


CDP Operational Database (COD) is a real-time auto-scaling operational database powered by Apache HBase and Apache Phoenix. It is one of the main Data Services that runs on Cloudera Data Platform (CDP) Public Cloud. You can access COD right from your CDP console. With COD, application developers can now leverage the power of HBase and Phoenix without the overheads related to deployment and management. COD is easy-to-provision and is autonomous, that means developers can provision a new database instance within minutes and start creating prototypes quickly. Autonomous features like auto-scaling ensure there’s no management and administration of the database to worry about.
In this blog, we’ll share how CDP Operational Database can deliver high performance for your applications when running on AWS S3.
CDP Operational Database allows developers to use Amazon Simple Storage Service (S3) as its main persistence layer for saving table data. The main advantage of using S3 is that it is an affordable and deep storage layer.
One core component of CDP Operational Database, Apache HBase has been in the Hadoop ecosystem since 2008 and was optimised to run on HDFS. Cloudera’s OpDB (including HBase) provides support for using S3 since February 2021. Feedback from customers is that they love the idea of using HBase on S3 but want the performance of HBase when deployed on HDFS. Their application SLAs get significantly violated when their performance is limited to the performance of S3.
Cloudera is in the process of releasing several configurations that provide an HBase that has performance on parity as with traditional HBase deployments that leverage HDFS.
We tested performance using the YCSB benchmarking tool on CDP Operational Database (COD) in 4 configurations:
- COD using m5.2xlarge instances HBase, storage as S3
- COD using m5.2xlarge instances and HBase using EBS (st1) based HDFS
- COD using m5.2xlarge instances and HBase using EBS (gp2) based HDFS
- COD using I3.2xlarge instances, storage as S3 and 1.6TB file-based cache per worker hosted on SSD based ephemeral storage
Based on our analysis, we found that
- Configuration #4 was the most cost effective providing 50-100X performance vs configuration #1 when cache was prewarmed 100% and 4X performance improvement when the cache was only 50% full, so for our analysis, we discounted running configuration #1 as it is not sufficiently performant for any non-disaster recovery related use case.
- Based on our YCSB workload runtimes the price performance of EBS General Purpose SSD (gp2) is 4X-5X times compared to EBS Throughput Optimized HDD (st1) (AWS EBS pricing https://aws.amazon.com/ebs/pricing/)
When comparing configuration #2-#4, we find that configuration #4 (1.6 TB cache / node) has the best performance after the cache is 100% pre-warmed.
AWS EC2 instance configurations
Test Environment
- Yahoo! Cloud Serving Benchmark (YCSB) standard workloads were used for testing:
- YCSB Workloads run were:
- Workload A (50% Read 50% Update)
- Workload C (100% Read)
- Workload F (50% Read 25% Update 25% Read-Modify-Update)
- Dataset size 1TB
- Cluster size
- 2 Master (m5.2xl / m5.8xl)
- 5 Region Server Worker nodes (m5.2xl / i3.2xl)
- 1 Gateway node (m5.2xl)
- 1 Leader node (m5.2xl)
- Environment version
- COD version 1.14
- CDH 7.2.10
- Each YCSB workload was run for 900 sec
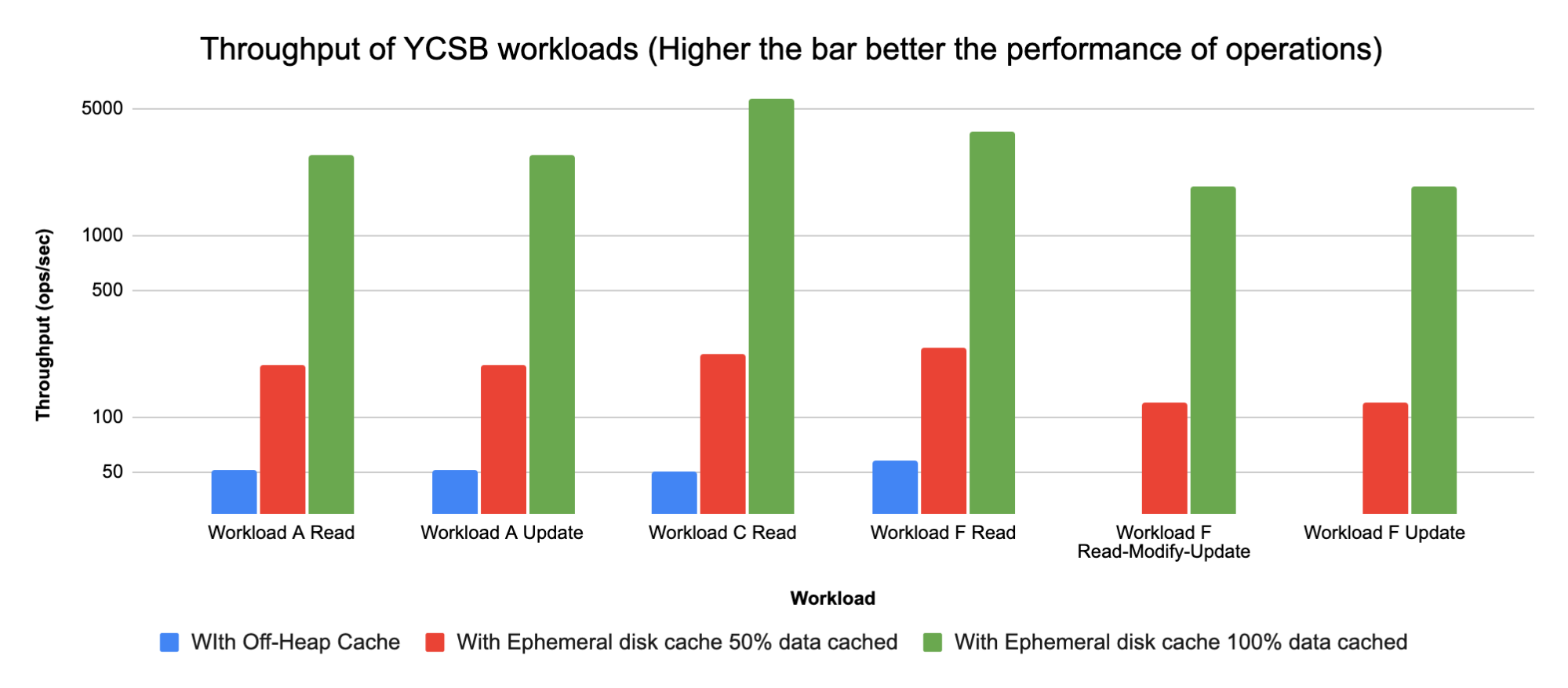
We compared the YCSB runs on the configurations below:
- COD using m5.2xls and off-heap 6G bucket cache with S3 store
- COD using i3.2xls (instances with ephemeral storage) and 1.6TB file-based bucket cache with S3 store using SSD Ephemeral Storage
- Case 1: 50% data cached
- Case 2: 100% data cached
Sharing a chart to show Throughput of the YCSB workloads run for the different configurations below:
Note: Throughput = Total operations/Total time (ops/sec)
The following chart shows the same comparison using Log values of total YCSB operations. Plotting log values on Y axis helps in seeing values in graph which are much smaller than other values. Example: The throughput values in the 6GB off-heap case as seen above are difficult to see in comparison to throughput with 1.6 TB Ephemeral disk caching, and taking log values for the same helps see the comparison in the graph:
Analysis
- Using 1.6TB File Based Bucket Cache on every region server allows up to 100% caching of data in our case with 1TB total data size vs using 6GB off-heap cache on m5.2xls instance when using S3 store
- Seeing a 50-100X increase in YCSB workloads (A, C, F) performance with 100% data cached on 1.6TB Ephemeral disk cache vs 6G off-heap memory cache with S3 store
- Seeing a 4X increase in YCSB workloads (A, C, F) performance with 50% data cached on 1.6TB Ephemeral disk cache vs 6G off-heap memory cache with S3 store
Using HBase root-dir on HDFS on EBS
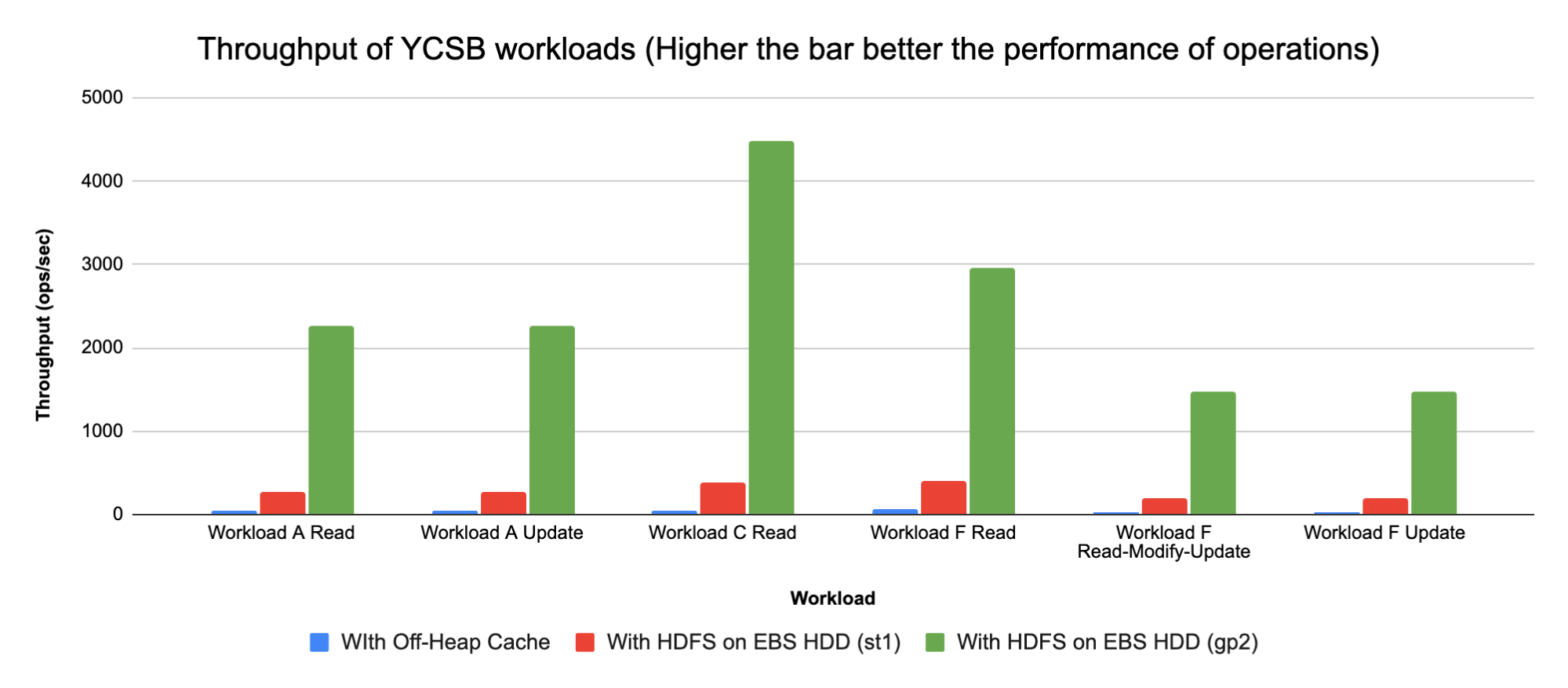
We compared YCSB runs on the configurations below:
- COD using m5.2xls AWS S3 storage and off-heap 6G bucket cache
- COD using m5.2xlarge instances and HBase using EBS based HDFS, EBS volume types used:
- Throughput Optimized HDD (st1)
- General Purpose SSD (gp2)
Sharing a chart to show Throughput of the YCSB workloads run for the different configurations below:
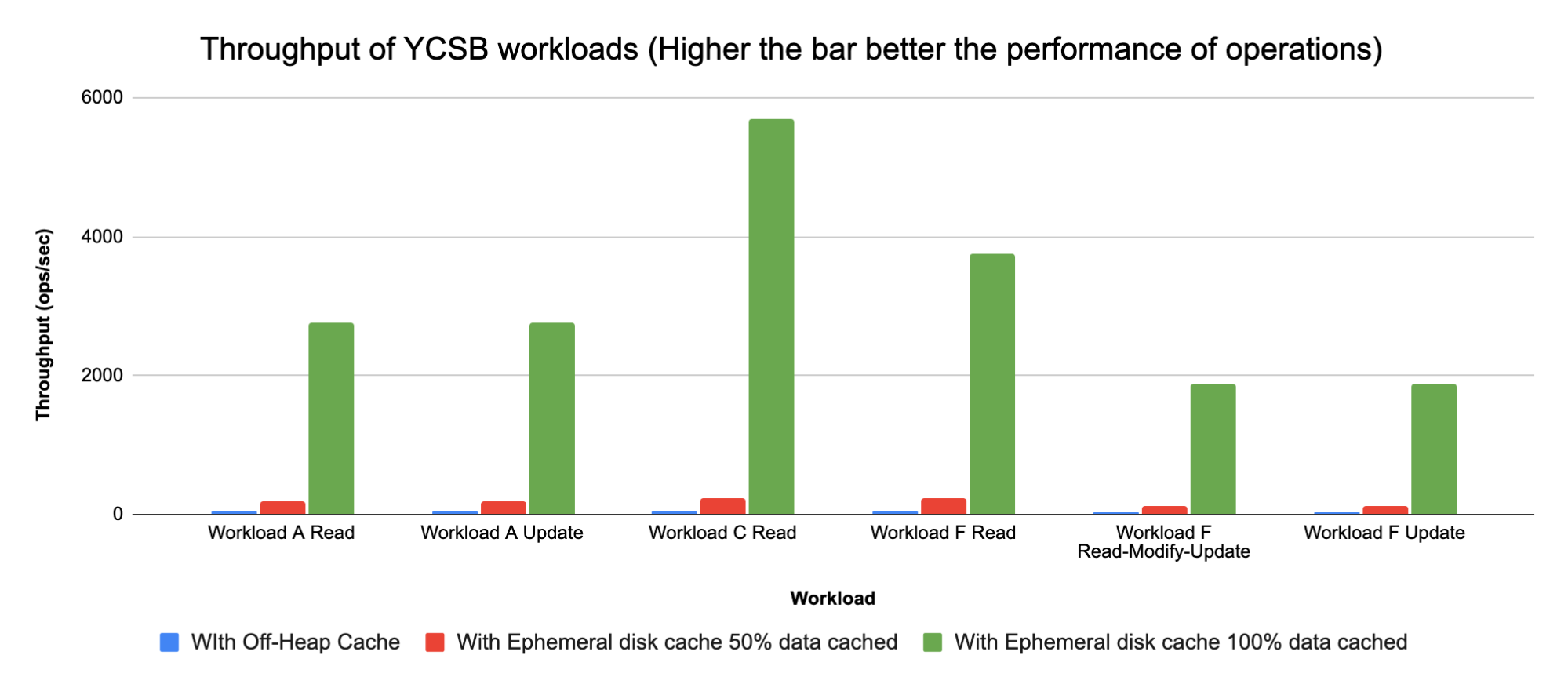
Note: Throughput = Total operations/Total time (ops/sec)
The following chart shows the same comparison using Log values of total YCSB operations. Plotting log values on Y axis helps in seeing values in graph which are much smaller than other values. Example: The throughput values in the 6GB off-heap case as seen above are difficult to see in comparison to throughput with HDFS on EBS, and taking log values for the same helps see the comparison in the graph:
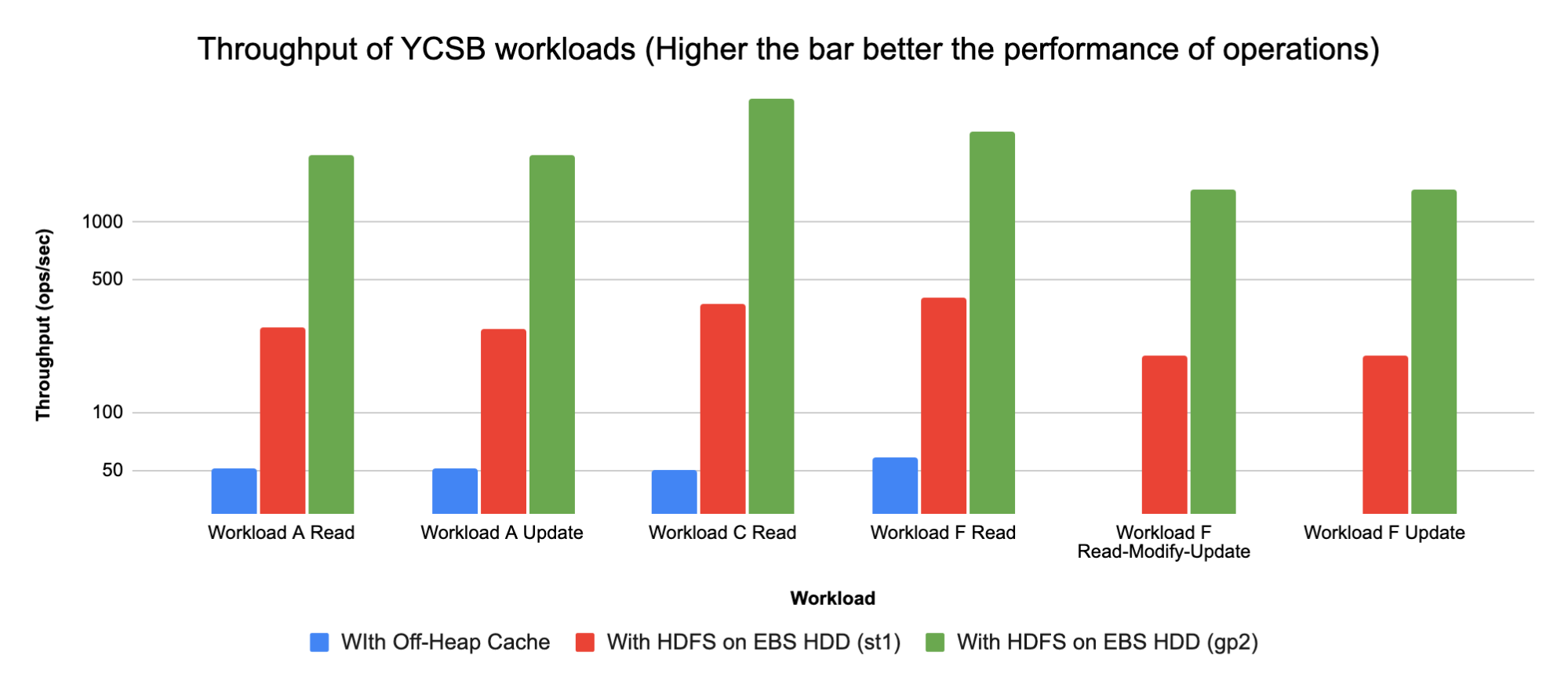
Analysis
- Using HDFS based HBase root-dir saves on AWS S3 latency
- Seeing a 40-80X increase in performance with HBase root dir on HDFS using SSD (EBS) vs AWS S3 storage
- Seeing a 5X-8X increase in performance with HBase root dir on HDFS using HDD (EBS) vs AWS S3 storage
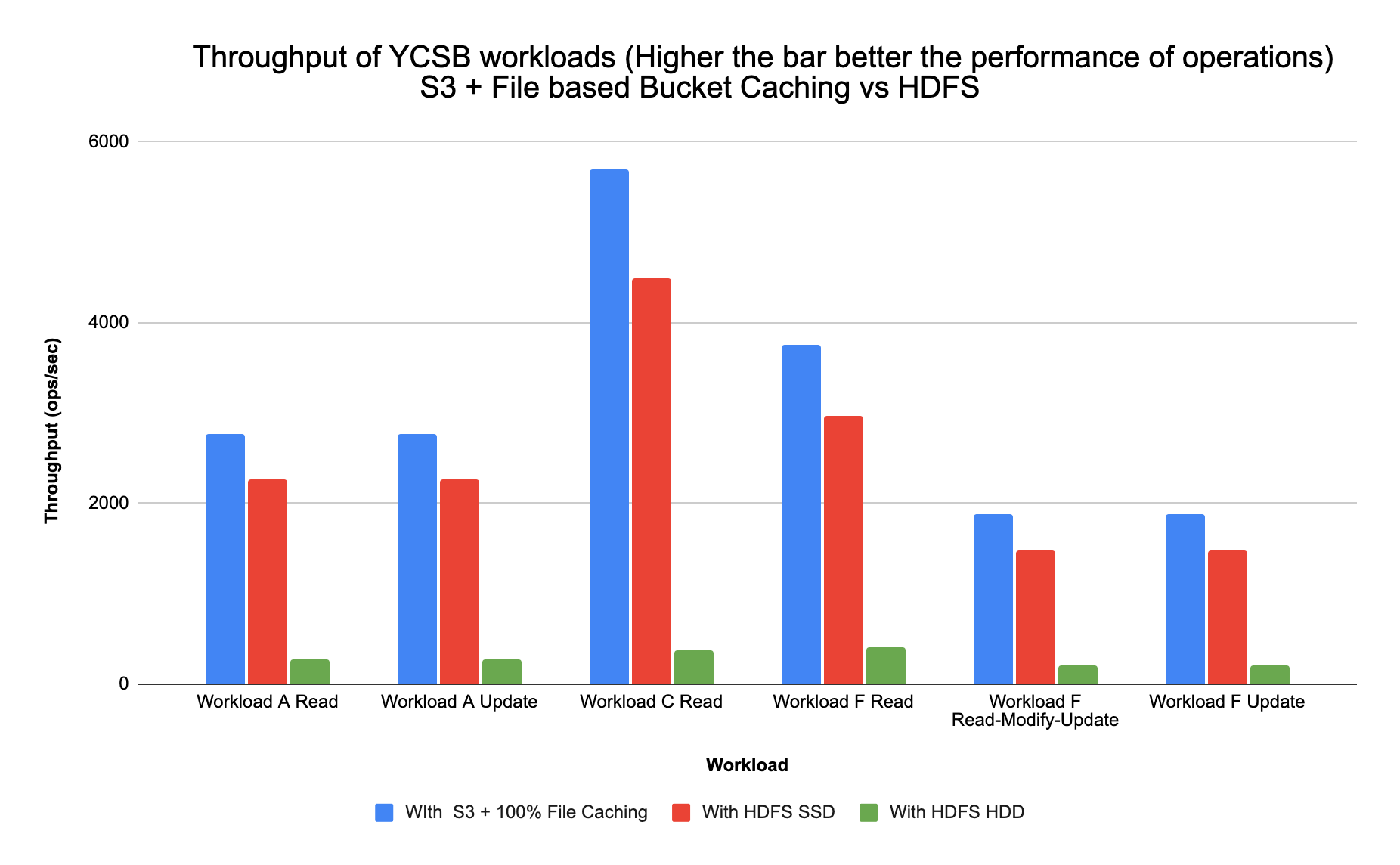
Comparing S3 with File Based Bucket Cache vs HDFS on SSD vs HDFS on HDD
Sharing a chart to show Throughput of the YCSB workloads run for the different configurations below:
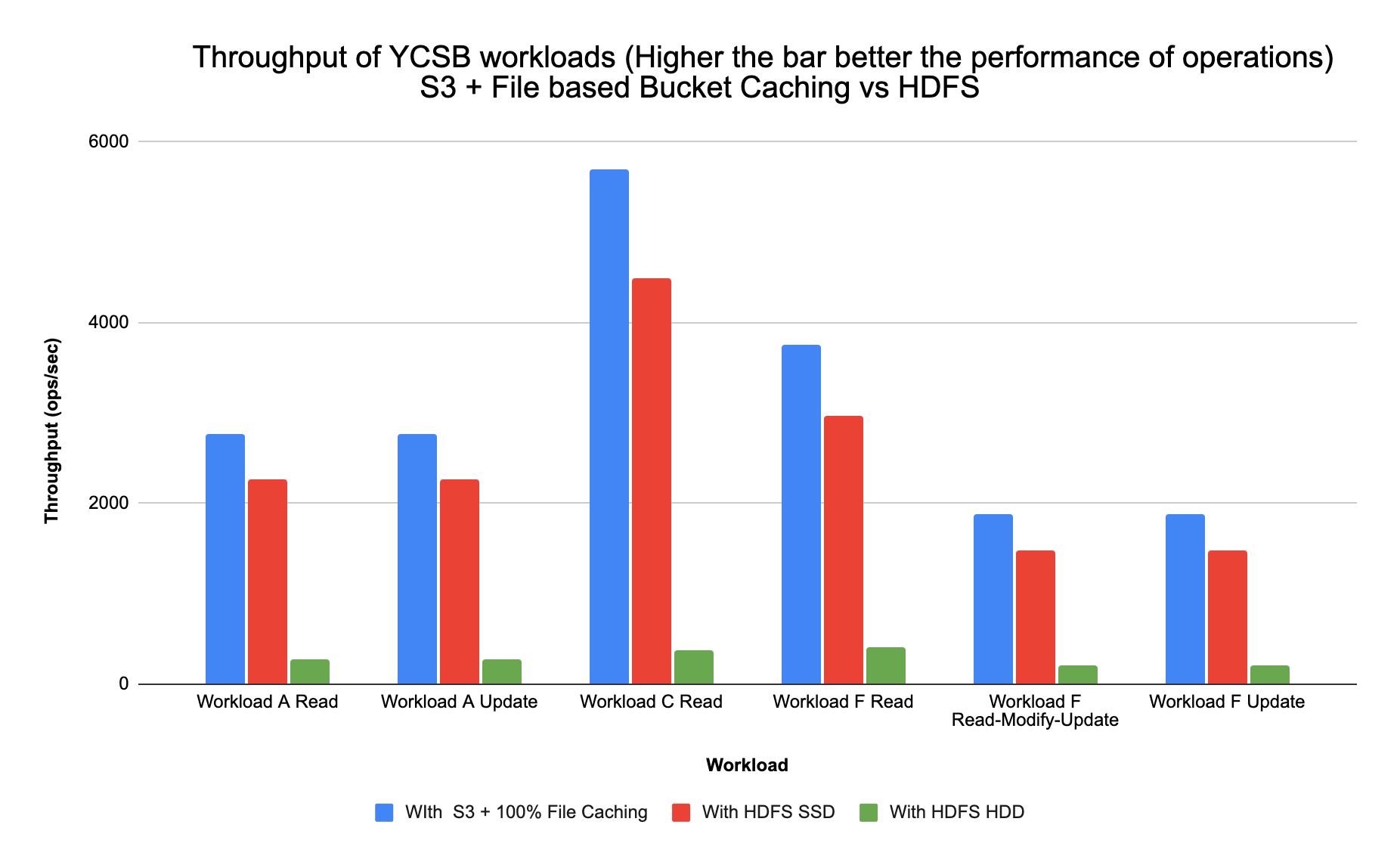
Note: Throughput = Total operations/Total time (ops/sec)
Configuration Analysis
We compared the performance of the 3 below config options in AWS:
- COD Cluster using S3 store with 1.6TB File Based Bucket Cache (using Ephemeral instances)
- COD Cluster using gp2 block store – HDFS on SSD (EBS)
- COD Cluster using st1 block store – HDFS on HDD (EBS)
Out of the 3 options, the below configurations give the best performance compared to using AWS S3 with off-heap block cache:
- AWS S3 store with 1.6 TB File Based Bucket Cache (using Ephemeral instances i3.2xls) performance increase is 50X – 100X for read heavy workloads with 100% cached data vs using m5.2xls with 6GB off-heap in memory block cache
- Gp2 Block store – Using m5.2xl instances HDFS on SSD (EBS) performance increase is 40X – 80X for read heavy workloads vs using m5.2xls with 6GB off-heap in memory block cache
How do we select the right configuration to run our CDP Operational Database?
- When datasets are infrequently updated, the data can be cached to reduce latency of network access to S3. Using S3 with a large file based bucket cache (with ephemeral instances) is more effective for read-heavy workloads
- When datasets are frequently updated, the latency of access to S3 to cache newly written blocks can impact application performance, and selecting HDFS on SSDs would be an effective choice for read-heavy workloads.
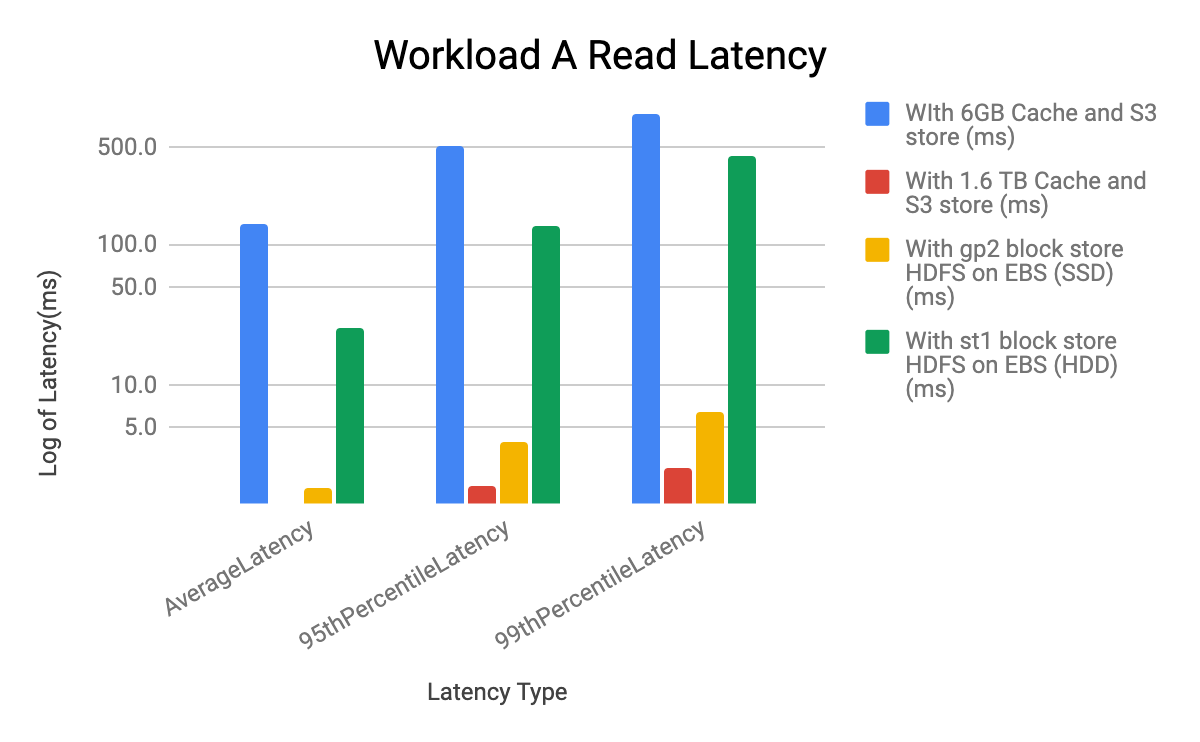
Workload Latency
Comparing Ephemeral File Cache with S3 store vs EBS block store (HDFS)
- The latency impact of different configurations on all the YCSB workloads A, C and F is seen in the Read latency and performance
- The Update latency is very similar in all the configurations for YCSB workloads A, C and F
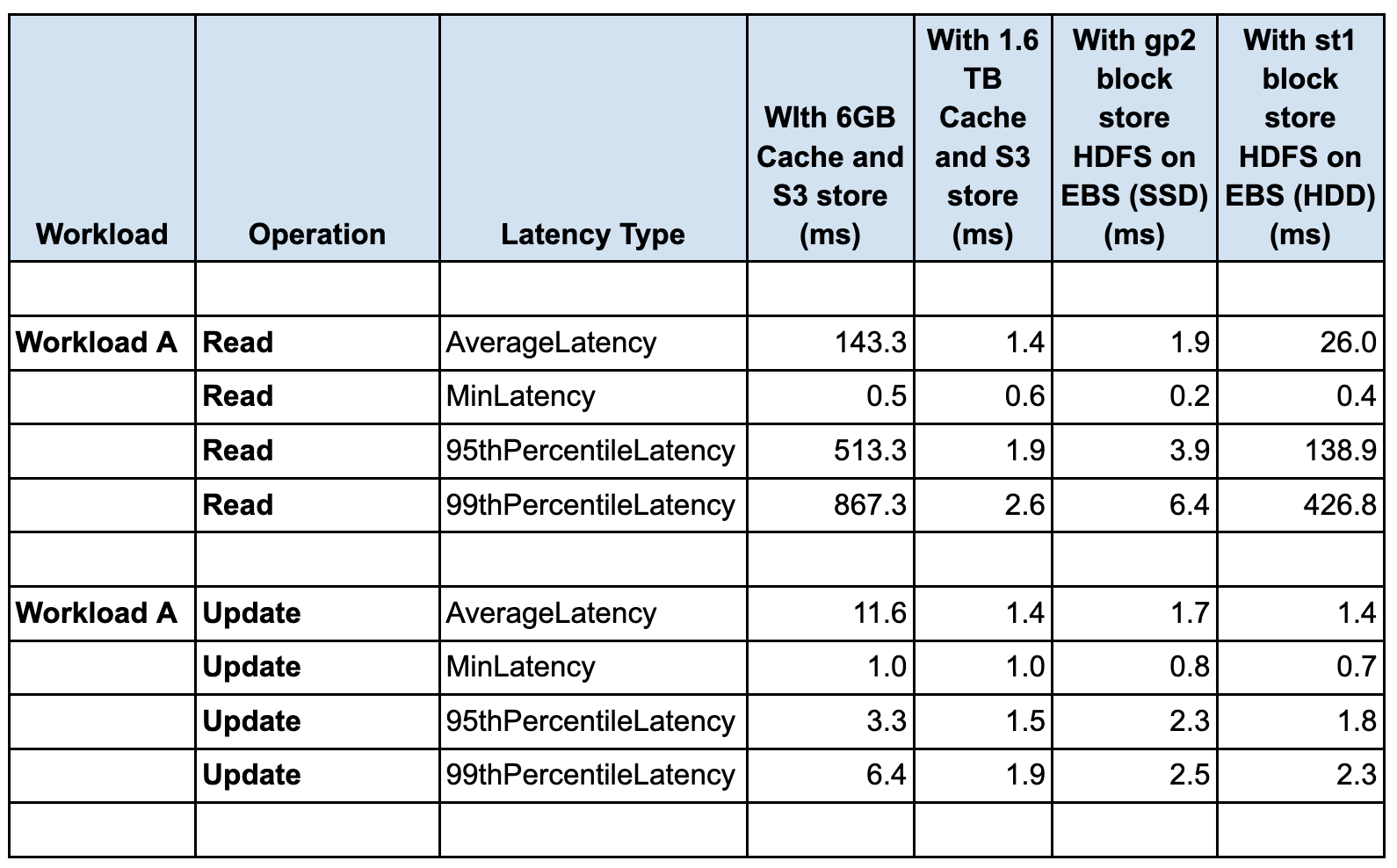
Workload A
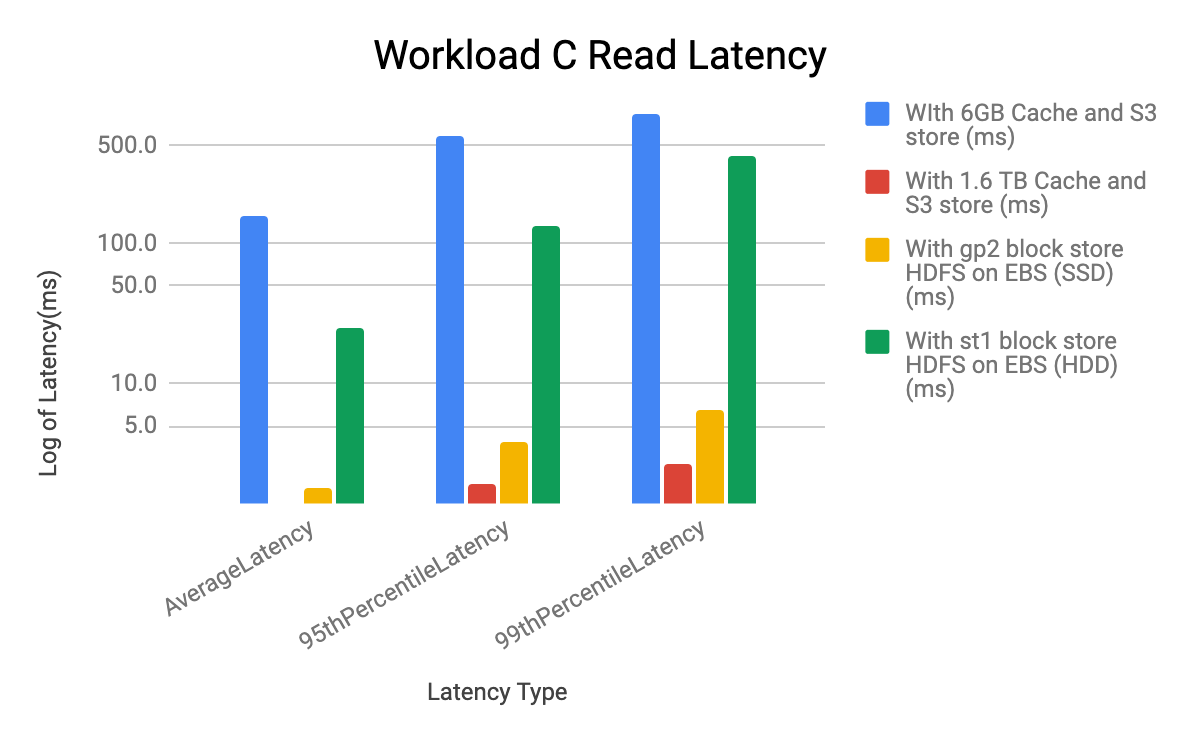
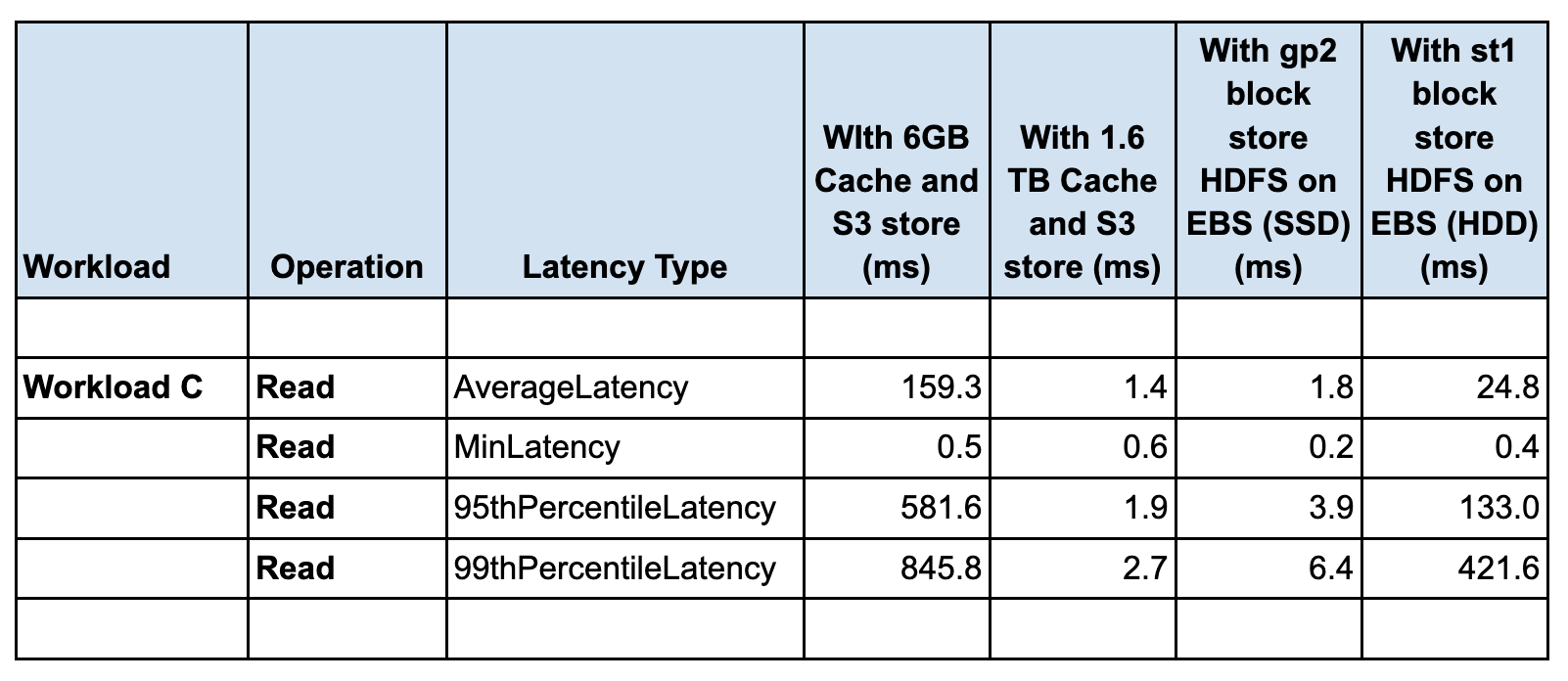
Workload C
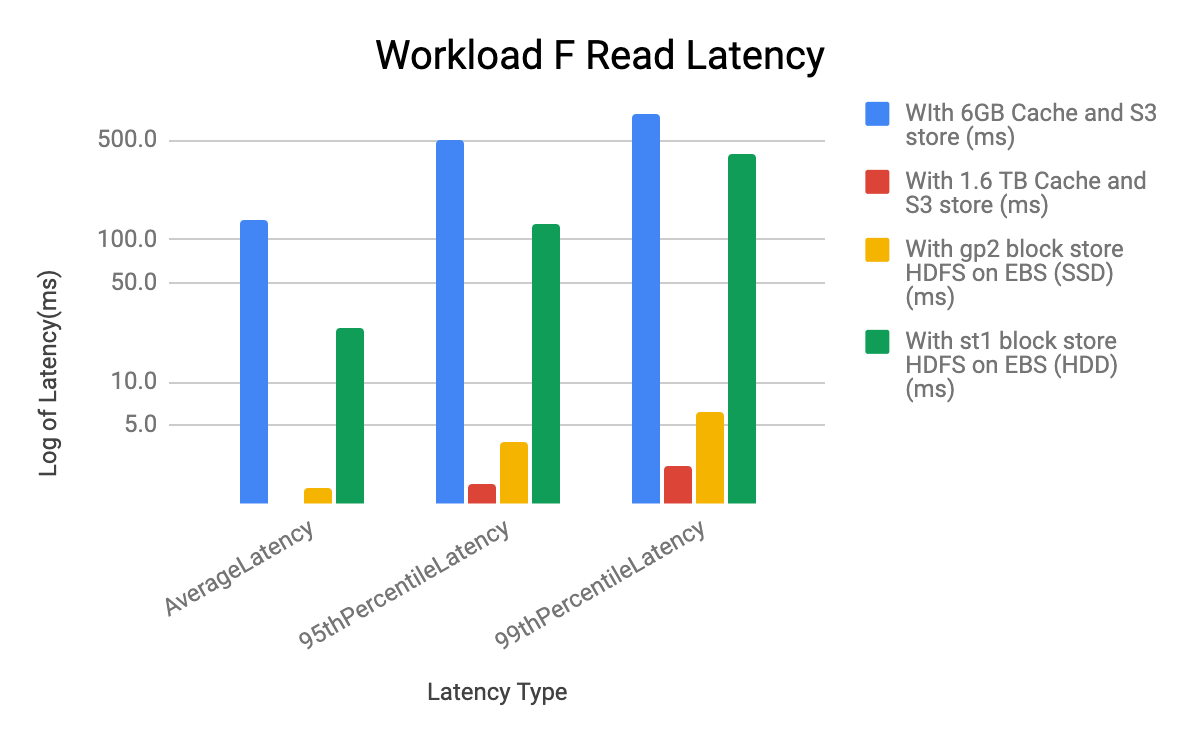
Workload F
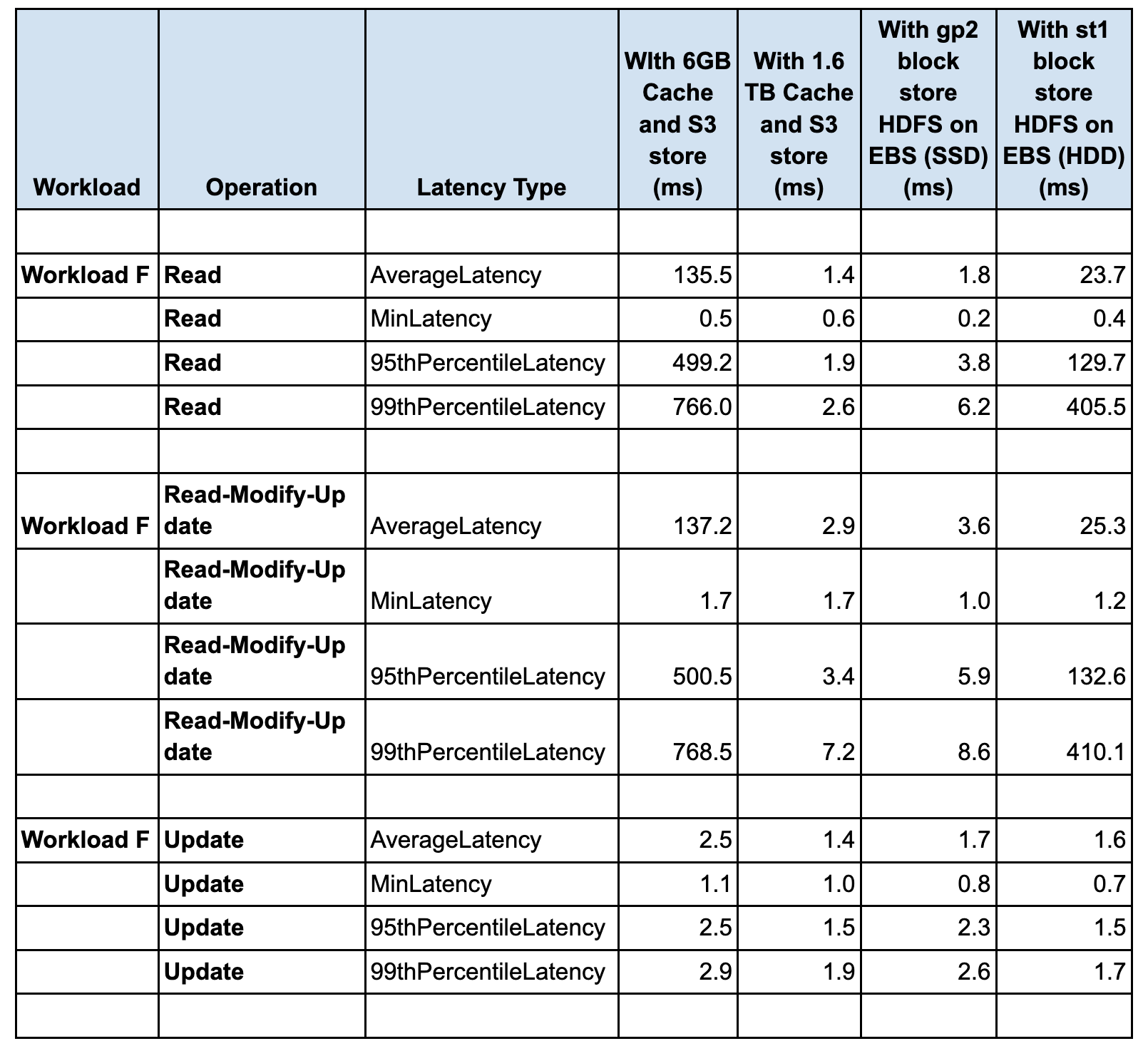
YCSB Workload A, C and F Latency Analysis
- The latency impact of different configurations on all the YCSB workloads A, C and F is seen in the Read latency and performance
- The Update latency is very similar in all the configurations for YCSB workloads A, C and F
- The lowest (best and the highest throughput) READ latency is seen in the case of 1.6TB disk cache with S3 store, followed by using gp2 block store (HDFS on EBS SSD). The highest (worst and the lowest throughput) READ latency is seen in the case of 6G cache with S3 store.The latency for st1 block store (HDFS on EBS HDD) is higher than gp2 block store (HDFS on EBS SSD), with higher latency with st1, throughput seen with st1 HDD is lower than throughput seen with gp2 SSD
- HDFS on EBS HDD throughput is higher than the 6G cache with S3 store by 4-5X. Both cases are using m5.2xl instances
- For Workload F the Read-Modify-Update latency is dominated by the READ latency
AWS Configuration Recommendations
Repetitive-read heavy workload:
If workload requests the same data multiple times or needs to accelerate latency and throughput for some part of the data set, COD with large cache on ephemeral storage is recommended. This will also reduce the cost of repetitive calls to S3 for the same data.
Read-heavy and latency-sensitive workloads:
If the workload expects a uniform and predictable read latency across all its requests, we recommend HDFS as a storage option. If applications are very sensitive to latency(99th percentile <10ms), COD on HDFS with SSDs is recommended and if latency SLA for 99th percentile is under 450ms acceptable then HDFS with HDD is recommended to save 2x on storage cost when compared to SSDs
Write heavy workloads:
If workloads are neither read-heavy nor latency-sensitive, which means they are heavy on writes, COD on cloud storage (S3) is recommended.
If you are interested in trying out an Operational Database, try out our Test Drive.
Editor's Choice


I have been browsing online more than three hours lately, but I by no means found any interesting article like yours. It’s beautiful worth enough for me. In my view, if all website owners and bloggers made excellent content as you probably did, the internet will be a lot more helpful than ever before.
Holly Hooper