


In our previous blog, we talked about the four paths to Cloudera Data Platform.
- In-place Upgrade
- Sidecar Migration
- Rolling Sidecar Migration
- Migrating to Cloud
If you haven’t read that yet, we invite you to take a moment and run through the scenarios in that blog. The four strategies will be relevant throughout the rest of this discussion. Today, we’ll discuss an example of how you might make this decision for a cluster using a “round of elimination” process based on our decision workflow.
Choosing your path
As we touched on in the previous blog, the decision to upgrade or migrate may seem difficult to evaluate at first glance. Every customer has a unique situation and set of requirements specific to how their business works. When we look at the entire fleet of installed clusters, we’ve identified some common patterns that affect all customers.
These requirement patterns include:
- Runtime and availability Service Level Agreements (SLAs)
- Budgetary limitations
- Hardware or physical limitations
- The complexity of workload and data dependencies
- Tenant experience level and cross-tenant interactions
- Maturity of the development workflow and change governance
Runtime and Availability SLAs
Every customer is concerned with answering two important SLA questions:
- How long will my environment be down and unusable for business processes?
- How can I make that shorter?
If your primary concern is keeping the maintenance window as short as possible, such as a few minutes to less than a few hours, then we would suggest using one of the Migration methods, moving workloads to new CDP clusters on-premises or in the cloud. But, this has the side effect of introducing more hardware cost, in the case of a Side-car Migration, or more overall planning and effort in a Rolling Side-car Migration. The preparation work for a Migration may still take time to stage data, set up workloads, and validate dependencies. Still, the actual cutover from the legacy environment to CDP is treated like a flip of a switch.
In the case of In-place Upgrades, cluster size also impacts this question. A 1000 node cluster simply takes longer than a 100 node cluster to upgrade. Conversely, a cluster with 1000 workloads running across dozens of Hive databases and tenants takes longer than a cluster with a single workload and tenant. As we describe later, complexity matters.
The good news is that many customers with sub-100 node environments complete a cluster upgrade over a weekend, with each Development, QA, and Production cluster split over different weekends to facilitate the testing and validation process. Not only does splitting this provide good fail-safes and early problem discovery, but it also allows for a rich learning process that builds upon the solutions discovered at each environment level approaching Production.
Budgets, Hardware, and Physical Space
Some customers face specific limitations such as available budget, hardware capacity and replacement, or even corporate directives to reduce physical data center space. Each of these limitations impacts the path we may need to take.
Let’s take the straightforward case of data centers being retired in preference for public cloud infrastructure. If this is a corporate mandate, then the path we should approach is a Migration to Cloud, using CDP Public Cloud in AWS, Azure, or GCP.
If hardware capacity and budget for new equipment are limited, then the choice might be an in-place upgrade with some expected downtime. If SLAs limit downtime but hardware capacity does not, then the Rolling Side-car Migration may be appropriate, thereby draining hardware and workloads from the legacy environment and building a new one with existing equipment.
In some cases, the SLAs may demand limited maintenance windows, but the budget or hardware age may allow for a total refresh and replacement. Building a new cluster with modern hardware would allow the regular Side-car Migration mechanism to run.
How complex is complex?
As part of the upgrade and migration process, we need to evaluate the environments for their complex data and workload dependencies. In the case of multi-tenant environments, we must also assess cross-organizational dependencies. For example, we may need to understand that a quarterly Finance workload relies on output from an HR report. If we attempt to migrate the generation of the HR report before the Finance workload, we risk breaking that flow. Identifying the ordering of these operations is critical. Similarly, identifying loosely coupled workloads allows us to better plan and mitigate.
Along with the order complexity, we must understand the conversion complexity. Both legacy CDH and HDP distributions have components that don’t make the transition to CDP. In some cases, those components are replaced, and conversion tools are provided, such as the change from Apache Sentry to Apache Ranger. In other cases, developers must do manual work to transition to newer technologies, such as Apache Spark 1.6 to 2.4 or the change from Apache Storm to Apache Flink.
We recommend enabling Workload Manager (WXM) on your legacy clusters to reduce the evaluation work and accelerate the planning and implementation. Cloudera’s WXM allows us to understand existing Hive, Impala, and Spark workloads, establishing performance baselines to compare against once you’re up and running with CDP. Additional information can be found in our blog, Accelerate Moving to CDP with Workload Manager.
Keeping up with Change
Cloudera highly recommends having a regularized development flow that moves forward through a Development, QA, and Production cluster. In many customers, this flow is also tied to corporate governance and change control requirements. Understanding what changes help stabilize environments and keeps them resilient to failure.
When a customer combines those environments, the overall resilience goes down, and upgrade risk goes up. For example, having a single cluster that runs both development and production workflows may experience a high production impact because changes to test customer applications on CDP are made simultaneously to the system handling both development and production. Once we have moved into the CDP product line, we can take advantage of additional isolation of workloads and data through CDP Public Cloud or CDP Private Cloud Experiences, further reducing these upgrade risks in the future. A CDP Experience focused on a single tenant can be upgraded independently of others under your control.
When the customer has a defined and separate environment for each stage of this flow, it allows for better testing, documentation, implementation, and opportunity for rollback. This combination of activities helps mitigate and reduce the risk of upgrade failure.
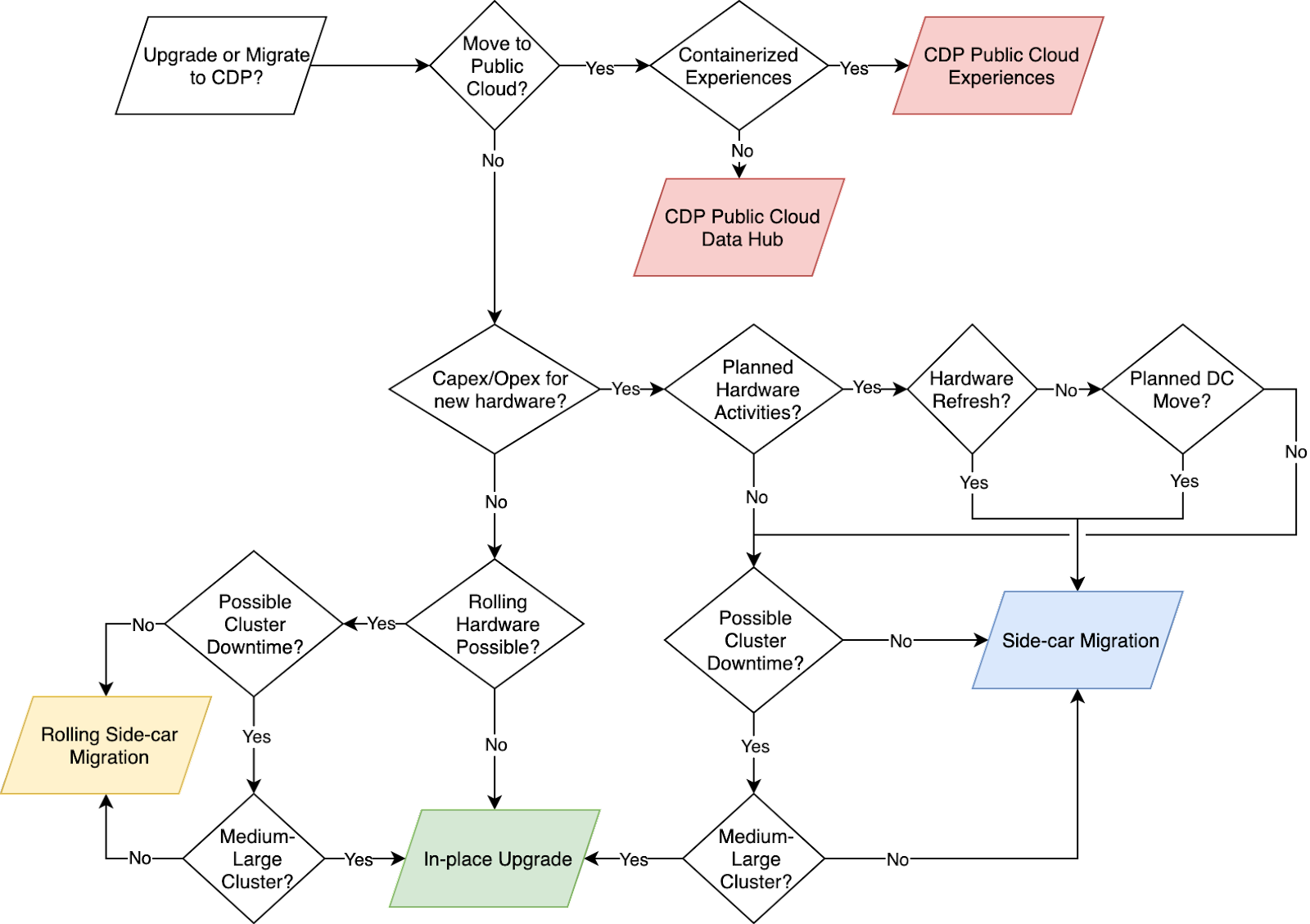
Round of Elimination
We need to consider the pros and cons of a particular path carefully. The round-of-elimination process will help remove nonviable paths early, driving the decision process towards the approach most likely to achieve success for your specific situation. We accomplish this by identifying expected outcomes or characteristics that have a material impact on the journey. In general, every environment should consider the in-place upgrade as the default direction and then move away from it only if business requirements demand it.
For example, when working through the rounds of elimination in an on-premises environment, we are concerned with the following four common issues. As we walk through each in the flow chart, we hope to address its associated category below.
- Public Cloud Consideration
- If moving to the cloud is an explicit business requirement, then In-place upgrades and Side-car migrations to on-premises equipment are no longer viable, and we should choose migration to CDP Public.
- If you need a cloud characteristic such as dynamic auto-scaling or better cost optimization and budget controls, then migration to CDP Public Cloud is viable.
- Limited testing capacity on-premises may necessitate a dual approach by moving part of this work to CDP Public Cloud temporarily while the on-premises environment is rebuilt from scratch on CDP Private or upgraded directly.
- Planned Hardware Activities
- Any planned hardware refresh in the near term for the cluster nodes is an excellent reason to consider a Side-car migration.
- Any other hardware activities like a data-center move where new hardware is added should also be an excellent reason to choose side-car migration.
- Downtime Requirements
- Clusters with critical workloads and robust availability requirements warrant moving away from In-place upgrades and towards a Side-car or Cloud migration to limit the downtime exposure.
- Self-contained workloads or tenants that can be moved one at a time would provide the option to consider Side-car or Rolling Side-car migrations, given sufficient hardware capacity.
- Cluster Data Footprint or Complexity
- Small to medium clusters with current cluster storage utilization at less than 50% would be ideal for rolling side-car migrations.
- Small to medium clusters with available hardware budget for new nodes should consider Side-car migrations.
- Large clusters with significant data footprints should consider doing an in-place upgrade.
- Clusters with tightly coupled tenants and data sets may need to consider In-place upgrades to move everyone to CDP in lock-step because complex dependencies may make migrations time and resource-intensive.
Ultimately, the goal of this process is to identify the likely path to success. The categories reviewed and questions asked as we assess the environment may adjust the decision as we get more familiar with your setup or discover new situations needing review. Upgrades and migrations may not be one-click operations, but they are certainly achievable given the proper planning and testing. Together, we can figure out a path that works best for you.
Learn More
To plan your upgrade or migration to CDP Private Cloud Base, please contact your Cloudera account team, who will set up some time to walk through the available options with you. Additionally, here are some helpful resources:
- Upgrade Advisor Tool
- Getting Started with CDP Upgrade and Migration
- CDP Upgrade Documentation
- SmartUpgrade Datasheet
- CDP Knowledge Hub
Editor's Choice

