


Fine grained access control (FGAC) with Spark
Apache Spark with its rich data APIs has been the processing engine of choice in a wide range of applications from data engineering to machine learning, but its security integration has been a pain point. Many enterprise customers need finer granularity of control, in particular at the column and row level (commonly known as Fine Grained Access Control or FGAC). The challenges of arbitrary code execution notwithstanding, there have been attempts to provide a stronger security model but with mixed results. One approach is to use 3rd party tools (such as Privacera) that integrate with Spark. However, it not only increases costs but requires duplication of policies and yet another external tool to manage. Other approaches also fall short by serving as partial solutions to the problem. For example, EMR plus Lake Formation makes a compromise by only providing column level security but not controlling row filtering.
That’s why we are excited to introduce Spark Secure Access, a new security feature for Apache Spark in the Cloudera Data Platform (CDP), that adheres to all security policies without resorting to 3rd party tools. This makes CDP the only platform where customers can use Spark with fine grained access control automatically, without requiring any additional tools or integrations. Customers will now get the same consistent view of their data with the analytic processing engine of their choice without any compromises.
SDX
Within CDP, Shared Data Experience (SDX) provides centralized governance, security, cataloging, and lineage. And at its core, Apache Ranger serves as the centralized authorization repository – from databases down to individual columns and rows. Analytic engines like Apache Impala adhere to these SDX policies ensuring users see the data they are granted by applying column masking and row filtering as needed. Until now, Spark partially adhered to these same policies providing coarse grained access – only at the level of database and tables. This limited usage of Spark at security-conscious customers, as they were unable to leverage its rich APIs such as SparkSQL and Dataframe constructs to build complex and scalable pipelines.
Introducing Spark Secure Access Mode
Starting with CDP 7.1.7 SP1 (announced earlier this year in March), we introduced a new access mode with Spark that adheres to the centralized FGAC policies defined within SDX. In the coming months we will enhance this to make it even easier with minimal to no code changes in your applications, while being performant and without limiting the Spark APIs used.
First a bit of background: Hive Warehouse Connector (HWC) was introduced as a way for Spark to access data through Hive, but was historically limited to small datasets from using JDBC. So, a second mode was introduced called “Direct Access,” which overcame the performance bottleneck but with one key downside – the inability to apply FGAC. Direct Access mode did adhere to Ranger table level access, but once the check was performed, the Spark application would still need direct access to the underlying files circumventing more fine grained access that would otherwise limit rows or columns.
The introduction of “Secure Access” mode to HWC avoids these drawbacks by relying on Hive to obtain a secure snapshot of the data that is then operated upon by Spark. If you are already a user of HWC, you can continue using hive.executeQuery() or hive.sql() in your Spark application to obtain the data securely.
val session = com.hortonworks.hwc.HiveWarehouseSession.session(spark).build() val df = session.sql("select name, col3, col4 from table").show df.show()
By leveraging Hive to apply Ranger FGAC, Spark obtains secure access to the data in a protected staging area. Since Spark has direct access to the staged data, any Spark APIs can be used, from complex data transformations to data science and machine learning.
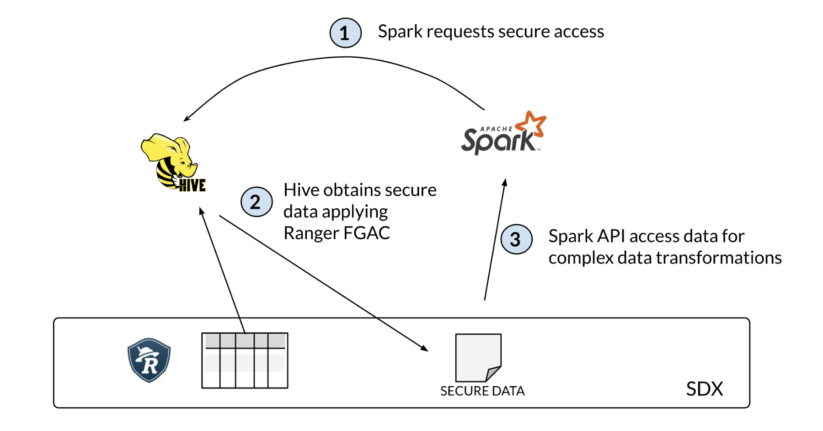
This handshake between Spark and Hive is transparent to the user, automatically passing the request to Hive applying Ranger FGAC, generating the secure filtered and masked data in a staging directory, and the subsequent cleanup once the session is closed.
Running Spark job
As a user, you need to specify two key configurations in the spark job:
- The staging directory:
spark.datasource.hive.warehouse.load.staging.dir=hdfs://…/tmp/staging/hwc - The access mode:
spark.datasource.hive.warehouse.read.mode=secure_access
Setting up secure access mode
As an administrator, you can set up the required configuration in Cloudera Manager for Hive and in Ranger UI.
Setup data staging area within HDFS and grant the required policies within Ranger to allow the user to perform: read, write, and execute on the staging path.
Follow the steps outlined here.
Early feedback from customers
From early previews of the feature, we have received positive feedback, in particular customers migrating from legacy HDP to CDP. With this feature, customers can replace HDP’s HWC legacy LLAP execution mode with HWC Secure Access mode in CDP. One customer reported that they have adopted HWC secure access mode without much code refactoring from HWC LLAP execution mode. The customer also experienced equal or better performance with the simpler architecture in CDP.
What’s Next
We are excited to introduce HWC secure access mode, a more scalable and performant solution for customers to securely access large datasets in our upcoming CDP Base releases. This applies to both Hive tables and views, allowing Spark based data engineering to benefit from the same FGAC policies that SQL and BI analysts get from Impala. For those eager to get started, CDP 7.1.7 SP1 will provide the key benefits outlined above. Reach out to your account teams on upgrading to the latest release.
In a follow-up blog, we will provide more detail and discuss the enhancements we have planned for the next release with CDP 7.1.8, so stay tuned!
Learn more on how to use the feature from our public documentation.
Editor's Choice

