

This blog post was published on Hortonworks.com before the merger with Cloudera. Some links, resources, or references may no longer be accurate.
With the release of Hortonworks Streams Messaging Manager (SMM) this year, we have focused on helping DevOps and Platform teams cure their Kafka Blindness. The Hortonworks product and engineering teams continue to invest in building powerful new capabilities in SMM with new upcoming features like alerting and topic lifecycle management.
In addition to the SMM investments, the team has also been focusing on the needs of application and BI developer personas to help them be more successful implementing different use cases where Kafka is key component of the application architecture.
To this end, the product and engineering teams have been conducting interviews with application architects and developers within our largest enterprise Kafka customers. From these discussions, several trends and requirements are clearly emerging:
- Trend #1: Kafka is becoming the de facto streaming event hub in the enterprise.
- Trend #2: Customers are starting to use Kafka for longer term storage. E.g.: Retention periods for Kafka topics are getting longer. Kafka is being used more and more as a streaming event storage substrate.
- Key Requirement: Application and BI/SQL developers need different Kafka analytic tools/access patterns based on different use cases / requirements. The current tooling is limited.
3 New Kafka Analytics Access Patterns Introduced for Application and BI Developers
To address these trends/requirements, the upcoming Hortonworks Data Platform (HDP) 3.1 and Hortonworks DataFlow (HDF) 3.3 releases plan to introduce 3 new powerful Kafka analytics access patterns for application and BI developers.
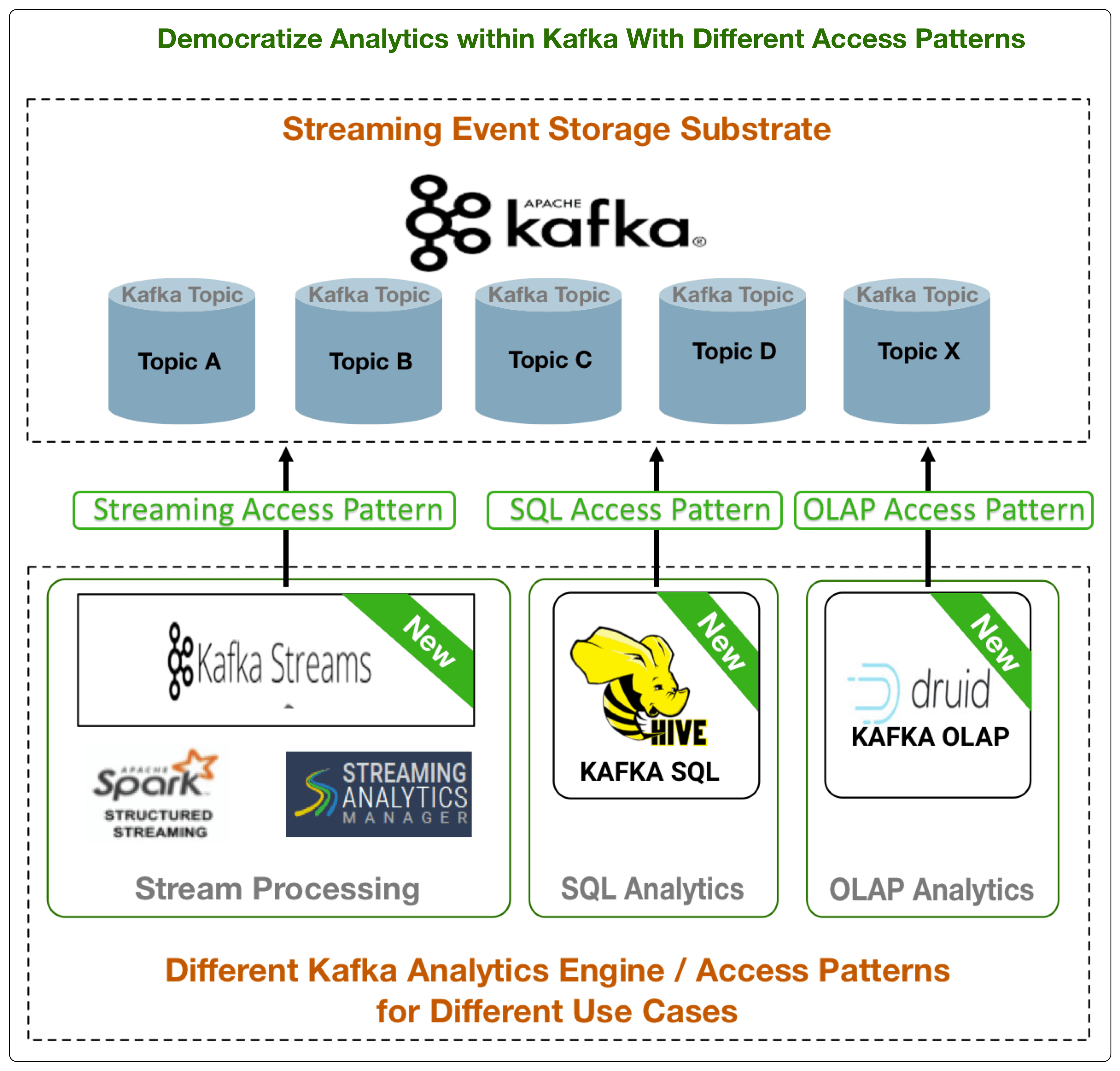
A summary of these three new access patterns:
- Stream Processing: Kafka Streams Support – With existing support for Spark Streaming, SAM/Storm, Kafka Streams addition provides developers with more options for their stream processing and microservice needs.
- SQL Analytics: New Hive Kafka Storage Handler – View Kafka topics as tables and execute SQL via Hive with full SQL Support for joins, windowing, aggregations, etc.
- OLAP Analytics: New Druid Kafka Indexing Service – View Kafka topics as cubes and perform OLAP style analytics on streaming events in Kafka using Druid.
Application Developer Persona: Secure and Governed Microservices with HDP/HDF Kafka Streams
HDP/HDF supports two stream processing engines: Spark Structured Streaming and Streaming Analytics Manager (SAM) with Storm. Based on the application non-functional requirements, our customers have the choice to pick right stream processing engine for their needs. Some of the key stream processing requirements we heard from our customers were the following:
- The choice to select the right stream processing engine for their set of requirements is important. Key non-functional requirements that drive the choice of engine include batching vs event-at-time processing, ease of use, exactly-once processing, handling late arriving data, state management support, scalability/performance, maturity, etc.
- The current two choices have limited capabilities when building streaming microservice apps.
- All stream processing engines should use a centralized set of platform services providing security (authentication/authorization), audit, governance, schema management and monitoring capabilities.
To address these requirements, support for Kafka Streams is being added in the upcoming HDP 3.1 and HDF 3.3 releases with full integration with security, governance, audit and schema management platform services.
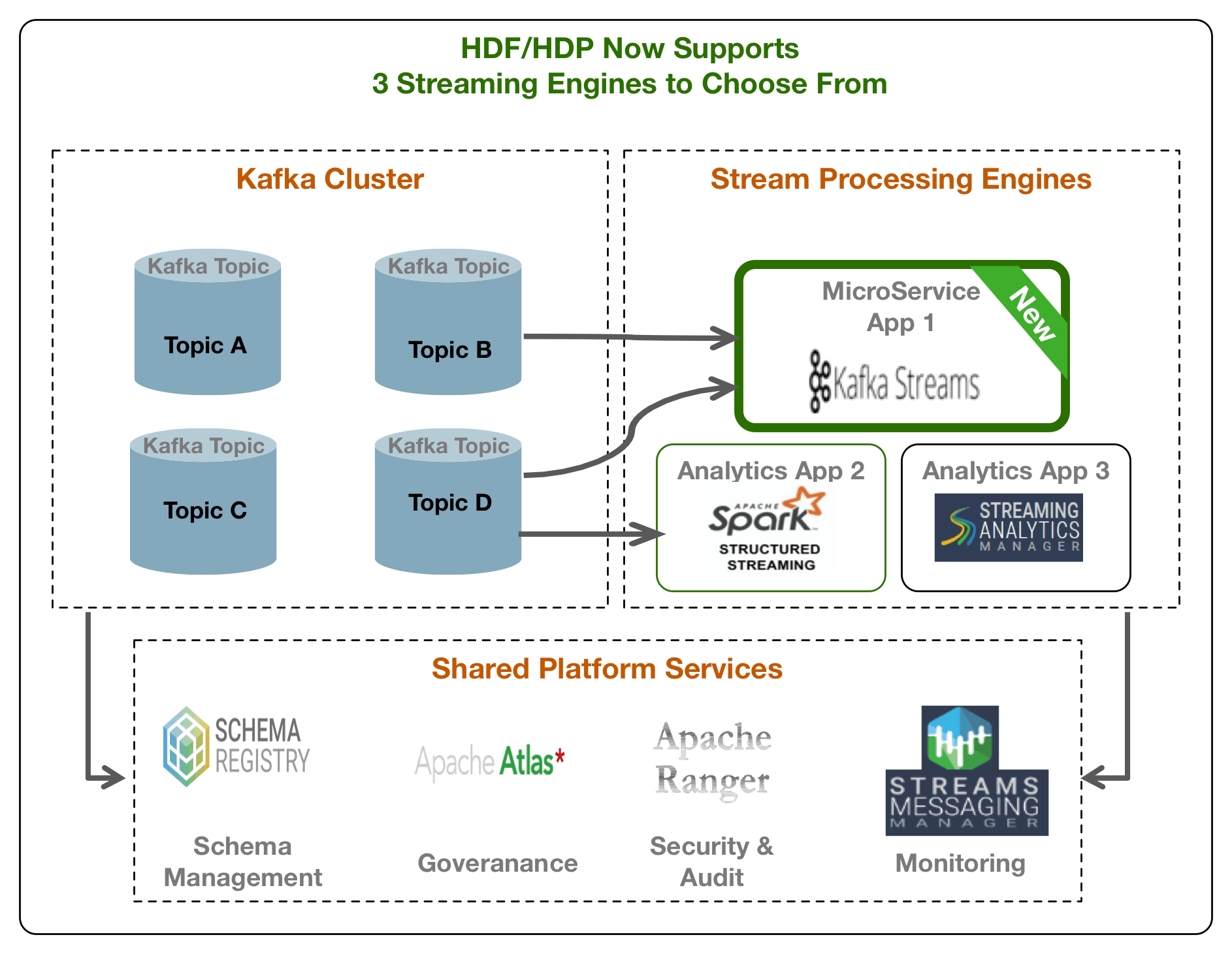
Kafka Streams integrated with Schema Registry, Atlas, Ranger and Stream Messaging Manager (SMM) now provides customers a comprehensive platform to build microservice apps addressing complex security, governance, audit and monitoring requirements.
BI Persona: Real SQL on Real Time Stream
The stream processing engines discussed above provide a programmatic stream processing access pattern to Kafka. Application developers love this access pattern but when you talk to BI developers, their analytics requirements are quite different which are focused on use cases around ad hoc analytics, data exploration and trend discovery. BI persona requirements for Kafka include:
- Treat Kafka topics/streams as tables
- Support for ANSI SQL
- Support complex joins (different join keys, multi-way join, join predicate to non-table keys, non-equi joins, multiple joins in the same query)
- UDF support for extensibility
- JDBC/ODBC support
- Creating views for column masking
- Rich ACL support including column level security
To address these requirements, the upcoming HDP 3.1 release will add a new Hive Storage Handler for Kafka which allows users to view Kafka topics as Hive tables. This new feature allows BI developers to take full advantage of Hive analytical operations/capabilities including complex joins, aggregations, UDFs, pushdown predicate filtering, windowing, etc.
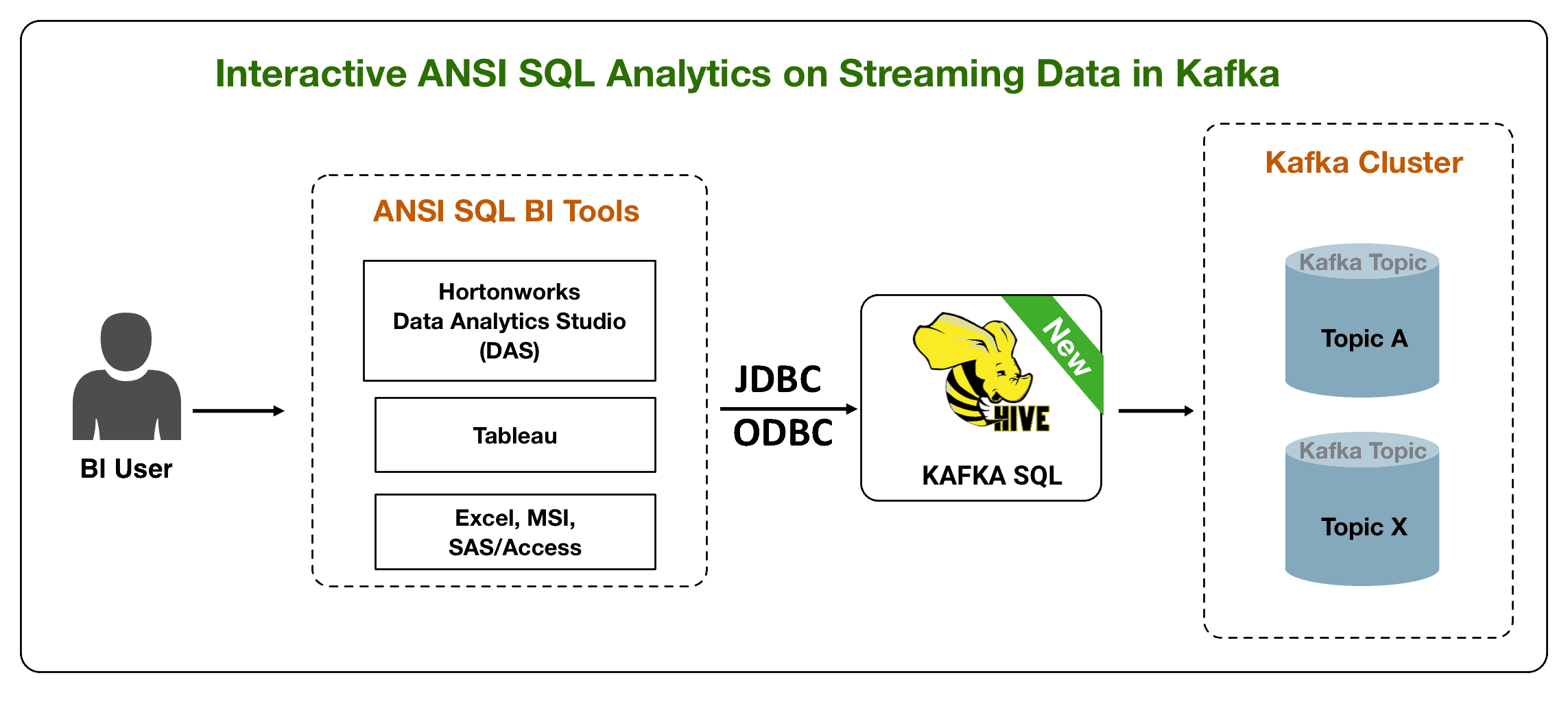
In addition, the new Hive Kafka storage handler is fully integrated with Ranger which provides powerful capabilities such as column level security. This is an exciting new feature as column level security on streaming events has been one of the most asked for features in Kafka.
Kafka + Druid + Hive = Powerful New Access Pattern for Streaming Data in Kafka
The new Hive SQL access to Kafka will allow BI developers to address whole set of new use cases for Kafka around data exploration, trend discovery and ad-hoc analytics. In addition to these use cases, customers also have requirements for high performance OLAP style analytics on streaming data in Kafka. Users want to use SQL and interactive dashboards to do rollups and aggregations on streaming data in Kafka.
To address these requirements, we will be adding a powerful new Druid Kafka index service managed by Hive which will be available in the upcoming HDP 3.1 release.
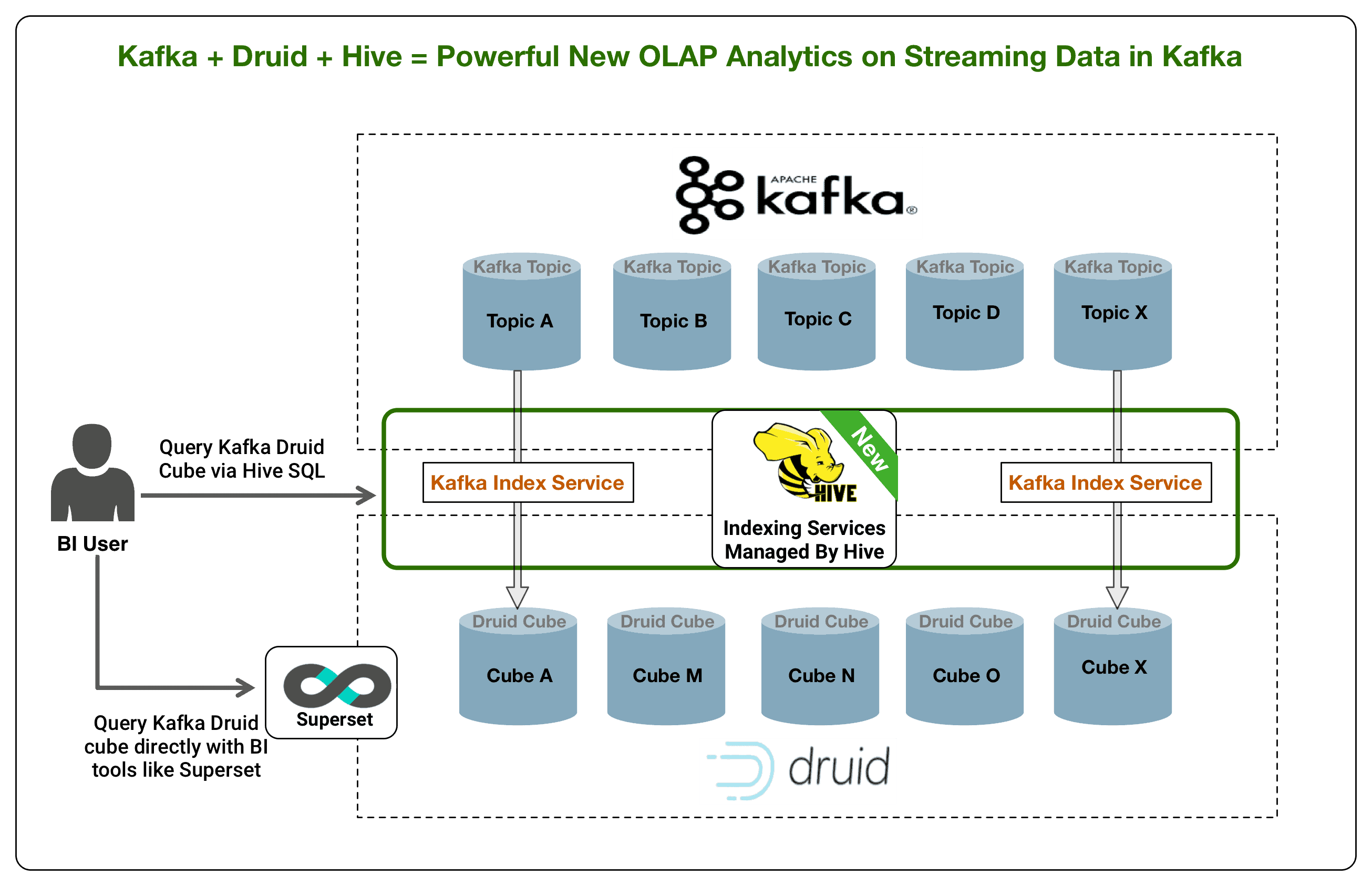
As the diagram above illustrates, a Kafka topic can be viewed as an OLAP cube. Apache Druid (incubating) is a high performance analytics data store for event-driven data. Druid combines ideas from OLAP/time series databases, and search systems to create a unified system for operational analytics. The new integration provides a new Druid Kafka indexing service that indexes the stream data in a Kafka topic into a Druid cube. The indexing service can be managed by Hive as an external table providing SQL interface to the Druid cube backed by Kafka topic.
What’s Next?
This blog was intended to give you a sneak peak at the three new powerful Kafka analytics access patterns that will soon be available in HDP 3.1 and HDF 3.3. This will be the first installment in this Kafka Analytics blog series. Subsequent blogs in this series will walk through each of these access patterns in more detail. Stay tuned!
Editor's Choice

