

Traditional messaging models fall into two categories: Shared Message Queues and Publish-Subscribe models. Both models have their own pros and cons. Neither could successfully handle big data ingestion at scale due to limitations in their design. Apache Kafka implements a publish-subscribe messaging model which provides fault tolerance, scalability to handle large volumes of streaming data for real-time analytics. It was developed at LinkedIn in 2010 to meet its growing data pipeline needs. Apache Kafka bridges the gaps that traditional messaging models failed to achieve. Kafka implements concepts from both models, overcoming their disadvantages while also having the flexibility to incorporate both methodologies at scale.
Shared Message Queue
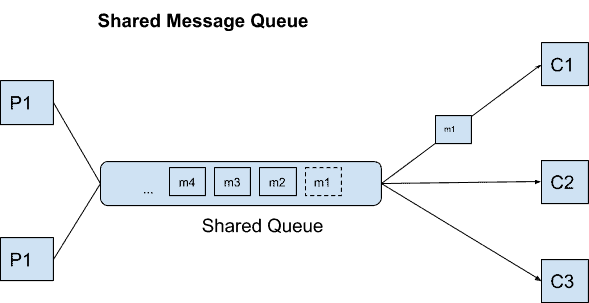
A shared message queue system allows for a stream of messages from a producer to reach a single consumer. Each message pushed to the queue is read only once and only by one consumer. Subscribers pull messages (in a streaming or batch fashion) from the end of a queue being shared amongst them. Queueing systems then remove the message from the queue one pulled successfully.
Drawbacks:
Once one consumer pulls a message, it is erased from the queue.
Message queues are better suited to imperative programming, where the messages are much like commands to consumers belonging to the same domain, than event-driven programming, where a single event can lead to multiple actions from the consumers’ end, varying from domain to domain.
While multiple consumers may connect to the shared queue, they must all fall in the same logical domain and execute the same functionality. Thus, the scalability of processing in a shared message queue is limited by a single domain for consumption.
Publish-Subscribe Systems
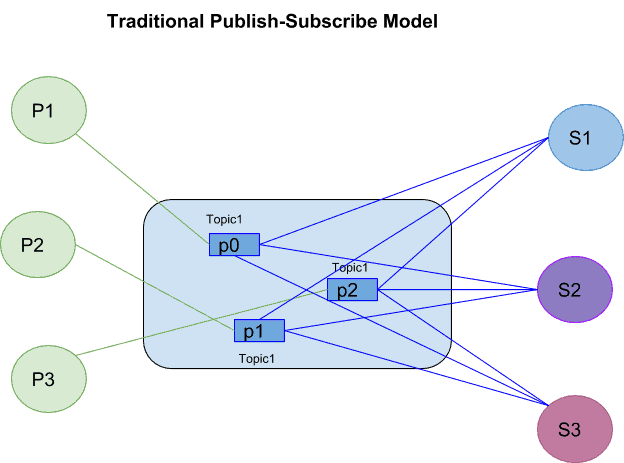
The publish-subscribe model allows for multiple publishers to publish messages to topics hosted by brokers which can be subscribed to by multiple subscribers. A message is thus broadcast to all the subscribers of a topic.
Drawbacks:
The logical segregation of the publisher from the subscriber allows for a loosely-coupled architecture, but with limited scale. Scalability is limited as each subscriber must subscribe to every partition in order to access the messages from all partitions. Thus, while traditional pub-sub models work for small networks, the instability increases with the growth in nodes.
The side effect of the decoupling also shows in the unreliability around message delivery.
As every message is broadcast to all subscribers, scaling the processing of the streams is difficult as the subscribers are not in sync with one another.
How Kafka bridges the two models?
Kafka builds on the publish-subscribe model with the advantages of a message queuing system. It achieves this with:
- the use of consumer groups
- message retention by brokers
When consumers join a group and subscribe to a topic, only one consumer from the group actually consumes each message from the topic. The messages are also retained by the brokers in their topic partitions, unlike traditional message queues.
Multiple consumer groups can read from the same set of topics, and at different times catering to different logical application domains. Thus, Kafka provides both the advantage of high scalability via consumers belonging to the same consumer group and the ability to serve multiple independent downstream applications simultaneously.
Consumer Groups
Consumer groups give Kafka the flexibility to have the advantages of both message queuing and publish-subscribe models. Kafka consumers belonging to the same consumer group share a group id. The consumers in a group then divides the topic partitions as fairly amongst themselves as possible by establishing that each partition is only consumed by a single consumer from the group.
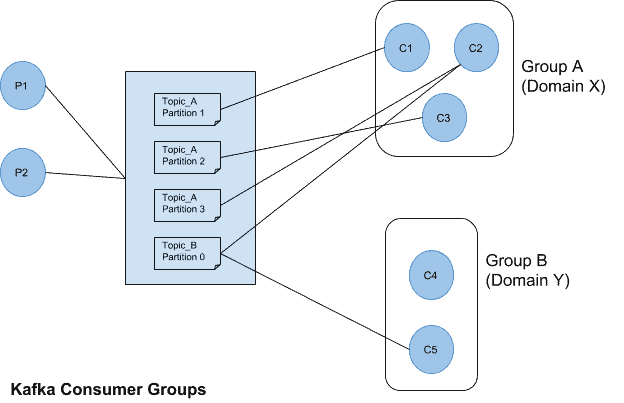
If all consumers are from the same group, the Kafka model functions as a traditional message queue would. All the records and processing is then load balanced Each message would be consumed by one consumer of the group only. Each partition is connected to at most one consumer from a group.
When multiple consumer groups exist, the flow of the data consumption model aligns with the traditional publish-subscribe model. The messages are broadcast to all consumer groups.
There also exist exclusive consumers, which happen to be consumer groups having only one consumer. Such a consumer must be connected to all the partitions it requires.
Ideally, the number of partitions is equal to the number of consumers. Should the number of consumers be greater, the excess consumers are idle, wasting client resources. If the number of partitions is greater, some consumers will read from multiple partitions which should not be an issue unless the ordering of messages is important to the use case. Kafka does not guarantee ordering of messages between partitions. It does provide ordering within a partition. Thus, Kafka can maintain message ordering by a consumer if it is subscribed to only a single partition. Messages can also be ordered using the key to be grouped by during processing.
Kafka also eliminates issues around the reliability of message delivery by having the option of acknowledgements in the form or offset commits of delivery sent to the broker to ensure it has reached the subscribed groups. As partitions can only have a one to one or many to one relationship to consumers in a consumer group, the replication of a message within a consumer group is avoided as a given message is reaching only one consumer in the group at a time.
Rebalancing
As a consumer group scales up and down, the running consumers split the partitions up amongst themselves. Rebalancing is triggered by a shift in ownership between a partition and consumer which could be caused by the crash of a consumer or broker or the addition of a topic or partition. It allows for safe addition or removal of consumer from the system.
On start up, a broker is marked as the coordinator for the subset of consumer groups which receive the RegisterConsumer Request from consumers and returns the RegisterConsumer Response containing the list of partitions they should own. The coordinator also starts failure detection to check if the consumers are alive or dead. When the consumer fails to send a heartbeat to the coordinator broker before the session timeout, the coordinator marks the consumer as dead and a rebalance is set in place to occur. This session time period can be set using the session.timeout.ms property of the Kafka service. The heartbeat.interval.ms property makes healthy consumers aware of the occurrence of a rebalance so as to re-send RegisterConsumer requests to the coordinator.
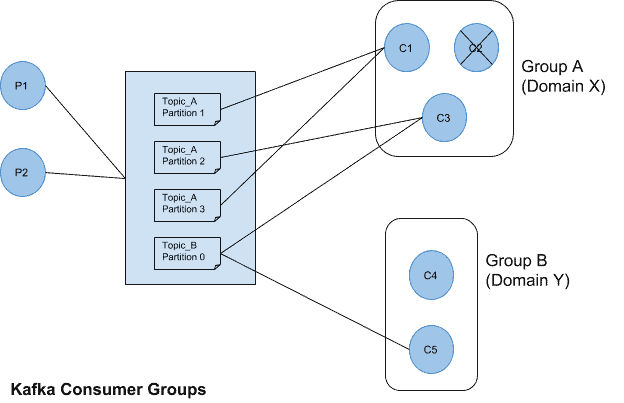
For example, assuming consumer C2 of Group A suffers a failure, C1 and C3 will briefly pause consumption of messages from their partitions and the partitions will be up for reassignment between them. Taking from the earlier example when the consumer C2 is lost, the rebalancing process is triggered and the partitions are re-assigned to the other consumers in the group. Group B consumers remain unaffected from the occurrences in Group A.
Use Case Implementation:
We set up a flume sink of a Kafka Topic ‘tweets’ partitioned across two brokers. ‘Tweets’ has only one partition.
A Java consumer, Consumer0 connects to the topic ‘tweets’ and another consumer from the console belonging to the same groupid as the previous one. The first has the group id ‘group1’. The kafka consumer from console has the group id ‘console’. We then added two consumers to the consumer group ‘group1’. As it’s only one partition, we see that of the three consumers in the group, only one consumer, Consumer2 continues pulling messages for the group.
The consumer for group2 is then started and connected to same topic ‘tweets’. Both consumers read at the same pace of offsets. When Consumer2 from group1 is switched off, We see after some time has elapsed (session timeout) Consumer1 from group one picks up from the last offset Consumer2 closed on. Consumer0 remains stalled at the offset it stopped at. This shows rebalancing occuring due to the loss of a consumer form the group.The console consumer however remains unaffected in consumption of messages.
In the case of multiple partitions of a topic we can see that as many consumers belonging to the same group will process the messages off the topic, as per the partition assigned on start up. The messages are guaranteed ordering only within a partition and not between the brokers. When a consumer fails in this scenario, the partition it was reading from is reassigned during the rebalance phase initiated at session timeout.
Conclusion
Shared Message queues allowed scale in processing of messages but in a single domain. Publish-subscribe models allowed for message broadcasting to consumers but had limitations in scale and uncertainty in message delivery. Kafka brings the scale of processing in message queues with the loosely-coupled architecture of publish-subscribe models together by implementing consumer groups to allow scale of processing, support of multiple domains and message reliability. Rebalancing in Kafka allows consumers to maintain fault tolerance and scalability in equal measure.
Thus, using kafka consumer groups in designing the message processing side of a streaming application allows users to leverage the advantages of Kafka’s scale and fault tolerance effectively.
References
- Apache Kafka Consumers: https://kafka.apache.org/documentation/#intro_consumers
- Kafka as a Messaging System: https://kafka.apache.org/documentation/#kafka_mq
- Kafka Command line tools: https://www.cloudera.com/documentation/kafka/latest/topics/kafka_command_line.html
- Using Apache Kafka with Flume: https://www.cloudera.com/documentation/kafka/latest/topics/kafka_flume.html
Editor's Choice


Shouldn’t there be four lines going to Group B in your Kafka diagrams?
No, in their diagram Consumer Group B has subscribed to Topic_B, which has been assigned only partition_0
The Use Case Implementation is very confusing. After reading this paragraph,
“A Java consumer, Consumer0 connects to the topic ‘tweets’ and another consumer from the console belonging to the same groupid as the previous one. The first has the group id ‘group1’. The kafka consumer from console has the group id ‘console’. We then added two consumers to the consumer group ‘group1’. As it’s only one partition, we see that of the three consumers in the group, only one consumer, Consumer2 continues pulling messages for the group.”
I’m not sure why “another consumer from the console belonging to the same groupid as the previous one” has group id “console”, which isn’t the same group id “group 1”.
Excellent historical context and exposition of the Logging model that Kafka does as a flexible combination of previous ones…
How can I create a consumer group dynamically with each increasing pod/instance of consumer application?
Like if 1 instance is running then, there is 1 CG and if we scale it to 5