

At Cloudera Fast Forward, we routinely report on the latest and greatest in machine learning capabilities. Typically, our applied research culminates in a series of comprehensive reports released on a quarterly basis, along with a live webinar demonstrating the prototypes we build in conjunction with that research. But times they are a-changin’ and we’re experimenting with new formats for distributing our content! This time, instead of waiting until the prototype is finished and the report is polished, we thought it would be fun to invite you to join us while we build.
With that, we’d like to introduce the newest research topic for Cloudera Fast Forward: NLP for Automated Question Answering! We’ve launched a blog to host this endeavor at qa.fastforwardlabs.com. Our goal is to provide useful information for data scientists, machine learning practitioners, and their leaders. We’ll post articles every other week that are focused on the technical and practical aspects of building an automated question-answering system using state-of-the-art deep learning techniques for natural language processing, or commentary on high-level strategy and data governance. As development progresses, many of our posts will contain code, but we’ll also include our thoughts on best practices (and probably some griping about tenacious bugs we stumble across).
Now that we’ve stoked your curiosity you might be thinking, “What exactly are you building?”
We’re glad you asked.
“How many games did the Yankees play in July?”
This question and more were answered by the BASEBALL system, a question-answerer developed in the early 1960’s. It was built with a series of handwritten rules atop a database containing baseball statistics and information collected over the course of a single year. The hand-tailored nature of the system allowed it to produce highly accurate answers. Question Answering is thus one of the oldest natural language processing tasks. It has been the subject of consistent research and has made considerable progress in the intervening sixty years.
Rather than handwritten rules and structured databases, our work will focus on building a modern automated question answering system on top of a large collection of unstructured text documents such as Wikipedia – but we could imagine other use cases, such as a system built atop a newsfeed or a set of internal- or external-facing corporate documents. Building such a system typically requires two crucial pieces of functionality: a document retriever and a document reader. Let’s look at each of them more closely.
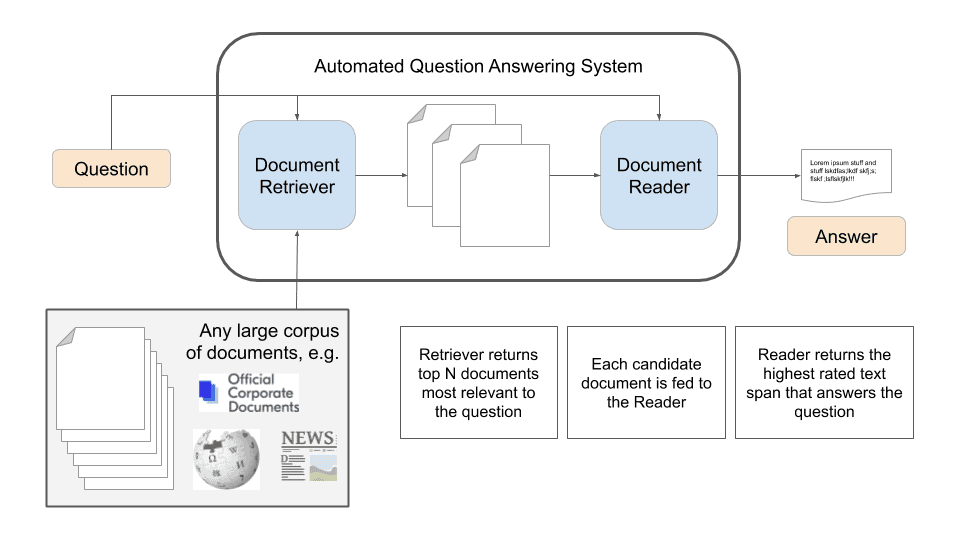
This is the generic workflow of an automated question answering system that uses a large corpus of unstructured text as its knowledge base. The system is composed of a document retriever to fetch the most relevant articles and a document reader that ingests these candidate articles in search of a text span that best answers the question.
When we’re tasked with finding the answer to a question in the midst of hundreds, thousands, even millions of documents, it’s like looking for the needle in the haystack. While state of the art NLP systems have made leaps and bounds towards the goal of authentic language understanding, these hefty deep learning models are slow to process text and thus don’t make good search engines. This is where the document retriever comes in. This component will use time-tested information retrieval algorithms that form the basis of all large-scale search engines today. Given a question, the document retriever sifts through the corpus and pulls out those that are most likely to be relevant.
Once we have a set of candidate documents, we can apply some machine learning methods. Recent advances in deep learning for NLP have made explosive progress in the past two years. The combination of multiple techniques – including transfer learning and the invention of the Transformer neural architecture – have led to dramatic improvements in several NLP tasks including sentiment analysis, document classification, question answering, and more. Models like BERT, XLNet, and Google’s new T5 work by processing a document and identifying a passage within that best answers the question. The passage might be a couple of words or a couple sentences. This snippet is then returned to the user as the answer.
We’ve set a high bar for ourselves, and we’ll have a lot to explore and discuss as this project unfolds. Today we released our first post in the series, which delves deeper into the background of question answering, elucidating the most promising frameworks and most often explored paradigms. Check the space often as we plan to post on a bi-weekly basis!
Editor's Choice

