

This is a guest blog post from Jasper Pult, Technology Consultant at Lufthansa Industry Solutions, an international IT consultancy covering all aspects of Big Data, IoT and Cloud. The below work was implemented using Director’s API v9 and certain API details might change in future versions.
Cloud computing is quickly replacing traditional on premises solutions in all kinds of industries. With Apache Hadoop workloads often varying in resource requirements over time, it’s no surprise that big data engineers have started leveraging the benefits of dynamic scalability in the cloud as well.
Ensuring that the perfectly sized cluster is always available when needed, while not inducing any costs when not needed, usually requires either regularly scaling out and scaling down or even provisioning and tearing down entire clusters. At Lufthansa Industry Solutions, we have automated these operations by making use of Cloudera Director and its REST API, with Ansible being our Infrastructure as Code tool of choice. We are using the same approach for Lufthansa Technik’s AVIATAR, the new innovative platform for the aviation industry.
Cloudera Director
Cloudera Director is a lifecycle management tool for Cloudera clusters in the cloud. It is cloud service agnostic, so clusters can be spun up on Amazon Web Services, Microsoft Azure, or Google Cloud Platform all from the same Cloudera Director instance. The browser UI allows us to provision, monitor, alter, and delete clusters based on custom templates.
While Cloudera Altus is a platform-as-a-service offering streamlined for certain use cases, Cloudera Director gives us complete control over our cluster configuration. This does necessitate that Cloudera Director requires more manual input to manage and operate unlike Cloudera Altus. You can learn more about Cloudera Altus on the Cloudera web page. For the remainder of this blog post, we will focus on provisioning Cloudera clusters using Cloudera Director.
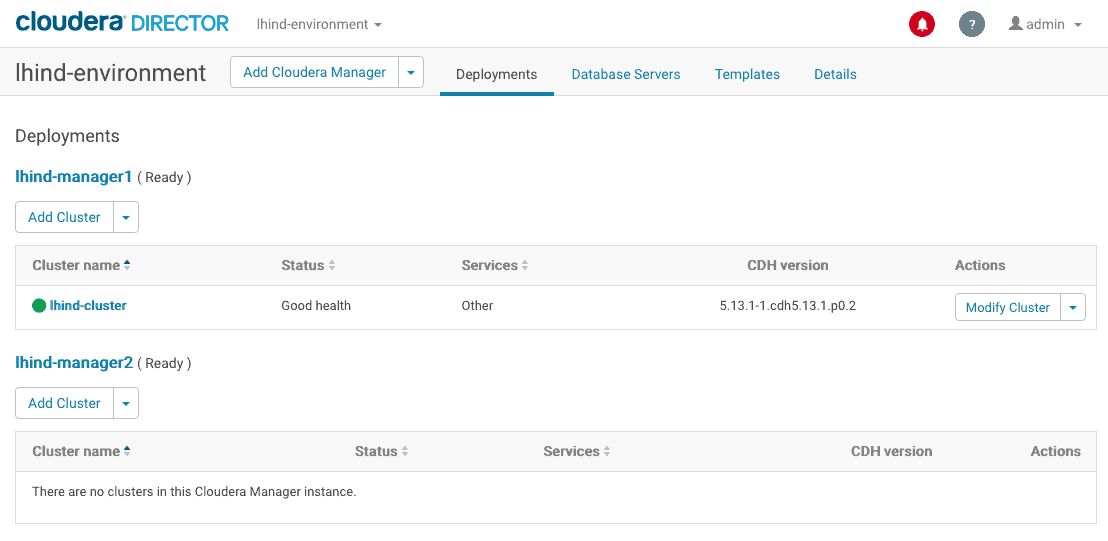
The Director’s UI is useful for exploration and development, but users typically don’t want to navigate the Director UI every time a cluster needs to be provisioned or scaled down in production, and therefore prefer the REST API.
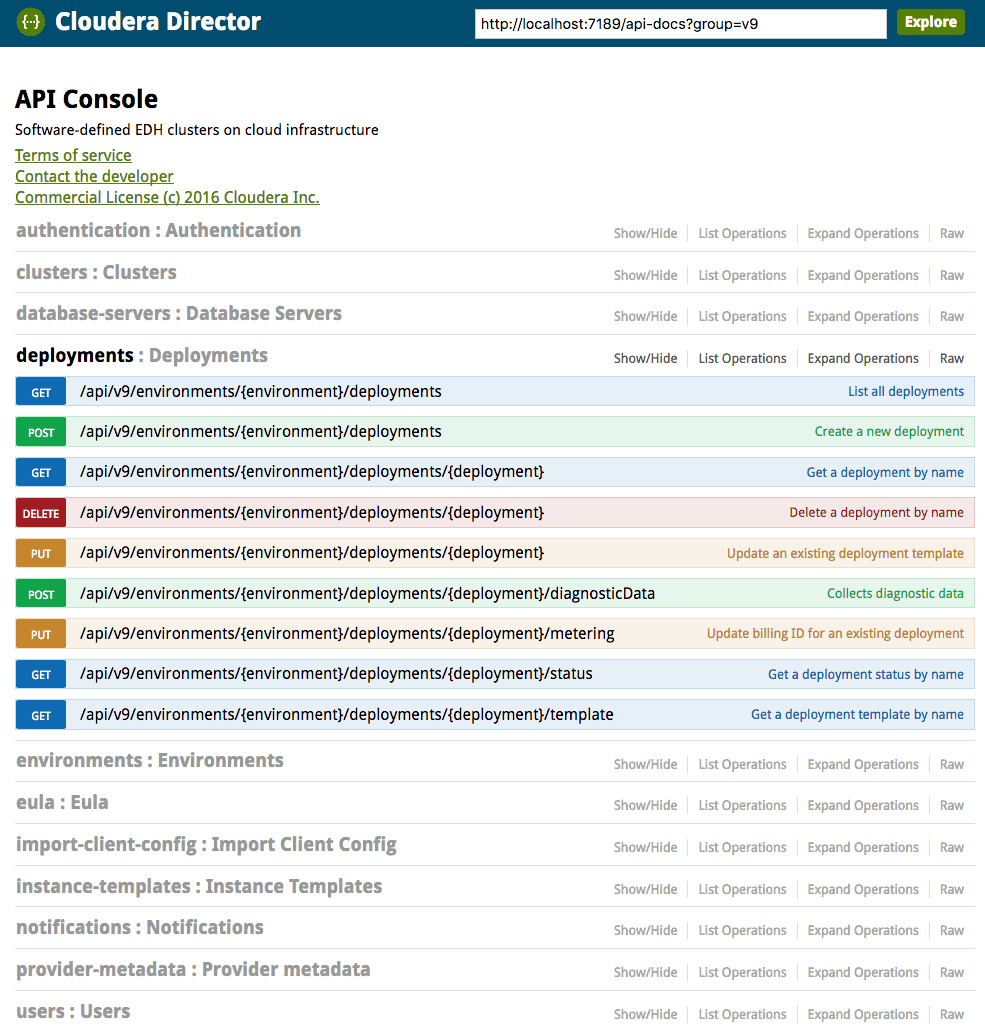
The REST endpoint provides a Swagger documentation and can be found at http://director-server-hostname:7189/api-console. It allows operations like creating, altering, and deleting clusters and storing instance templates, adding database connections, etc.
Instance and cluster templates are submitted in JSON format. A few useful reference templates are provided on GitHub. One of these templates can be a good starting point and can be customized as required.
For more advanced configurations, a good trick is to make the desired adjustments manually on a running cluster. Afterwards, the cluster template can be exported through the API to see what certain parameters translate to in the JSON templates.
Ansible
Ansible is an Infrastructure as Code tool, similar to the likes of Chef, Puppet or Terraform. One of the benefits of Ansible is its agentless architecture. It does not require its own daemons to be running on the machines it connects to and only needs SSH and Python to be installed. This imposes minimal dependencies on the environment and reduces the overhead of network traffic by pushing configuration information to the nodes rather than have the nodes constantly poll for updated information.
Ansible can be executed from the command line on any client machine with sufficient connectivity and permissions to reach the hosts that need to be configured by the playbook. If you want to further automate your setup and make it easier to trigger by end users, you might consider Red Hat’s Ansible Tower or open source alternatives like Semaphore, Tensor or others. Most of them offer features like a REST API, browser GUI or scheduling of playbooks.
The automation we are discussing in this post could be also achieved with other automation tools, depending on what you feel most comfortable with or what fits your use case best.
Letting Ansible Play With Cloudera Director
Ansible and Cloudera Director can work together as illustrated in the figure below. Ansible playbooks assemble JSON templates and submit them to Cloudera Director via its REST API. Cloudera Director then provisions clusters in the cloud.

For the purpose of this example we will assume that there is a Cloudera Director instance running at http://director.lhind.de:7189. Based on this we will have the following endpoints:
- Swagger documentation for the REST API:
http://director.lhind.de:7189/api-console - Base endpoint for all API calls: http://director.lhind.de:7189/api/v9
We’ll also assume we already have an environment named lhind-environment set up on our Director instance.
1. Creating a Deployment (aka Cloudera Manager Instance)
Before we can provision a cluster, we need a Cloudera Manager instance to deploy it into, just like in an on premises environment. In Cloudera Director, Cloudera Manager instances are called deployments. To create a deployment, we issue a POST request to the endpoint http://director.lhind.de:7189/api/v9/environments/lhind-environment/deployments, passing it a JSON model like the following:
lhind-manager.json:
{
"name": "lhind-manager",
"configs": {
"CLOUDERA_MANAGER": {
"custom_banner_html": "LHInd Manager",
"KDC_TYPE": "MIT KDC",
"KDC_HOST": "kdc.lhind.de",
"SECURITY_REALM": "CLOUDERA.LHIND.DE",
"KRB_MANAGE_KRB5_CONF": true,
"KRB_ENC_TYPES": "aes256-cts aes128-cts des3-hmac-sha1 arcfour-hmac des-hmac-sha1 des-cbc-md5 des-cbc-crc"
}
},
"username": "lhind_admin",
"password": "secret",
"enableEnterpriseTrial": false,
"javaInstallationStrategy": "NONE",
"krbAdminUsername": "kerberos_admin",
"krbAdminPassword": "secret",
"unlimitedJce": true,
"repository": "http://archive.cloudera.com/cm5/redhat/7/x86_64/cm/5.13/",
"repositoryKeyUrl": "http://archive.cloudera.com/cm5/redhat/7/x86_64/cm/RPM-GPG-KEY-cloudera",
"cmVersion": "5.13",
"csds": [],
"postCreateScripts": [
"#!/bin/sh\n\n #Insert some meaningful post create tasks here"
],
"license": "<license>",
"billingId": "<billing id>",
"managerVirtualInstance": {
"id": "<randomly generated id>",
"template": {
"name": "lhind-manager",
"type": "STANDARD_DS12_V2",
"image": "cloudera-centos-72-latest",
"bootstrapScripts": [
"Redacted for better readibility. Default bootstrap scripts can be found at https://github.com/cloudera/director-scripts"
],
"config": {
"virtualNetwork": "director-vnet",
"virtualNetworkResourceGroup": "director-rg",
"availabilitySet": "asedge",
"computeResourceGroup": "director-rg",
"networkSecurityGroupResourceGroup": "director-rg",
"storageAccountType": "PremiumLRS",
"subnetName": "default",
"dataDiskCount": "1",
"dataDiskSize": "1023",
"networkSecurityGroup": "director-vnet-nsg",
"publicIP": "No",
"instanceNamePrefix": "manager",
"hostFqdnSuffix": "demo.lhind.de"
},
"tags": {
"application": "Cloudera Manager 5",
"owner": "lhind"
},
"normalizeInstance": true
}
},
"externalDatabaseTemplates": {
"CLOUDERA_MANAGER": {
"name": "cmtemplate",
"databaseServerName": "directordb",
"databaseNamePrefix": "scm",
"usernamePrefix": "cmadmin"
},
"NAVIGATORMETASERVER": {
"name": "navmetatemplate",
"databaseServerName": "directordb",
"databaseNamePrefix": "navmeta",
"usernamePrefix": "nmadmin"
},
"ACTIVITYMONITOR": {
"name": "amontemplate",
"databaseServerName": "directordb",
"databaseNamePrefix": "amon",
"usernamePrefix": "amadmin"
},
"NAVIGATOR": {
"name": "navtemplate",
"databaseServerName": "directordb",
"databaseNamePrefix": "nav",
"usernamePrefix": "nadmin"
},
"REPORTSMANAGER": {
"name": "rmantemplate",
"databaseServerName": "directordb",
"databaseNamePrefix": "rman",
"usernamePrefix": "rmadmin"
}
},
"externalDatabases": {}
}
A few things to look out for:
- managerVirtualInstance: This block describes the virtual machine as requested from the respective cloud provider. This example is valid for an Azure VM – if we were using AWS or GCP, it would look slightly different.
- UUID: The virtual instance’s ID needs to be random and unique for every deployment instance that’s provisioned through the Director. We’ll therefore automate a random generation and insert it into the template with Ansible before submitting it.
- Scripts: Both the bootstrap script and the post create scripts are useful if there’s any custom configuration you’d like to perform on your Cloudera Manager VM before or after deploying the Cloudera Manager software itself. They’re redacted here for better readability, but default bootstrap scripts can be found on GitHub.
[Playbook] Iteration 1: Submitting a JSON Template
The template above is all we need to submit to Cloudera Director to set up a deployment instance. To automate this with Ansible, we’ll make use of the uri module. The first iteration of our playbook looks like the following:
create_deployment.yml:
---
- hosts: localhost
gather_facts: false
tasks:
- name: Load template from file
set_fact:
deploymentTemplate: "{{ lookup('file', '/path/to/lhind-manager.json')}}"
- name: Create deployment
uri:
url: "http://director.lhind.de:7189/api/v9/environments/lhind-environment/deployments"
method: POST
user: "lhind_admin"
password: "secret"
force_basic_auth: yes
body: "{{ deploymentTemplate }}"
body_format: json
status_code: 201
We could now run the playbook with ansible-playbook create_deployment.yml, which would trigger the provisioning of our deployment instance.
[Playbook] Iteration 2: Extracting Variables
Next, to make things more generic, we’ll extract all parameters to variables and store them in a separate vars file.
vars/main.yml:
--- directorEndpoint: "http://director.lhind.de:7189/api/v9/" directorEnvironment: "lhind-environment" directorUser: "lhind_admin" directorPassword: "secret"
The playbook now looks like this:
create_deployment.yml:
---
- hosts: localhost
gather_facts: false
vars_files:
- vars/main.yml
tasks:
- name: Load template from file
set_fact:
deploymentTemplate: "{{ lookup('file', '/path/to/lhind-manager.json')}}"
- name: Create deployment
uri:
url: "{{ directorEndpoint }}/environments/{{ directorEnvironment }}/deployments"
method: POST
user: "{{ directorUser }}"
password: "{{ directorPassword }}"
force_basic_auth: yes
body: "{{ deploymentTemplate }}"
body_format: json
status_code: 201
[Playbook] Iteration 3: Encrypting Sensitive Information With ansible-vault
Of course, we don’t want to store things like the Cloudera Director password or other sensitive information in plain text in a vars file. This is where the Ansible Vault comes into play. We’ll move directorPassword to a second vars file:
vars/vault.yml:
--- directorPassword: "secret"
To encrypt this file we’ll use the ansible-vault command: ansible-vault encrypt vars/vault.yml, which will prompt us for a password that can be used to decrypt it in the future. The vault file has to be included in our playbook:
--- - hosts: localhost gather_facts: false vars_files: - vars/main.yml - vars/vault.yml ... ...
Now when running the playbook we’ll need the --ask-vault-pass flag, which will prompt us for the password we set above:
ansible-playbook create_deployment.yml --ask-vault-pass
[Playbook] Iteration 4: Assembling the Template at Run Time
I mentioned above that every deployment instance needs a UUID. If we want to be able to automatically generate one and insert it into the template every time we run the playbook, we’ll have to find a way to dynamically assemble the JSON template at playbook run time. There are multiple ways of achieving this, but one easy way is to insert keyword strings into the template file, which can be replaced with a find/replace in the playbook. Doing this will also allow us to extract other variables from the template and make it more generic. To give you an example, we’ll extract a few sensitive parameters like the Kerberos admin password as well as the UUID from the template:
lhind-manager.json:
{
"name": "lhind-manager",
"configs": {
"CLOUDERA_MANAGER": {
"custom_banner_html": "LHInd Manager",
"KDC_TYPE": "MIT KDC",
"KDC_HOST": "kdc.lhind.de",
"SECURITY_REALM": "CLOUDERA.LHIND.DE",
"KRB_MANAGE_KRB5_CONF": true,
"KRB_ENC_TYPES": "aes256-cts aes128-cts des3-hmac-sha1 arcfour-hmac des-hmac-sha1 des-cbc-md5 des-cbc-crc"
}
},
"username": "lhind_admin",
"password": "secret",
"enableEnterpriseTrial": false,
"javaInstallationStrategy": "NONE",
"krbAdminUsername": "***KERBEROS-ADMIN***",
"krbAdminPassword": "***KERBEROS-PASSWORD***",
"unlimitedJce": true,
"repository": "http://archive.cloudera.com/cm5/redhat/7/x86_64/cm/5.13/",
"repositoryKeyUrl": "http://archive.cloudera.com/cm5/redhat/7/x86_64/cm/RPM-GPG-KEY-cloudera",
"cmVersion": "5.13",
"csds": [],
"postCreateScripts": [
"#!/bin/sh\n\n #Insert some meaningful post create tasks here"
],
"license": "<license>",
"billingId": "<billing id>",
"managerVirtualInstance": {
"id": "***VIRTUAL-INSTANCE-ID***",
"template": {
"name": "lhind-manager",
"type": "STANDARD_DS12_V2",
"image": "cloudera-centos-72-latest",
"bootstrapScripts": [
"Redacted for better readibility. Default bootstrap scripts can be found at https://github.com/cloudera/director-scripts"
],
"config": {
"virtualNetwork": "director-vnet",
"virtualNetworkResourceGroup": "director-rg",
"availabilitySet": "asedge",
"computeResourceGroup": "director-rg",
"networkSecurityGroupResourceGroup": "director-rg",
"storageAccountType": "PremiumLRS",
"subnetName": "default",
"dataDiskCount": "1",
"dataDiskSize": "1023",
"networkSecurityGroup": "director-vnet-nsg",
"publicIP": "No",
"instanceNamePrefix": "manager",
"hostFqdnSuffix": "demo.lhind.de"
},
"tags": {
"application": "Cloudera Manager 5",
"owner": "lhind"
},
"normalizeInstance": true
}
},
"externalDatabaseTemplates": {
"CLOUDERA_MANAGER": {
"name": "cmtemplate",
"databaseServerName": "directordb",
"databaseNamePrefix": "scm",
"usernamePrefix": "cmadmin"
},
"NAVIGATORMETASERVER": {
"name": "navmetatemplate",
"databaseServerName": "directordb",
"databaseNamePrefix": "navmeta",
"usernamePrefix": "nmadmin"
},
"ACTIVITYMONITOR": {
"name": "amontemplate",
"databaseServerName": "directordb",
"databaseNamePrefix": "amon",
"usernamePrefix": "amadmin"
},
"NAVIGATOR": {
"name": "navtemplate",
"databaseServerName": "directordb",
"databaseNamePrefix": "nav",
"usernamePrefix": "nadmin"
},
"REPORTSMANAGER": {
"name": "rmantemplate",
"databaseServerName": "directordb",
"databaseNamePrefix": "rman",
"usernamePrefix": "rmadmin"
}
},
"externalDatabases": {}
}
Now all we have to do in our playbook is replace the keywords ***VIRTUAL-INSTANCE-ID***, ***KERBEROS-ADMIN*** and ***KERBEROS-PASSWORD*** with their respective values.
We’ll encrypt the Kerberos password in our Ansible Vault and use uuidgen to generate a random ID. We’ll also set no_log to true, so that the sensitive parameters don’t get logged when they’re inserted.
create_deployment.yml:
---
- hosts: localhost
gather_facts: false
vars_files:
- vars/main.yml
- vars/vault.yml
tasks:
- name: Load template from file
set_fact:
deploymentTemplate: "{{ lookup('file', '/path/to/lhind-manager.json')}}"
- name: Generate UUID
command: "uuidgen"
register: uuid
- name: Add UUID
set_fact:
assembledTemplate: "{{ deploymentTemplate | replace('***UUID***', uuid.stdout) }}"
no_log: true
- name: Add Kerberos user and password
set_fact:
assembledTemplate: "{{ assembledTemplate | replace('***KERBEROS-ADMIN***', kerberosAdmin) | replace('***KERBEROS-PASSWORD***', kerberosPassword) }}"
no_log: true
- name: Create deployment
uri:
url: "{{ directorEndpoint }}/environments/{{ directorEnvironment }}/deployments"
method: POST
user: "{{ directorUser }}"
password: "{{ directorPassword }}"
force_basic_auth: yes
body: "{{ deploymentTemplate }}"
body_format: json
status_code: 201
vars/vault.yml:
--- directorPassword: "secret" kerberosAdmin: "lhind-admin" kerberosPassword: "secret"
The same pattern can, of course, be applied to many more parameters in the template. This was just an example to give you an idea of how it can work.
[Playbook] Further Steps:
Some further optimizations you might want to take into account:
- Make use of Ansible Roles to create reusable roles and give your playbook some structure, especially as it grows larger.
- Make the template and playbook more generic. For example, allow for different templates to be run from the same playbook or make the basic JSON structure configurable entirely through variables.
2. Provisioning a Cluster Within the Deployment
Now that we have a deployment, we’re ready to spin up a cluster on top of it. The JSON template for this is slightly more complex than for a deployment, but we can make use of the same mechanisms to assemble and submit it with Ansible as we did before.
Skipping a few of the iterations we did above, the template might look like the following:
lhind-cluster.json:
{
"name": "lhind-cluster",
"productVersions": {
"CDH": "5",
},
"services": [
"HDFS",
"HIVE",
"HUE",
"IMPALA",
"OOZIE",
"YARN",
"SPARK_ON_YARN",
"ZOOKEEPER"
],
"servicesConfigs": {
"ZOOKEEPER": {
"enableSecurity": "true"
},
"HDFS": {
"hadoop_security_authorization": "true",
"hadoop_security_authentication": "kerberos"
}
},
"virtualInstanceGroups": {
"edge": {
"name": "edge",
"virtualInstances": ***EDGE-INSTANCES***,
"minCount": 0,
"serviceTypeToRoleTypes": {
"SPARK_ON_YARN": [
"GATEWAY"
],
"HIVE": [
"GATEWAY"
],
"HDFS": [
"GATEWAY"
],
"YARN": [
"GATEWAY"
]
},
"roleTypesConfigs": {}
},
"data": {
"name": "data",
"virtualInstances": ***DATA-INSTANCES***,
"minCount": 3,
"serviceTypeToRoleTypes": {
"HDFS": [
"DATANODE"
],
"IMPALA": [
"IMPALAD"
],
"YARN": [
"NODEMANAGER"
]
},
"roleTypesConfigs": {}
},
"masters": {
"name": "masters",
"virtualInstances": ***MASTER-INSTANCES***,
"minCount": 1,
"serviceTypeToRoleTypes": {
"HIVE": [
"HIVEMETASTORE",
"HIVESERVER2"
],
"HUE": [
"HUE_SERVER"
],
"ZOOKEEPER": [
"SERVER"
],
"OOZIE": [
"OOZIE_SERVER"
],
"HDFS": [
"NAMENODE",
"SECONDARYNAMENODE",
"BALANCER"
],
"IMPALA": [
"CATALOGSERVER",
"STATESTORE"
],
"YARN": [
"RESOURCEMANAGER",
"JOBHISTORY"
],
"SPARK_ON_YARN": [
"SPARK_YARN_HISTORY_SERVER"
],
},
"roleTypesConfigs": {}
}
},
"externalDatabaseTemplates": {
"HIVE": {
"name": "hivetemplate",
"databaseServerName": "directordb",
"databaseNamePrefix": "hivedb"
},
"HUE": {
"name": "huetemplate",
"databaseServerName": "directordb",
"databaseNamePrefix": "huedb"
},
"OOZIE": {
"name": "oozietemplate",
"databaseServerName": "directordb",
"databaseNamePrefix": "ooziedb"
}
},
"parcelRepositories": [
"http://archive.cloudera.com/cdh5/parcels/5.13/",
],
"instancePostCreateScripts": [
"#!/bin/sh\n\n #Executed on every cluster node."
],
"postCreateScripts": [
"#!/bin/sh\n\n #Executed on one random cluster node."
]
}
The main difference when compared to the deployment template, are the different virtual instance groups for cluster node types, with respective service roles assigned to each type.
What’s missing here are the virtualInstances lists describing the VM specifications for each group. The API expects one virtualInstances object for each node in a group. So if, for example, we want three data nodes, we’ll have to submit a list of three identical instance objects. Each instance will again need a UUID. So to avoid code duplication and generate a UUID for each instance, we’ll assemble the instance list using a simple shell script, taking a single instance template and the number of replications as inputs:
assemble_instances.sh:
#!/bin/sh templatePath=$1 instanceList="" i=0 # loop counter n=$2 # total number of instances while [ $i -lt $n ] do # Generate lower case UUID for new instance uuid=`uuidgen` # Add UUID to template assembledInstance=`sed 's/***UUID***/'"$uuid"'/' $templatePath` # Append assembled instance to list instanceList="$instanceList $assembledInstance" # If this is not the last instance in the list, append a comma if [ $i -lt $((n-1)) ]; then instanceList="$instanceList," fi let i=i+1 done # Return list of instance templates with UUIDs echo "[$instanceList]"
A single instance template is stored in a separate file (this is an example for a data node. Slightly different versions will be needed for edge and master node templates):
lhind-datanode.json:
{
"id": "***UUID***",
"template": {
"name": "lhind-data",
"type": "STANDARD_DS15_V2",
"image": "cloudera-centos-72-latest",
"bootstrapScripts": [
"Redacted for better readibility. Default bootstrap scripts can be found at https://github.com/cloudera/director-scripts"
],
"config": {
"virtualNetwork": "director-vnet",
"virtualNetworkResourceGroup": "director-rg",
"availabilitySet": "asworker",
"computeResourceGroup": "director-rg",
"networkSecurityGroupResourceGroup": "director-rg",
"storageAccountType": "PremiumLRS",
"subnetName": "default",
"dataDiskCount": "1",
"dataDiskSize": "1023",
"networkSecurityGroup": "director-vnet-nsg",
"publicIP": "No",
"instanceNamePrefix": "data",
"hostFqdnSuffix": "demo.lhind.de"
},
"tags": {},
"normalizeInstance": true
}
}
Finally we can put everything together in a playbook:
create_cluster.yml:
---
- hosts: localhost
gather_facts: false
vars_files:
- vars/main.yml
- vars/vault.yml
tasks:
- name: Load cluster template from file
set_fact:
skeletonTemplate: "{{ lookup('file', '/path/to/lhind-cluster.json') }}"
# Assemble instance lists for each instance group type
- name: Assemble data node instances
script: "assembleInstances.sh /path/to/lhind-data.json 3"
register: assembledDataInstances
- name: Assemble master node instances
script: "assembleInstances.sh /path/to/lhind-master.json 1"
register: assembledMasterInstances
- name: Assemble edge node instances
script: "assembleInstances.sh /path/to/lhind-edge.json 1"
register: assembledEdgeInstances
# Insert instance lists into cluster template
- name: Insert data instances object into skeleton template
set_fact:
assembledClusterTemplate: "{{ skeletonTemplate | replace('***DATA-INSTANCES***', assembledDataInstances.stdout) }}"
- name: Insert master instances object into skeleton template
set_fact:
assembledClusterTemplate: "{{ assembledClusterTemplate | replace('***MASTER-INSTANCES***', assembledMasterInstances.stdout) }}"
- name: Insert edge instances object into skeleton template
set_fact:
assembledClusterTemplate: "{{ assembledClusterTemplate | replace('***EDGE-INSTANCES***', assembledEdgeInstances.stdout) }}"
# Submit assembled template to API
- name: Create cluster
uri:
url: "{{ directorEndpoint }}/{{ directorEnvironment }}/deployments/lhind-manager/clusters"
method: POST
user: "{{ directorUser }}"
password: "{{ directorPassword }}"
force_basic_auth: yes
body: "{{ assembledClusterTemplate }}"
body_format: json
status_code: 201
Again these examples are fairly hard coded to get the overall idea across. There’s endless possibilities to extract variables and make them more generic. For more advanced setups like a high availability configuration, see GitHub.
Next Steps
Once we have a running cluster, we’ll soon want to scale it down or out depending on the resources required by our dynamic workload. This is also supported by Cloudera Director and can therefore be automated. Hopefully, this post gives you a good idea on how to get started with automating your CDH cloud setup and we look forward to discussing optimizations or hearing about your own approaches. Feel free to get in touch in the comments below.
Useful Resources
- Director REST API Swagger: <Cloudera Director endpoint>/api-console
- JSON Templates on GitHub: https://github.com/cloudera/director-scripts
- Ansible Best Practices: http://docs.ansible.com/ansible/latest/playbooks_best_practices.html
Note: Learn more about Ansible here. Cloudera does not distribute or support Ansible.
Editor's Choice

