

This blog post was published on Hortonworks.com before the merger with Cloudera. Some links, resources, or references may no longer be accurate.
What is a Data Science and Engineering Platform
Apache Spark is one of our most popular workloads- both on-premises and cloud. As we recently announced HDP 3.0.0 (followed by a hardened HDP 3.0.1), we want to introduce the Data Science and Engineering Platform powered by Apache Spark.
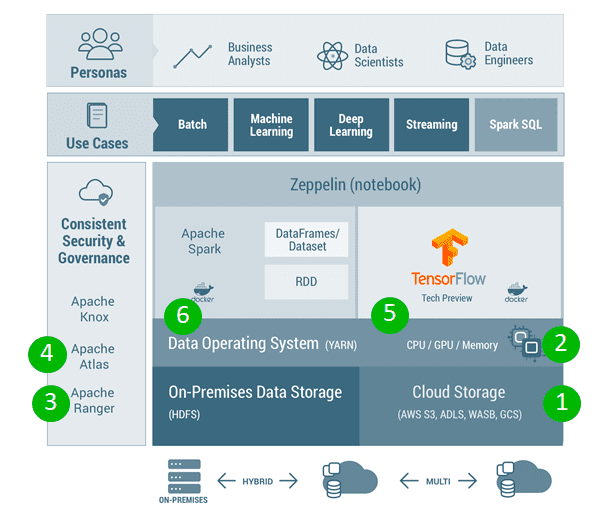
As noted in the marketecture above, our Data Science & Engineering Platform is powered by Apache Spark with Apache Zeppelin notebooks to enable Batch, Machine Learning, and Streaming use cases, by personas such as Data Engineers, Data Scientists and Business Analysts. We recently introduced Apache TensorFlow 1.8 as a tech preview feature in HDP 3.0.x to enable the deep learning use cases – while this is intended for proof of concept deployments, we also support BYO dockerized TensorFlow in production environments. Some of the reasons our customers choose our Data Science and Engineering Platform on HDP 3.0 are:
- Hybrid and Cloud Ready – Deployable in on-premises and optimized for multi-cloud environments (Amazon Web Services, Microsoft Azure, Google Cloud) with consistency improvements
- Elastic and Scalable – Best in class features and enterprise hardened features with YARN
- Enterprise Security – Kerberos, Encryption and Ranger based security (Row/Column level security)
- Comprehensive Governance – Data lineage for Spark across all use cases
- Deep Learning Capable – Containerized TensorFlow and hardware acceleration via advanced GPU support
- Developer Agility – Dockerized Spark support to bring your own packages and achieve isolation
What’s New in HDP 3.0 for Data Science and Engineering
We recently upgraded versions of Apache Spark and Zeppelin to Spark 2.3, Zeppelin 0.8 and added a new deep learning framework -TensorFlow 1.8 (tech preview) to HDP 3.0. Some of the highlighted features are:
- Latest version
- Spark 2.3 with ecosystem support for Zeppelin, Livy, HBase, Kafka etc
- Cloud
- Consistency improvements for Spark with Spark S3 connector (commit protocol and S3 guard)
- Dockerized Spark for Packaging/Isolation
- Dockerized Spark executor on YARN, with dependent python versions and python libraries
- Deep Learning
- TensorFlow 1.8 Tech Preview with YARN GPU Pooling
- Streaming Workloads
- Streaming ingestion into Apache Hive tables with ACID support
- Stream-stream joins
- Data Lineage
- Apache Atlas integration to provide transparent lineage for Spark jobs across batch, streaming, machine learning and across HDFS, Hive, Hbase and Kafka data sources
- Security
- Knox SSO/proxy support for Spark history server and Zeppelin
- Spark-hive connector for access to Hive ACID tables and row/column level security via Apache Ranger
- Notebook
- Zeppelin 0.8; support per notebook interpreter configuration
- Performance
- Vectorization and performance with native ORC integration
- Pandas UDFs support
Highlighting Key Use Cases
We cover a gamut of use cases and please keep an eye for additional blogs highlighting the use cases. We will briefly cover 3 interesting use cases, enabled with HDP 3.0.
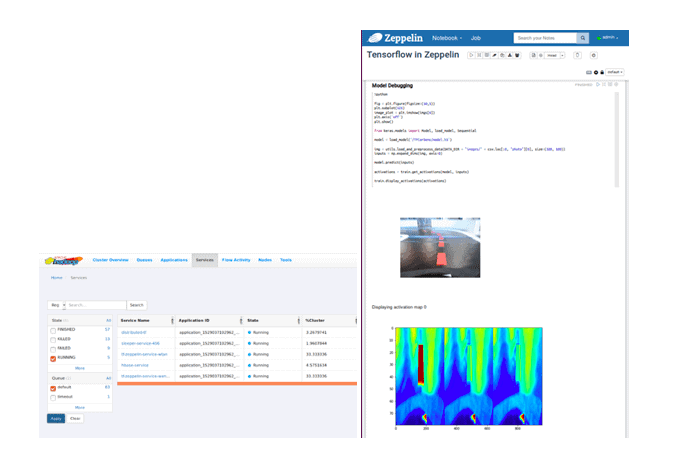
Deep Learning – An Autonomous 1/10 Scale Car Following a Lane
We leverage the power of HDP 3.0 from efficient storage (erasure coding), GPU pooling to containerized TensorFlow and Zeppelin to enable this use case. We will the save the details for a different blog (please see the video)- to summarize, as we trained the car on a track, we collected about 30K images with corresponding steering angle data. The training data was stored in a HDP 3.0 cluster and the TensorFlow model was trained using 6 GPU cards and then the model was deployed back on the car. The deep learning use case highlights the combined power of HDP 3.0.
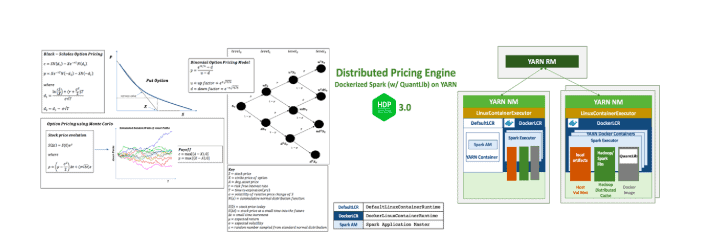
Dockerized Spark – An example with QuantLib – Derivative Pricing
This use case is covered in detail in an earlier blog. We can enable our data scientists to lift and shift their own custom libraries (Python/R libraries, custom libraries) in a docker container and run with Spark executors. This is immensely powerful and allows multiple data scientists to have their sandbox environments without running into runtime conflicts or platform friction. Please refer to this blog for the instructions to run dockerized Spark executors.
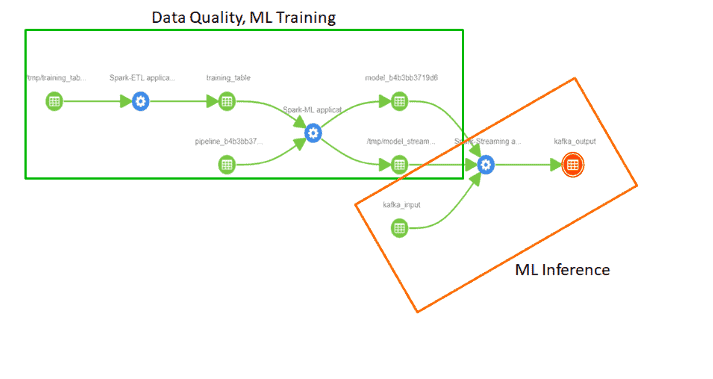
Governance for Spark – Lineage for Data and Applications
Spark jobs are becoming the mainstay of enterprise data processing applications. They are used to access data across a variety of sources like Apache HDFS, Hive, Kafka, HBase and across scenarios like batch, streaming, machine learning. A challenge for enterprises is to understand all the complex and implicit dependencies across all this processing. With Apache Atlas integration (tech preview), these dependencies are automatically tracked and can be used to determine data quality issues and provenance. This includes ML capabilities like how a model was trained and then used for scoring. This is crucial for auditing and repeatability in the current privacy sensitive and GDPR climate.
The following graphic is showing a machine learning end to end flow executed using Spark being automatically tracked in Atlas. It starts with a batch ETL Spark job transforming data from HDFS into a SQL table. A Spark model training job uses the SQL table training data to create a Spark ML model. That model is used in a Spark streaming job to continuously score incoming data from Kafka topics.
What is Next?
We are seeing that Apache Spark is increasingly used in large distributed production environments and missed SLAs are becoming a problem. Our customers are asking us to help them debug and optimize their Spark jobs so that they don’t waste resources and run as optimally as possible. We are working on some really exciting concepts with a select few customers and please look out for our blog on Spark Application Performance Management!
Also stay tuned for blogs highlighting additional use cases that can be powered by data science and engineering capabilities in HDP.
Editor's Choice

