

This blog discusses answers to questions like what is the right disk size in datanode and what is the right capacity for a datanode.
A few of our customers have asked us about using dense storage nodes. It is certainly possible to use dense nodes for archival storage because IO bandwidth requirements are usually lower for cold data. However the decision to use denser nodes for hot data must be evaluated carefully as it can have an impact on the performance of the cluster. You may be able to use denser nodes for hot data if you have provisioned adequate network bandwidth to mitigate the higher recovery time and have modeled your expected workloads.
There are two factors to keep in mind when choosing node capacity. These will be discussed in detail in the next sections.
- Large Disks – total node capacity being the same, using more disks is better as it yields higher aggregate IO bandwidth.
- Dense Nodes – as nodes get denser, recovery after node failure takes longer.
These factors are not HDFS-specific and will impact any distributed storage service that replicates data for redundancy and serves live workloads.
Our recommendation is to limit datanodes to 100TB capacity with at least 8 disks. This gives an upper bound on the disk size of 100TB/8 ~ 12TB.
The blog post assumes some understanding of HDFS architecture.
Impact of Large volumes on HDFS cluster
Reduced IO bandwidth
Hadoop clusters rely on massively parallel IO capacity to support thousands of concurrent tasks. Given a datanode of size 96TB, let us consider two disk sizes – 8TB and 16TB. A datanode with 8TB disk would have 12 such disks whereas one with 16TB disk would have 6. We can assume an average read/write throughput of 100MB/sec and spindle speed of 7200 RPM for every disk. The table below summarizes bandwidth and IOPS for each configuration.
| 8TB ⋅ 12 = 96TB | 16TB ⋅ 6 = 96TB | |
| Read/Write Throughput | 1200 MB/sec | 600 MB/sec |
| Random IOPS | 2880 | 1440 |
Detecting bit-rot takes longer
Each datanode runs a volume scanner per volume which scans the blocks for bit-rot. The default scan period is 3 weeks, so a replica lost to bit-rot is detected within 3 weeks. Since volume scanner competes with applications for disk resources, it is important to limit its disk bandwidth. The config dfs.block.scanner.volume.bytes.per.second defines the number of bytes volume scanner can scan per second and it defaults to 1MB/sec. Given configured bandwidth of 5MB/sec.
Time taken to scan 12TB = 12TB/5MBps ~ 28 days.
Increasing disk sizes further will increase the time taken to detect bit-rot.
Heavyweight Block Reports
A larger volume size implies a large number of blocks in the volume block report. This has an effect on the cluster performance as it increases block report generation time in datanode, RPC payload and the block report processing time in namenode.
Below is a chart representing generation, network round trip time and processing time for block report sent by a datanode. The datanode has only one volume and the statistics are collected by increasing the number of blocks for the volume. All these metrics increase with an increase in the number of blocks in the disk.
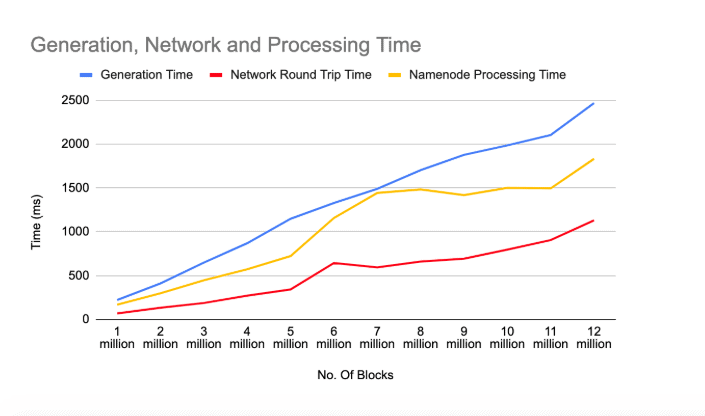
Impact of Dense Storage Nodes
Failure Recovery takes more time
Whenever a storage node fails, the blocks that were stored on the node must be replicated to other nodes in the cluster to restore data redundancy. The recovery time is linear in the size of datanode and inverse in the number of nodes in the cluster. Considering all other factors as constant recovery time can be calculated using the below formula.
Recovery time = (c ⋅ s) / n
Where c is a constant, s is the used capacity of each node and n is the number of storage nodes in the cluster.
For a given cluster capacity, if node capacity is doubled then recovery time increases by 4x. Assuming a balanced cluster the usage of every node doubles if the number of nodes is halved.
Recovery time = (c ⋅ 2s) / (n/2) = (4 ⋅ c ⋅ s)/n
Variables s and n hold a similar significance in other storage solutions as well. Therefore dense datanodes would have a similar impact on the recovery time in any cluster.
See this Community Article for more information.
Impact on Datanode Decommissioning
During the planned decommissioning of a node, all its blocks are re-replicated to other nodes. The effect of dense nodes on the decommission time of a datanode is similar to its effect on recovery time for a failed datanode. Therefore for a given cluster capacity, if the capacity of the datanode is doubled then decommission time increases by 4x.
HDFS-14854 implements several improvements that will improve the performance of node decommissioning. These improvements will be available in a future release of CDP.
Editor's Choice

