

This blog post was published on Hortonworks.com before the merger with Cloudera. Some links, resources, or references may no longer be accurate.
With Hortonworks DataFlow (HDF) 3.3 now supporting Kafka Streams, we are truly excited about the possibilities of the applications that you can benefit from when combined with the rest of our platform.
In this post, we will demonstrate how Kafka Streams can be integrated with Schema Registry, Atlas and Ranger to build set of microservices apps for a fictitious use case.
Streaming Use Case for a Trucking Fleet Company
For this sample application, a trucking fleet company has sensors outfitted on their fleet of trucks. The geo-event sensor captures important events from the truck (e.g: lane change, breaking, start/stop, acceleration along with its geolocation) and the speed sensor captures the speed of the truck at different intervals. These two sensors are streaming data into their own respective kafka topics: syndicate-geo-event-avro and syndicate-speed-event-avro. The requirements for the use case are the following:

Using a MicroServices Architecture to Implement the Use Case
In the past, we have shown how to use Streaming Analytics Manager (SAM) to implement these requirements. With Kafka Streams, you can implement these requirements with set of light-weight microservices that are highly decoupled and independently scalable. The below diagram illustrates this architecture
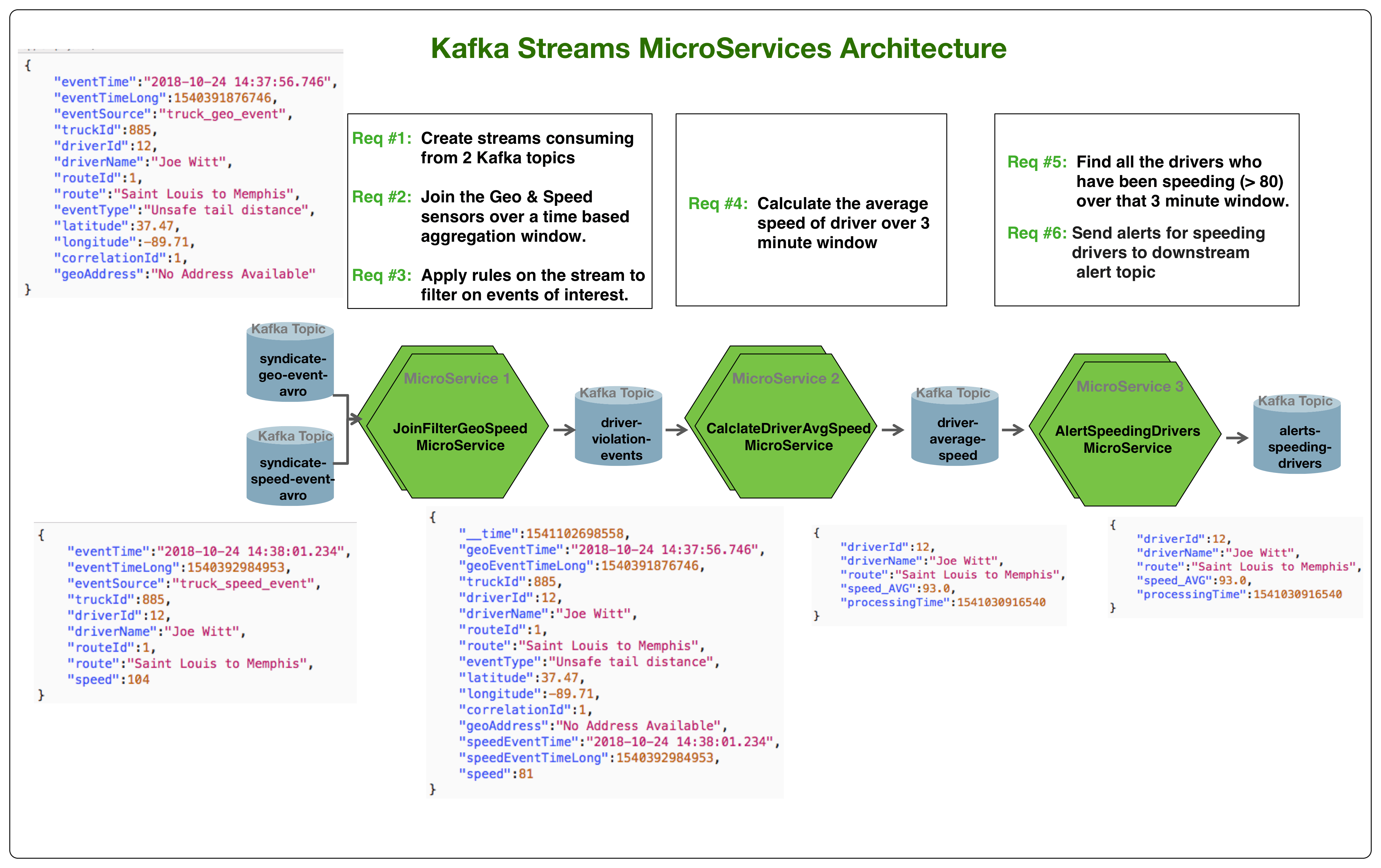
Join Support in Kafka Streams and Integration with Schema Registry
Kafka Streams has rich support for joins and provides compositional simple APIs to do stream-to-stream joins and stream-to-table joins using the KStream and KTable abstractions. More details on this can be found here: Joining in Kafka Streams.
The below diagram illustrates how JoinFilterGeoSpeed MicroService was implemented using the join support in Kafka Streams as well as integration with Hortonworks Schema Registry to deserialize the events from the source kafka topics.
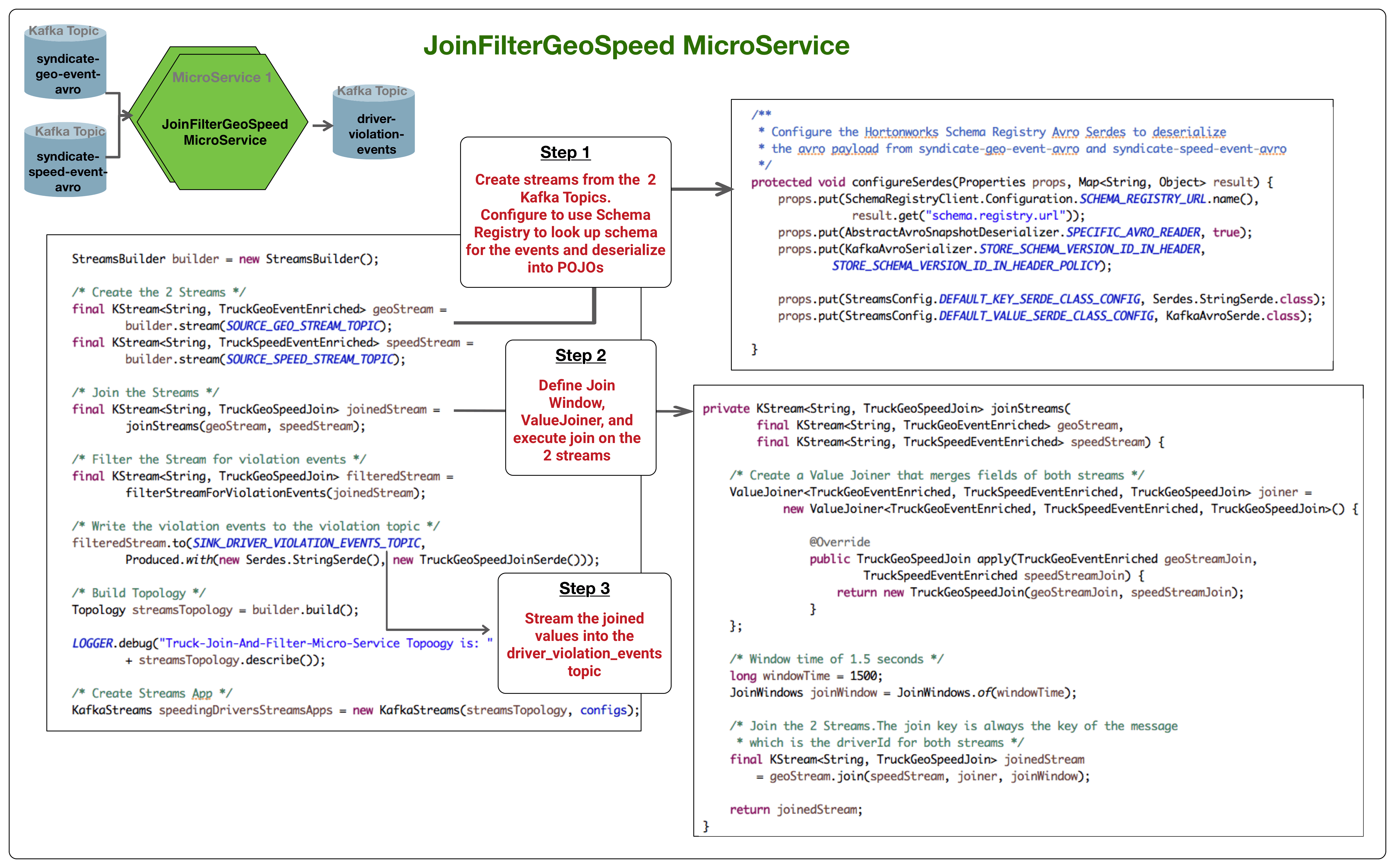
The code for this microservice can be found here: JoinFilterMicroService.
Aggregation over Windows and Filtering Streams
Windowing lets you control how to group records that have the same key for stateful operations such as joins or aggregations into so-called windows. Four types of windowing are supported in Kafka streams including: tumbling, hopping, sliding and session windows. More details on windowing can be found here: Windowing in Kafka Streams.
The below diagram illustrates how tumbling windows was used in CalculateDriverAvgSpeed MicroService to calculate the average speed of driver over a 3 minute window.
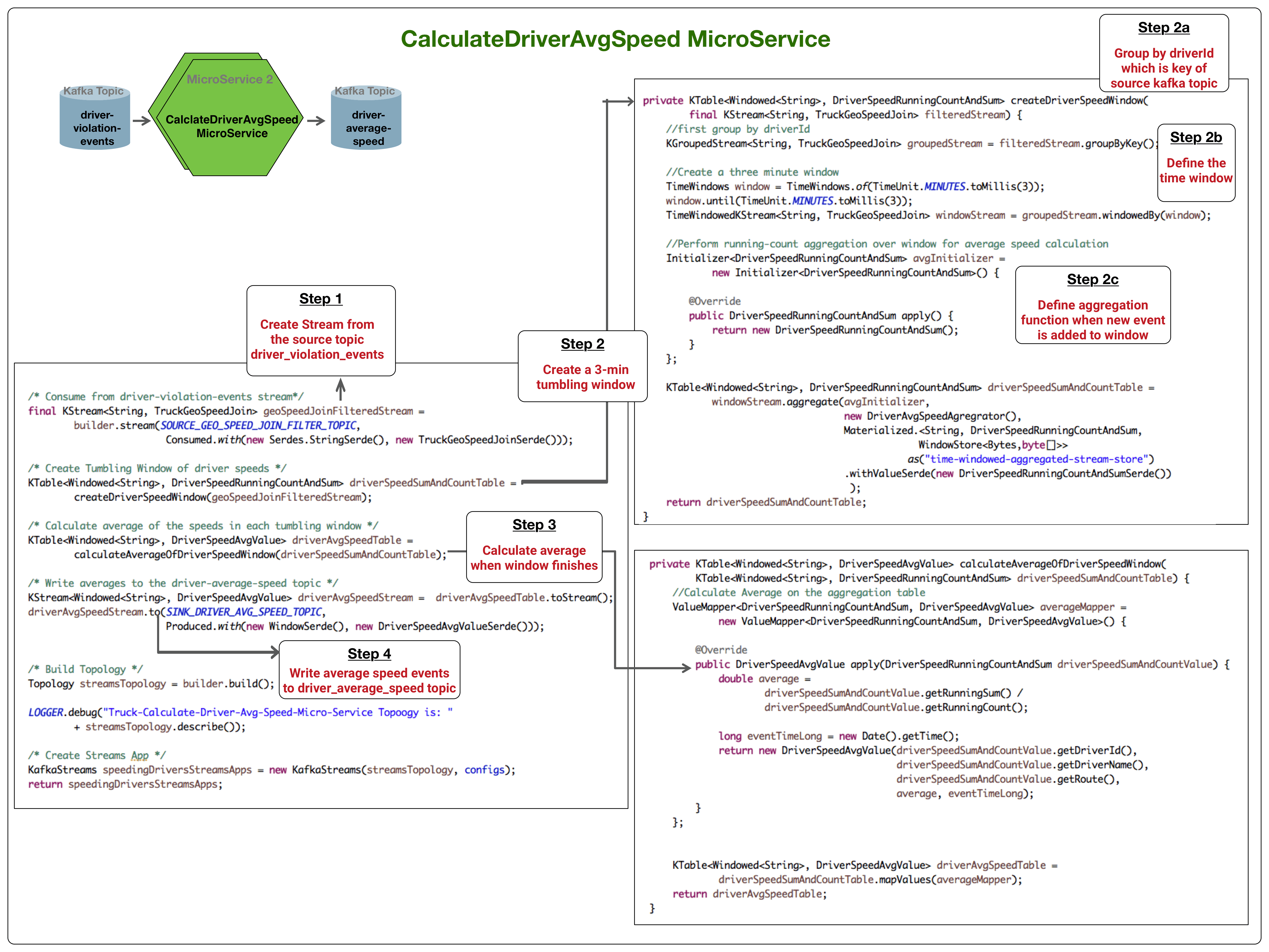
The code for this microservice can be found here: CalculateDriverAvgSpeedMicroService .
The third MicroService called AlertSpeedingDrivers filters the stream for drivers who are speeding over that three minute window.
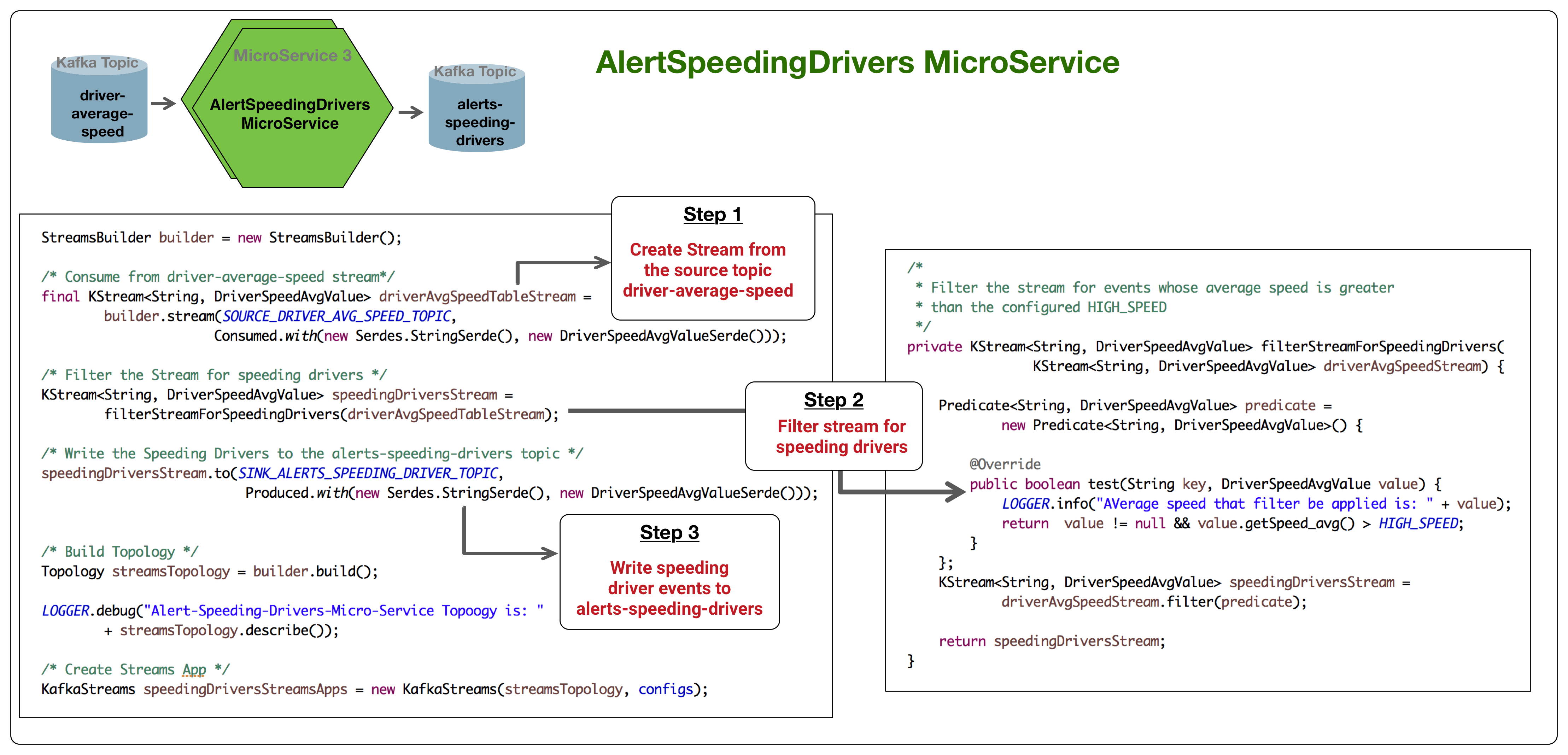
The code for this microservice can be found here: AlertSpeedingDriversMicroService.java
Running and Scaling the MicroServices Without a Cluster
One of the key benefits of using Kafka Streams over other streaming engines is that the stream processing apps / microservices don’t need a cluster. Rather, each microservice can be run as a standalone app (e.g: jvm container). You can then spin multiple instances of each to scale up the microservice. Kafka will treat this as a single consumer group with multiple instances. Kafka streams takes care of consumer partition reassignments for scalability.
You can see how to start these three microservices here.
Secure and Auditable Microservices with Ranger, Ambari and Kerberos
The last two requirements for the trucking fleet application have to do with security and audit. For the JoinFilter MicroService, let’s distill these into the following more granular auth/authz requirements:

For Req #1, when we start up the microservice we configure the jvm parameter java.security.auth.login.config to point to the following jaas file. This jaas file contains the principal named truck_join_filter_microservice with its associated keytab that the microservice will use when connecting to kafka resources.
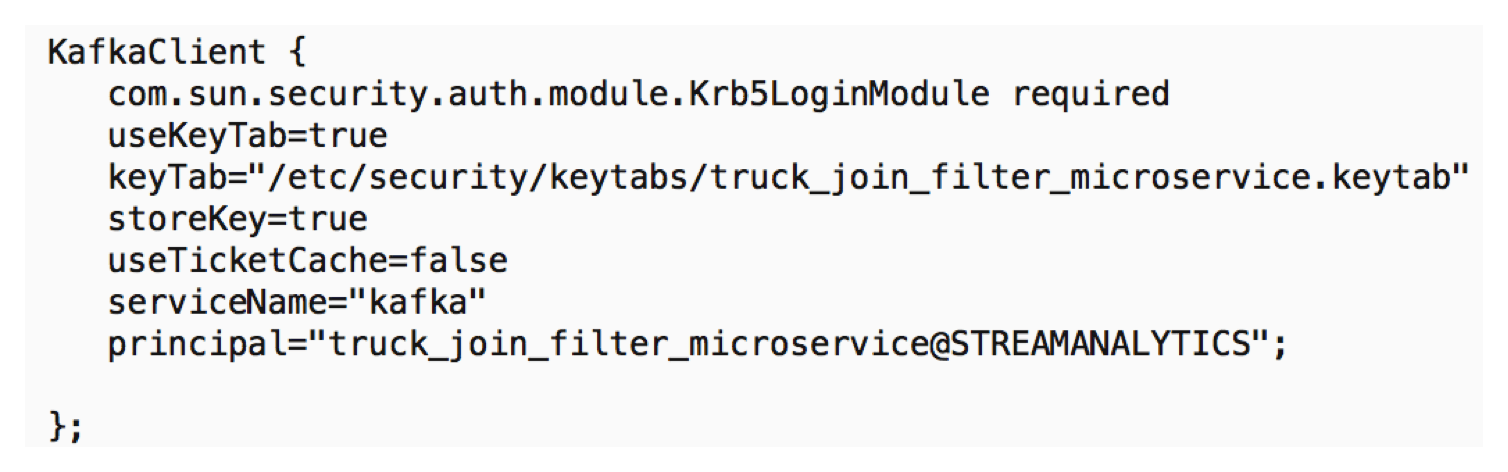
For Req # 2, 3 and 4, we use Ranger to configure the ACL policies.

For Req #5, Ranger provides audit services by indexing via Solr all access logs to kafka resources.
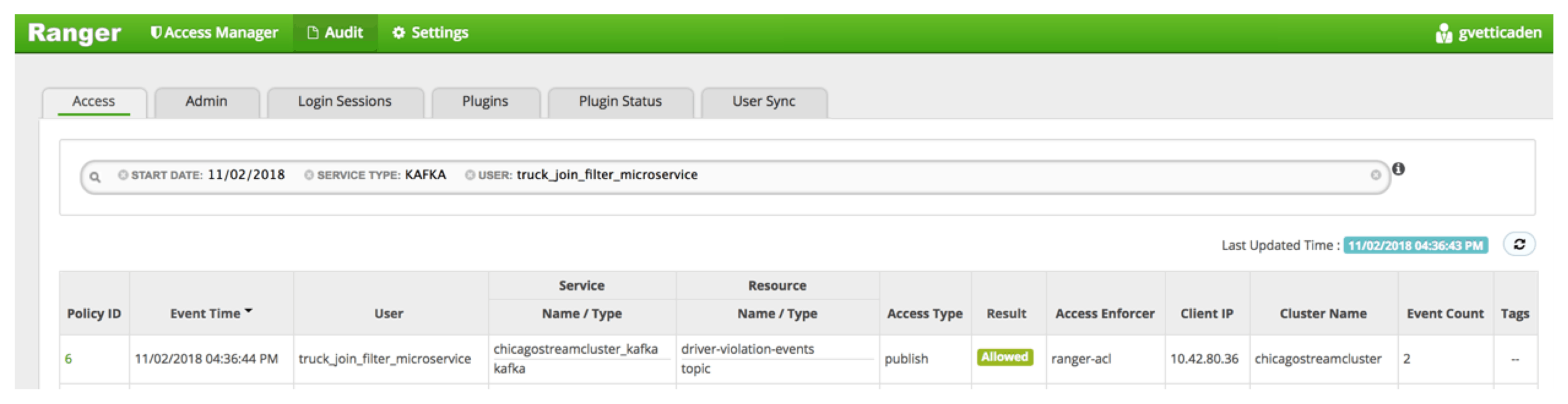
What’s Next
In the next installment of the Kafka Analytics blog series, we will walk through how to monitor these Kafka Streams microservices with Hortonworks Streams Messaging Manager (SMM).
Editor's Choice


Hi, I have tried to execute this project but couldn’t. Seems dependencies are missing. Repo are private. Pls support