





We are excited to announce a tech preview of Cloudera AI Inference service powered by the full-stack NVIDIA accelerated computing platform, which includes NVIDIA NIM inference microservices, part of the NVIDIA AI Enterprise software platform for generative AI. Cloudera’s AI Inference service uniquely streamlines the deployment and management of large-scale AI models, delivering high performance and efficiency while maintaining strict privacy and security standards.
It integrates seamlessly with our recently launched AI Registry, a central hub for storing, organizing, and tracking machine learning models throughout their lifecycle.
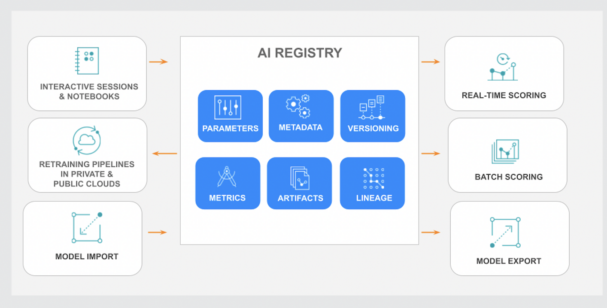
Cloudera AI Registry: Centralized Model Management
By combining the AI Registry with advanced inference capabilities, Cloudera provides a comprehensive solution for modern MLOps, enabling enterprises to efficiently manage, govern, and deploy models of any size across public and private clouds.
The new AI Inference service offers accelerated model serving powered by NVIDIA Tensor Core GPUs, enabling enterprises to deploy and scale AI applications with unprecedented speed and efficiency. Additionally, by leveraging the NVIDIA NeMo platform and optimized versions of open-source LLMs like LLama3 and Mistral models, enterprises can take advantage of the latest advancements in natural language processing, computer vision, and other AI domains.

Cloudera AI Inference: Scalable and Secure Model Serving
Key Features of Cloudera AI Inference service:
- Hybrid cloud support: Run workloads on premises or in the cloud, depending on specific needs and requirements, making it suitable for enterprises with complex data architectures or regulatory constraints.
- Platform-as-a-Service (PaaS) Privacy: Enterprises have the flexibility to deploy models directly within their own Virtual Private Cloud (VPC), providing an additional layer of protection and control.
- Real-time monitoring: Gain insights into the performance of models, enabling quick identification and resolution of issues.
- Performance optimizations: Up to 3.7x throughput increase for CPU-based inferences and up to 36x faster performance for NVIDIA GPU-based inferences.
- Scalability and high availability: Scale-to-zero autoscaling and HA support for hundreds of production models, ensuring efficient resource management and optimal performance under heavy load.
- Advanced deployment patterns: A/B testing and canary rollout/rollback allow gradual deployment of new model versions and controlled measurement of their impact, minimizing risk and ensuring smooth transitions.
- Enterprise-grade security: Service Accounts, Access Control, Lineage, and Audit features maintain tight control over model and data access, ensuring the security of sensitive information.
The tech preview of the Cloudera AI Inference service provides early access to these powerful enterprise AI model serving and MLOps capabilities. By combining Cloudera’s data management expertise with cutting-edge NVIDIA technologies, this service enables organizations to unlock the potential of their data and drive meaningful outcomes through generative AI. With its comprehensive feature set, robust performance, and commitment to privacy and security, the AI Inference service is critical for enterprises that want to reap the benefits of AI models of any size in production environments.
To learn more about how Cloudera and NVIDIA are partnering to expand GenAI capabilities with NVIDIA microservices, read our recent press release.
Editor's Choice

