

“We yearn for the beautiful, the unknown, and the mysterious.”
– Issey Miyake
The present state of anticipation and promise of AutoML is best captured by this quote from Issey Miyake, a famous Japanese fashion designer. Issey, who blended technology in fashion design, was also known for the signature black turtlenecks worn by Steve Jobs.
Today, AutoML is the unknown, the mysterious and is made to look beautiful via jazzy UIs of some proprietary tools in the market. Data scientists are exploring the promise of this new solution, uncertain if this will be the automation that makes their jobs redundant. So let’s step back to look at the bigger picture to answer this question.
Hidden Technical Debt in Machine Learning and AutoML
In a unique paper published in 2015, Google engineers looked at “technical debt” i.e. the long-term costs & complexities associated with ML solutions. A key observation, not surprising to most practitioners in the field, is that only a small fraction of an ML solution is the actual learning algorithm.
Technical debt that accumulates over-time is due to significant amount of “glue code” that is required. “Glue code” is defined as the code that is necessary to get data into and out of ML learning algorithms. Google estimates glue code to be 95% of the total code base with only 5% of actual ML learning code.
Take a look at the following graphic from the paper to get an idea about the functional blocks and their relative size in a real world ML solution.
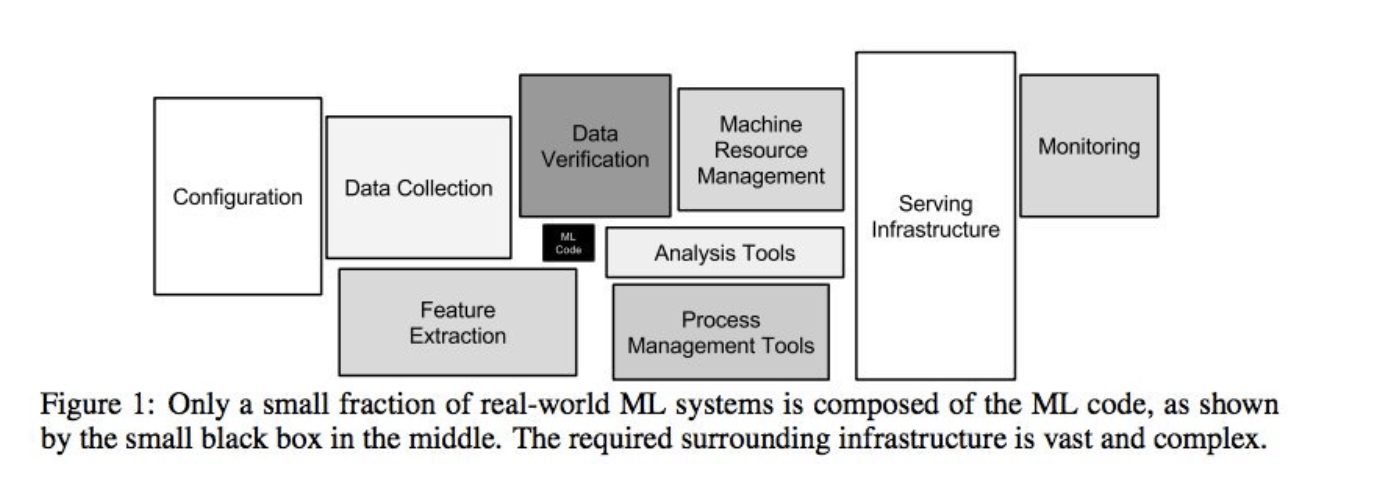
While AutoML is increasingly covering bigger portions of glue code (i.e. Feature Extraction and Preparation is now part of many AutoML approaches), it is still only a small fraction of a total solution.
Based on this paper, the logical conclusions that follow are:
- AutoML is a productivity enhancing capability aimed at automating the ML learning code. This frees up time to focus on the broader aspects of the end-end ML application. That makes it a productivity tool for Data Scientists – not their replacement.
- Data scientists need an end-end platform to aid in the development of real-world ML solutions. This platform needs capability to manage the lifecycle of ML models and should allow easy integration of AutoML productivity enhancing tooling as well.
Entire Scope of Data Scientist’s Role
Media is abuzz with hype about data scientist salaries such as this New York Times article. While salaries in the half million to multi-million range sound exciting, they are more the exception than the norm.
To understand the reason for this, let’s look at how a true data scientist role is defined. Following is an often cited graphic. Model building and algorithms are a small fraction of this overall picture. Yet, a lot of literature and academic courses focus heavily on the modeling aspect alone.
AutoML capability frees up Data Scientists from this heavy modeling focus and allows them to address the true scope of the role – by focusing on the right problems to solve and to drive the business outcomes by embedding the ML solutions into the business process.
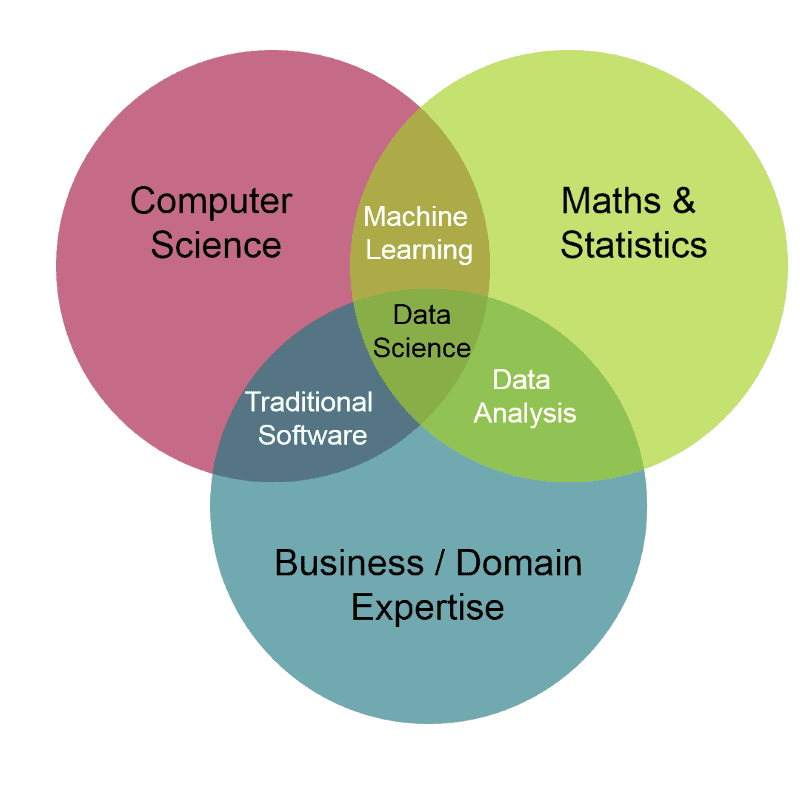
Figure 2: Data scientist role spans across Domain Expertise, Statistics/Maths and Algorithms/Coding.
Data Scientists need to own the end-end process from prioritizing the business problem to solve, converting the business problem to data science problem, building a scalable ML solution and then driving business outcomes. Data Scientists that can handle all aspects are paid higher salaries.
Definitions of AutoML
Multiple definitions of AutoML exist today. One popular definition comes from this Google paper on Neural Architecture Search. However, there are two additional usage patterns in AutoML. Present day open-source & commercial solutions target one or more of these patterns.
| Avant-Garde | Citizen | Core |
| Focused on use-cases in Deep-Learning. Leverage AutoML to craft optimum Neural Network Architectures.
(closest to Google paper) |
Traditional analysts (BI, Financial, Business etc.) that wish to leverage the power of ML in their work. | Data Scientist teams that utilize AutoML as a productivity tool.
Utilize AutoML to get quick baseline models and automate commoditized use-cases. |
| Niche | Very Broad | Tailored for Specialists |
While each of these have their place, the most significant opportunity for business impact lies in the Core segment. Helping data scientist teams achieve their full potential via productivity tooling by providing automation during feature selection, feature encoding & transformation, model selection and hyperparameter optimization steps, to get higher accuracy. Rest of this blog will focus on the Core segment.
Open Source vs. Proprietary AutoML
AutoML comes in various shapes and forms – from open-source libraries to proprietary products with sleek UIs. For data scientists, the flexibility to use different AutoML approaches matters – and a platform that allows working with any approach of choice is a necessity.
In this post, we will look at a use-case with open-source AutoML. In a subsequent post, we will focus on proprietary approaches.
Use-Case : Forecasting Real Estate Prices
Real estate price forecasting has been an often used example. However, to make things challenging, we will use data that inherently lacks differentiating/granular features and typically results in underfitting of models. We will then explore open-source AutoML libraries to see if we can get a model similar to the base model without a lot of exploratory analysis, feature engineering or other types of glue code.
Base Model : Linear Regression with Features for Trend, Seasonality, Property Characteristics
The data used is from the UK’s HM Land Registry. We will use Price Paid data for 2018 and split it into train and test set. Since this is a time-series, the best approach is to use a continuous data for certain time period as training and the remaining time period data as test (vs. random sampling from the entire set which breaks the time series). We will use the first 9 months of data for training and remaining 3 months data as test set.
The python code for the entire use-case, including AutoML portions, is found here.
The dataset is particularly challenging as the typical features that determine property value, such as the property size, number of bedrooms, proximity to employment centers, quality of nearby schools, crime rate and so on, are all missing. These missing features need to be augmented to the feature set.This will be a crucial step in building an accurate estimator.
Using AutoML, a data scientist can get a working model quickly. The productivity benefit of AutoML thus frees up data scientist bandwidth to focus on augmenting feature set as well as productizing the final data pipeline plus model – instead of getting stuck at the model creation step.
We first hand crafted a baseline model using exploratory data analysis, feature selection and feature encoding. Our feature selection metric was based on univariate models. We chose features that had high R2 and lower MSE. Take a look at code found here for details on feature encoding/transformations, feature selection and model building process.
AutoML via TPOT
TPOT is an open-source AutoML library that uses genetic algorithm to explore various ways to build ML models. TPOT follows scikit-learn like syntax so implementing it is easy. TPOT generates scikit-learn code for the final pipeline which makes it very easy to implement the generated models. Check out this video from Randal Olson, creator of TPOT for additional details on AutoML and TPOT.
We ran TPOT on the dataset for only 5 generations, each with a population size of 100. We kicked off a session and walked away. When we came back, we observed an improved R2 of 0.2676 on test set, better than our baseline model.
AutoML via Auto-SkLearn
Auto-SkLearn is another open source library for AutoML. It is also based on Scikit-Learn and utilizes Bayesian Optimization to identify effective feature encodings, transformations and algorithm selection.
Since it closely follows Scikit-Learn syntax, it is quick to implement. When we ran it, we got R2 of 0.2795, an improvement on baseline model.
Platform Considerations
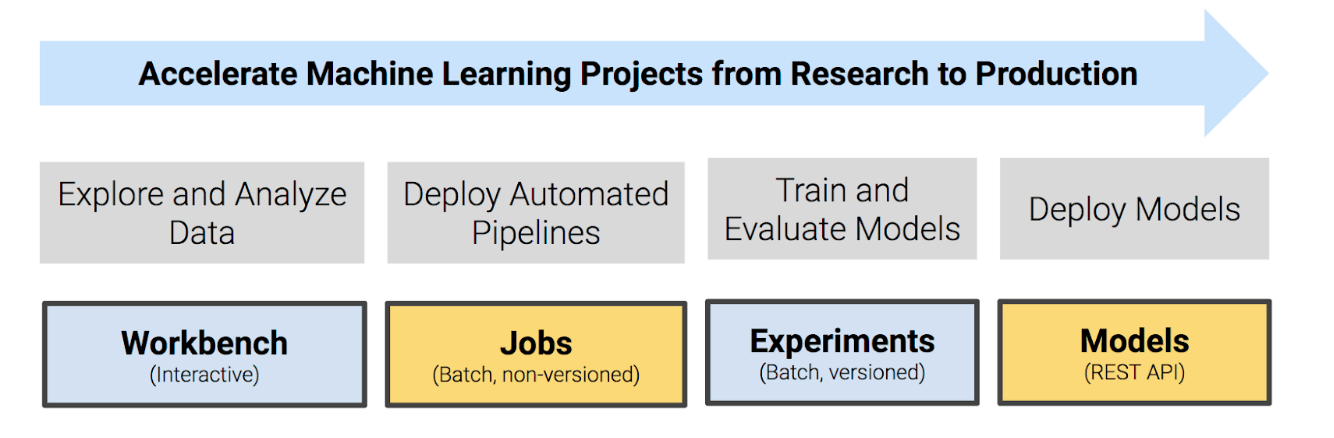
Both TPOT and Auto-SkLearn are based on Scikit-Learn and generate code for the final pipeline and model. We executed the code on Cloudera Machine Learning (CML) platform.
Once trained, the resultant model pipeline generated by AutoML frameworks can be wrapped into API end-point easily and deployed as a container with just a few clicks. This deployed model can be automatically monitored for performance drift and retrained periodically.
With CML in the picture, the data pipeline also becomes easy to deploy. A data pipeline to periodically fetch updated transactions from the source website can be deployed utilizing Jobs functionality. The seamless integration & transparent security with both on-prem Hadoop cluster and cloud storage (i.e. S3) makes it possible to upload this data into Hive tables. This data can then be queried and AutoML code deployed on it to generate the models for deployment.
AutoML and CML are a perfect combination to enable a rapid ML solutions development cycle. It frees up data science teams to focus on what matters most: getting positive business outcomes for the enterprise.
For more details:
https://www.cloudera.com/products/cloudera-data-platform.html
https://www.cloudera.com/products/machine-learning.html
Editor's Choice

