \ --conf "spark.kryo.registrator=com.qubole.spark.hiveacid.util.HiveAcidKyroRegistrator" \ --conf "spark.hadoop.hive.metastore.uris=<metastore_uri>"
Further Information and Resources
- Cloudera Data Warehouse
- HWC Spark Direct Reader for accessing Hive data
- Integrating Apache Hive with Apache Spark
Editor's Choice


I’m trying to use the spark acid connector directly but I see “ORC split generation failed with exception: For input string:”.
Hi,
how would you read an acid table , do data preparation on it and Write the results back to the data lake ?
Br,
Dennis