

This blog post was published on Hortonworks.com before the merger with Cloudera. Some links, resources, or references may no longer be accurate.
Special thanks to Bill Preachuk and Brandon Wilson for reviewing and providing their expertise
Introduction
Columnar storage is an often-discussed topic in the big data processing and storage world today – there are hundreds of formats, structures, and optimizations into which you can store your data and even more ways to retrieve it depending on what you are planning to do with it. This plethora of options came about due to the need to not only ingest data quickly using On-Line Transactional Processing (OLTP) tools, but also because of the need to consume and analyze data with greater efficiency using On-Line Analytical Processing (OLAP) tools. Thousands of different use cases each have their own specific needs and thus, many options have surfaced. For example, reading stock market ticker data requires a completely different mindset than analyzing quality metrics in a manufacturing line. With all these choices, it’s easy to get lost when navigating to your end goal: choosing a tool that works for you.
HDP incorporates a number of storage solutions, each of which are tailor-made for specific use cases. We want to start this blog series by talking about the following three tools/engines and their associated storage formats:
- Apache Hive uses Apache ORC as an efficient columnar storage format that enables performance for both OLAP and deep SQL query processing
- Apache Phoenix/Apache HBase together form an OLTP database that enables real-time queries over billions of records and offers fast random key-based lookups as well as updates
- Apache Druid is a high performance data store that enables real-time time-series analysis on event streams and OLAP analytics over historical data with extremely low latency
In this article, we intend to articulate which tool is appropriate for a given use case, compare and contrast the various tools, and provide a basic guideline for choosing the appropriate tool or set of tools to address your use case.

This is much like playing Tetris – each piece has a different niche but they each add unique value to the larger structure
Big Data Processing and Its Similarities
Data is grouped by columns in storage because we are often trying to narrow down sums, averages, or other calculations on a specific column. Imagine you are an airline trying to understand how much fuel to give a plane when it is docked – you might want to compute the average miles flown by each flight from a table of flight-trip data. This would require performing the average function on a single column. We would store this data in columnar format because sequential reads on disk are fast, and what we want to do in this case is read one full column from the table sequentially (and then perform an average calculation).
There are many differences between these engines but regardless of which data processing engine you choose, you will benefit from a few commonalities. One of those is the shared feature of caching. Each of these three engines works hand-in-hand with in-memory caching to up the performance of its processing without changing the backend storage format, achieving sub-second response times. HBase has the BlockCache, Hive has the LLAP IO layer, and Druid has several in-memory caching options. Oftentimes, the expensive part of servicing a query involves parsing the request and going to persistent store to retrieve the subset of data the user is interested in. That entire step however can be avoided when using an in-memory caching mechanism as many columnar storage formats use, allowing the process to reach into memory for previously queried data in fractions of a second. Let’s go back to our fuel calculation example: say I’ve just asked for the average miles flown for all flights at my company, but realize that domestic flights will have fuel requirements that are much different than international flights. I will then want to filter my previous query with a WHERE country=’US’ (or equivalent country code) clause. This query pattern is very common for data exploration. Since we already have the previous query’s data in memory, the results of this query can be returned without having to perform an expensive disk read.
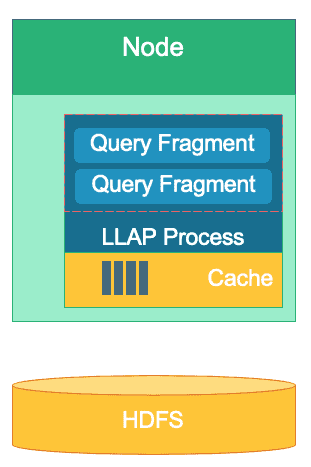
The structure of Hive’s LLAP layer – part of its memory space is used for caching, while long-term storage is on HDFS. HBase and Druid also have a similar concept of cache and storage.
Another similarity exists in the shortcuts each of these engines use to zero in on the specific data that is being queried. HBase has HashMap-based O(1) random access, Druid uses inverted bitmap indexes to figure out which column values are in which rows, and Hive tables have statistics, indexes, and partitioning to shortcut data access. These features enable the engines to combine the way data is stored with the way it is accessed, enabling fast analytics while optimizing efficiency of the hardware and making the most out of the CPU and RAM available.
The last similarity is the enterprise-readiness of each of these engines. On the data redundancy side, all three of these engines use HDFS as their deep storage mechanism; the HDFS replication factor of 3x ensures that copies of the data exist elsewhere even if two nodes fail simultaneously. The data can immediately be re-replicated once again to healthy nodes to maintain redundancy. On the topic of fault tolerance within a cluster, each tool fills the gap in some way. HBase offers region replication, Druid has duplication of master and worker components as well as increased replication factor on HDFS, and Hive has HDFS alongside the YARN framework’s fault-tolerant logic. Enterprise readiness ensures these engines are resilient to failure and ready to perform in production from day one.
The Differences Between our Big Data Processing Engines
What is the best way to ingest data? Once you have ingested your data, how do you quickly pull insights out of it? Let’s dive in to how these three big data processing engines support this set of data processing tasks
These engines are sometimes mentally bundled together and thought about similarly because of their ability to store as well as process Big Data, but as we’ll find out they are chosen for use cases and purposes that are specifically suited to their strengths. You’ll see that the collection of tools that the Hortonworks Data Platform contains is well-suited to any big data workload you can throw at it, especially with HDP 3.0 and the real-time database capabilities we’ve introduced.
Hive is the OLAP engine that is representative of the largest breadth of use cases, most commonly employing the Hadoop Distributed File System (HDFS) as its storage layer to allow storage of just about any type of data. It can query, process, and analyze unstructured text data, CSV files, XML, semi-structured JSON, columnar Parquet, and a host of other formats. Hive also supports alternative storage mediums such as Cloud storage, Isilon, and others. The de facto storage standard for Hive is ORC, which optimizes most efficiently & reaps the benefits of columnar storage. Once converted to ORC your data is compressed and the columns in your table are stored sequentially on disk, allowing Hive’s in-memory caching layer LLAP to pull the data from disk once and serve it from memory multiple times. The combination of Hive+LLAP is used for ad-hoc analysis, calculating large aggregates, and low-latency reporting. A great use case for Hive is running a set of dashboard reports for users daily; the repetitive queries not only take advantage of the LLAP cache, but also the ‘Query Results Cache’ feature – which returns near-instant results if the data has not changed (Aside: Query Result cache is a feature available in Hive 3.0 – released in HDP 3.0). Alongside that, a Hive Data Warehouse is a great use of the ad-hoc analytics Hive is capable of; users can join data together, run concurrent queries, and run ACID transactions. Consider Hive to be a SQL jack of all trades in that regard, while the other two engines provide extremely fast performance for specific niche use cases.
Our second engine, HBase, is a distributed key-value store that has random read, write, update, and delete capabilities. HBase (a NoSQL variant) is designed to be an OLTP engine, allowing an architecture of high-volume transactional operations – think messaging platforms with constant messages being exchanged between users or transactions being generated in a financial system. HBase is extremely efficient at bringing data in quickly, storing it, and serving it back out – ultra-low latency random Inserts/Updates/Deletes. What it is not designed for is aggregating and joining data – this functionality is accomplished through Phoenix, a SQL layer and engine on top of HBase, but is not recommended for larger amounts of data as the data is not structured in a way to achieve optimal performance (use Hive instead). To sum it up, HBase is great at processing high volumes of Create-Update-Delete operations, but falls short when it comes time to present that data in a consumable format for users.
Finally, Druid is the third engine and one suited for low-latency OLAP time-series workloads as well as real-time indexing of streaming data. Druid provides cube-speed OLAP querying for your cluster. The time-series nature of Druid is a cornerstone of the engine; it is designed this way because time is a primary filter when time-based data is analyzed. Think about when you are analyzing flight times to book a trip – I want to know the lowest cost flight to Italy within this particular 2-week time frame. Druid fits the niche of being very quick to ingest data as well as locate it when requested. On the other hand it also allows business users and analysts to query the data and understand it through Superset, a visualization layer closely tied with Druid. Druid excels in pinpointing a handful of rows of data amongst hundreds of millions or billions in under a second, and it also excels in calculating aggregate values over that same volume of data extremely quickly. However it does not do joins and therefore cannot be used for combining datasets together for analysis. If you plan to analyze a combination of datasets in Druid, you would be wise to pre-join the data before inserting it into Druid or use Hive (and Druid-backed Hive tables) to perform joins. Said in other words, Druid fits well into the role of being the last stop for your data after it has been processed and transformed into how your business users will be accessing it. Druid is great for business analysts as they can log into Superset and visualize metrics in dashboard form without having to write any queries; they simply use a GUI to select the query datasource and filters. It’s also great as a backing datasource for system dashboards, whether operational or analytical, due to its quick query times.
Here’s one way you can break down the decision making on which tool to use for your workload:
| HBase | Hive | Druid |
| Ultra-low latency Random access (key-based lookup) | ACID, real-time database, EDW | Low-latency OLAP, concurrent queries |
| Large-volume OLTP | Unified SQL interface, JDBC | Aggregations, drilldowns |
| Updates | Reporting, batch | Time-series |
| Deletes | Joins, large aggregates, ad-hoc | Real-time ingestion |
Unified SQL
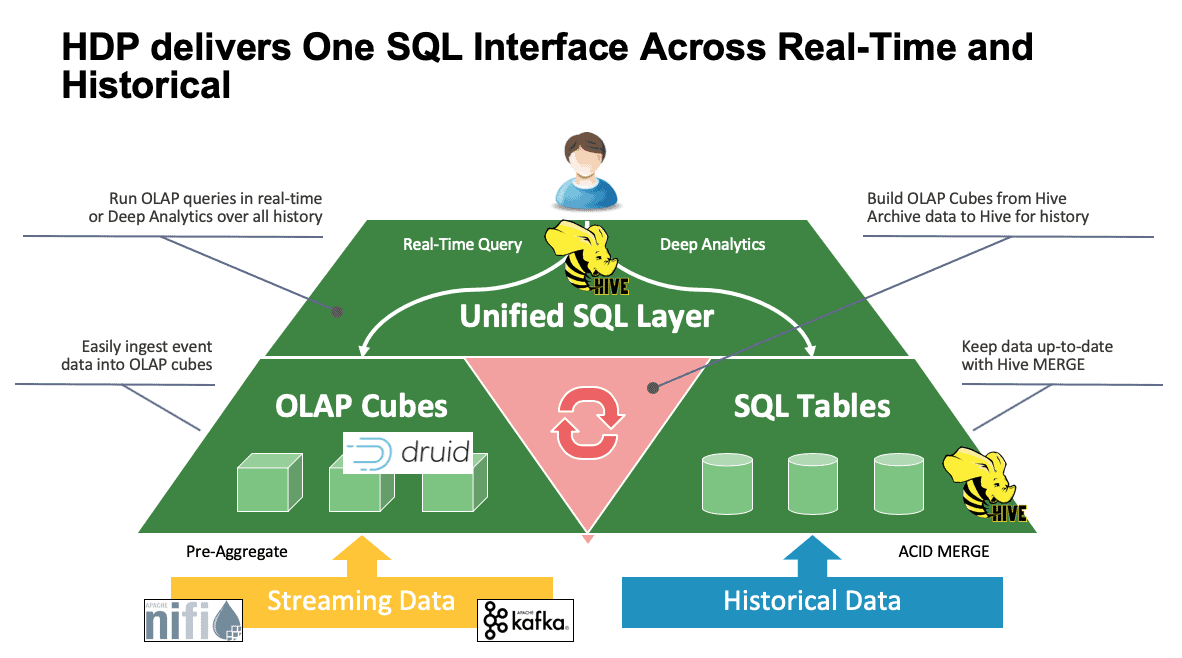
We’ve discussed multiple systems up to this point and they each have their own ways to access their data. This is great when your users know how all of these tools work, but they may be in for a learning curve before they can reach full productivity if they’re coming from a world of SQL, SQL, and more SQL as most analysts do. This is why we’ve tried to make this interaction as simple as possible; with Hive 3.0 in HDP 3.0, you can use Hive’s SQL-like HQL syntax to interact with so many different data stores in this space. Hive can be used as a portal to access and modify Druid, HBase, and anything that provides a JDBC interface and driver. Hive can be used to administer a Druid ingestion task that listens to Kafka, providing a simple way into real-time ingestion. And finally, Hive can be used to bring it all together – store your data where it makes the most sense and access it from one place. Join it together, maybe even store that new result in another location. The possibilities are many, but the interface has been greatly simplified so your user base can spend less time learning another tool and more time bringing value to the business.
Conclusion
Hive, Druid, and HBase all have different places in a data architecture as we’ve seen from the previous analysis. They are complementary tools however; you could ingest transactional data with HBase with its fast lookups, move that data into Druid for fast drill-down/aggregation, and have Hive integrate the two together with its own Hive-managed data to allow users to combine data wherever it may reside for a single view and a wealth of insights. With this approach, Druid stores data that can be accessed on its own but that functionality is augmented by Hive, which can pull in Druid data and join that with additional data. Add onto this the major enhancements that have come into play with Hive 3.0, not the least of which are materialized views, improved integrations with Druid as well as many other engines, and increased data warehouse-like functionality, and you’ve got a group of tools that can solve just about any use case.
Architectures such as the aforementioned bring in the best of each tool to optimize your workflow and at the same time abstract the details away for those users only concerned with the data. The architects set up the pipelines, putting the data where it belongs based on the use case. That then leads to the data analysts, who use Hive as their single interface to gain knowledge and insights. They’re able to find interesting patterns in the data rather than worrying about where the data is stored or learning a new syntax to access it – you’d be surprised to find out how often we see this out in the world.
At this point we have demonstrated each tool’s strengths, weaknesses, and best practices; we hope you walk away with a better understanding of what fits where as well as the bigger picture of combining all three to get the best results.
Editor's Choice

