![Distributed Pricing Engine using Dockerized Spark on YARN w/ HDP 3.0 [Part 2/4]](/wp-content/themes/cloudera/assets/images/default-banner/GettyImages-1287640296-1382x400.jpg)

This blog post was published on Hortonworks.com before the merger with Cloudera. Some links, resources, or references may no longer be accurate.
This is the 2nd blog in a 4-part blog series (see part 1) where we will dive into representative pricing semantics and architectural aspects of a prototype implementation using HDP 3.0.
Pricing Semantics
The engine leverages QuantLib, an open source library for quantitative finance, to compute:
- Spot Price of a Forward Rate Agreement (FRA) using the library’s yield term structure based on flat interpolation of forward rates.
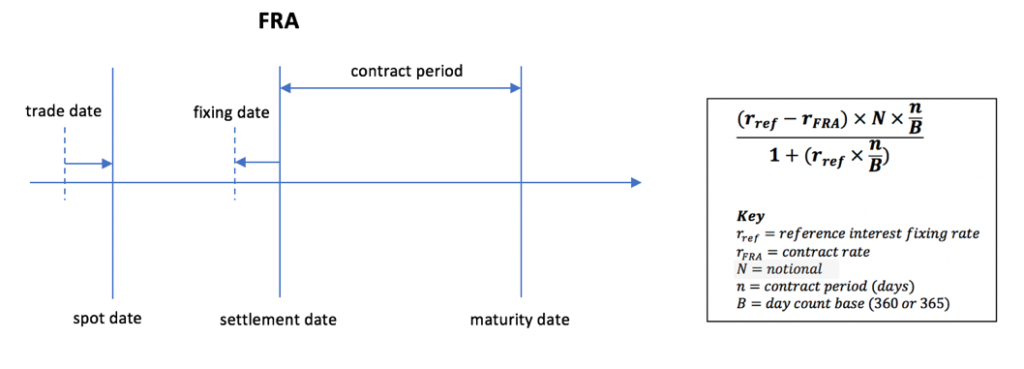
- NPV of a vanilla fixed-float 5yr Interest Rate Swap (IRS)
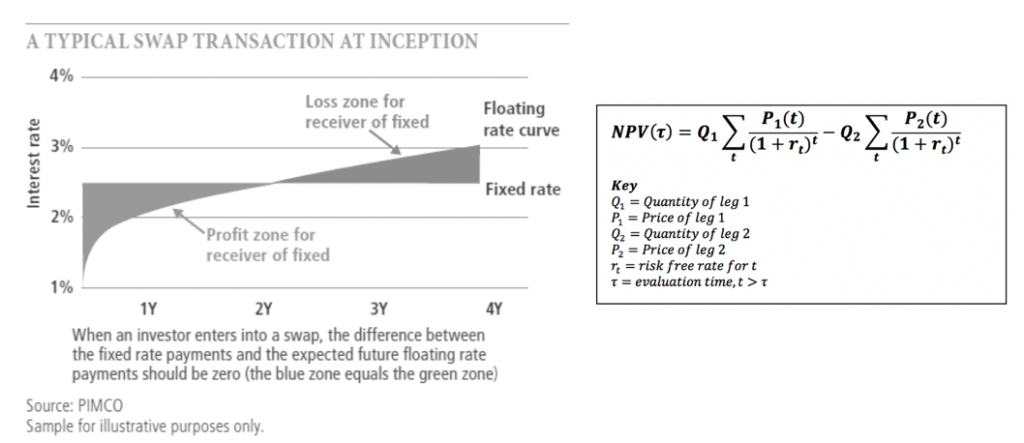
- NPV of a European Equity Put Option averaged over multiple algorithmic calculations (Black-Scholes, Binomial, Monte-Carlo)
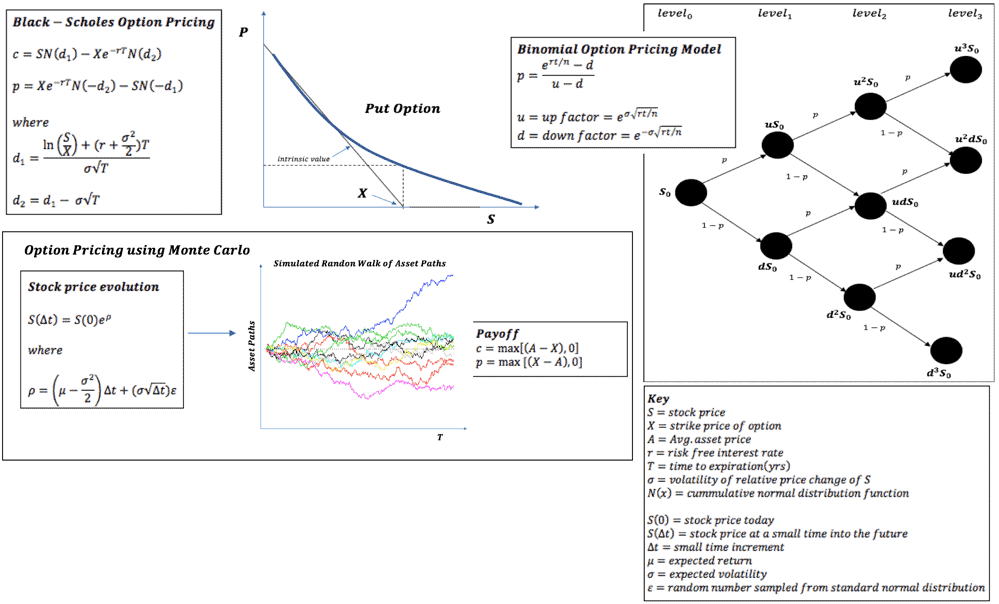
For the purpose of demonstration, requisite inputs for these calculations – yield curves, fixings, instrument definitions etc. are statically incorporated and dimensional aggregation of these computed metrics for a portfolio of trades is trivially simulated by parallelizing the calculation for a specified number of N times (portfolio size of N trades) and computing a mean.
Architectural Approach
The engine basically exploits the embarrassingly parallel nature of the problem around independent parallel pricing tasks leveraging Apache Spark in its map phase and computing mean as the trivial reduction operation.
A more real-world consideration of the pricing engine would also benefit from distributed in-memory facilities of Spark for shared ancillary datasets such as market (quotes), derived market (curves), reference (term structures, fixings etc.) and trade data as inputs for pricing, typically subscribed to from the corresponding data services using persistent structures in HBase and Hive leveraging HDFS.
These pricing tasks essentially call QuantLib library functions that can range from analytical to parallel algorithms discussed above to price instruments. Building, installing and managing the library and associated dependencies across a cluster of 100s of nodes can in itself be cumbersome and challenging. What if now one wants to run regression tests on a newer version of the library in conjunction with the current version?
OS virtualization through Docker is a great way to address these operational challenges around hardware and OS portability, build automation, multi-version dependency management, packaging and isolation and integration with server-side infrastructure typically running on JVMs and of course more efficient higher density utilization of the cluster resources.
Here, we use a Docker image with QuantLib over a layer of lightweight CentOS using Java language bindings through SWIG.
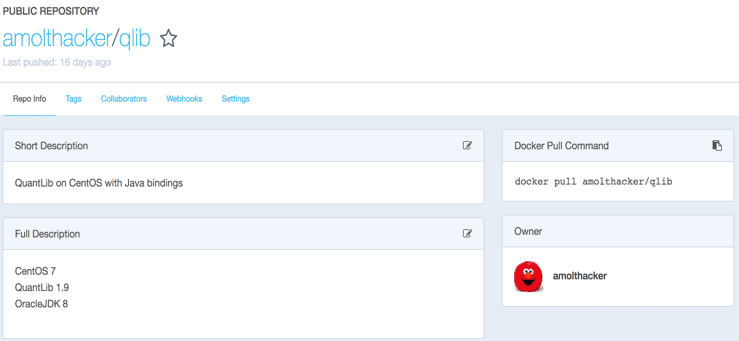
With Hadoop 3.1 in HDP 3.0, YARN’s support for LinuxContainerExecutor beyond the classic DefaultContainerExecutor facilitates running multiple container runtimes – the DefaultLinuxContainerRuntime and now the DockerLinuxContainerRuntime side by side. Docker containers running QuantLib with Spark executors, in this case, are scheduled and managed across the cluster by YARN using its DockerLinuxContainerRuntime.
This facilitates consistency of resource management and scheduling across container runtimes and lets Dockerized applications take full advantage of all of the YARN RM & scheduling aspects including Queues, ACLs, fine-grained sharing policies, powerful placement policies etc.
Also, when running Spark executor in Docker containers on YARN, YARN automatically mounts the base libraries and any other requested libraries as follows:
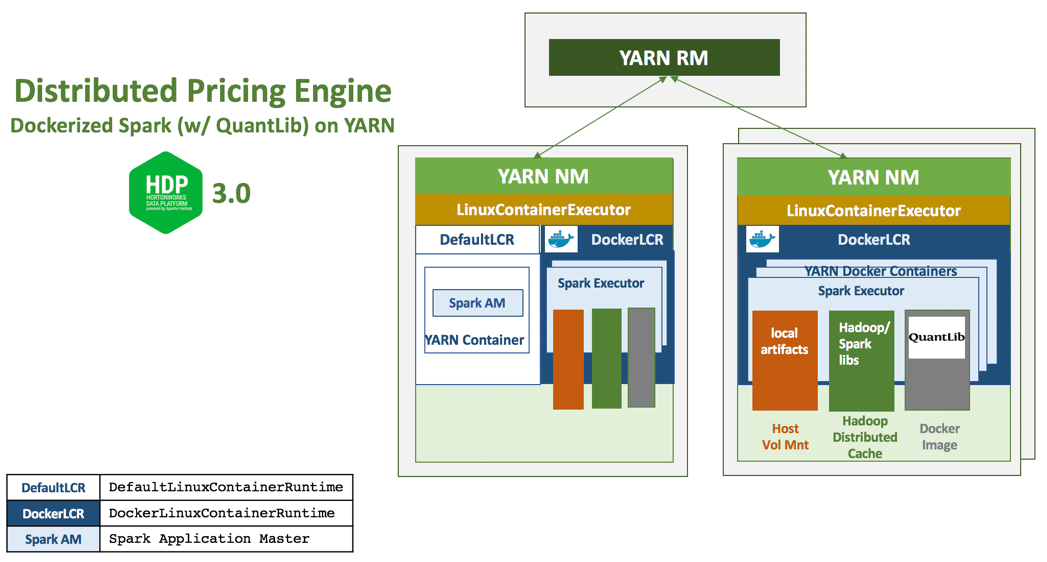
For more details – I encourage you to read these awesome blogs on containerization in Apache Hadoop YARN 3.1 and containerized Apache Spark on YARN 3.1
In Part 3 of this blog series, we will dive deeper into the tech stack and prepare the environment, read it now!
Editor's Choice

