

Apache Phoenix for CDH: Best New Feature for DBMS
Cloudera is adopting and will be supporting Apache Phoenix for CDH while it integrates it for its Cloudera Data Platform on a go-forward basis.
{kind=link}
Cloudera’s CDH releases have included Apache HBase which provides a resilient, NoSQL DBMS for customers operational applications that want to leverage the power of big-data. These applications have grown into mission important and mission critical applications that drive top-line revenue and bottom-line profitability. These applications include customer facing applications, ecommerce platforms, risk & fraud detection used behind the scenes at banks or serving AI/ML models for applications and enabling further reinforcement training of the same based on actual outcomes.
However, for many customers, HBase has been too daunting a journey — requiring them to learn
- A new data model as HBase is a wide-table schema supporting millions of columns but no joins and
- Using Java APIs instead of ANSI SQL
They have asked to be able to use more traditional schema design that resembles that provided by Oracle or MySQL and been willing to make some trade-offs on flexibility e.g.,
- They are willing to use provided data types instead of defining their own
- They are willing to give up the flexibility to have a single column have multiple types depending on the row in exchange for a single type in a single row
To enable customers to have an easy on-ramp to the other benefits of Apache HBase (unlimited scale-out, millions of rows, schema evolution, etc) while providing RDBMS-like capabilities (ANSI SQL, simple joins, data types out of the box, etc), we are introducing support for Apache Phoenix on CDH.
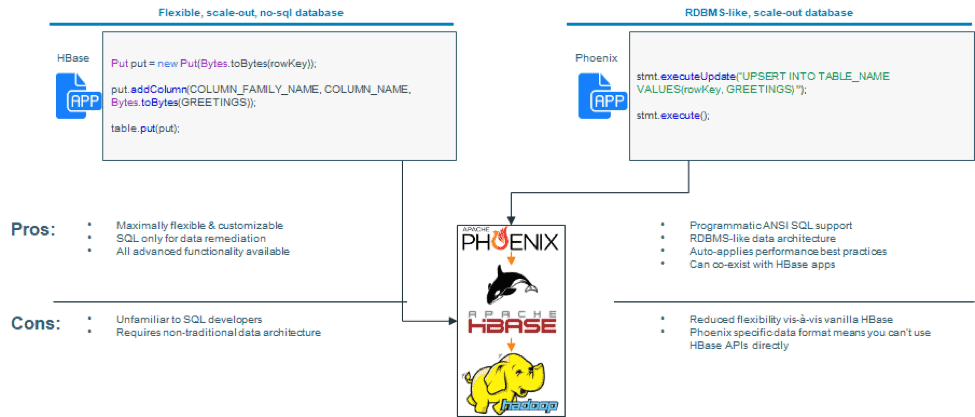
For everyone else, Phoenix based applications also benefit from behind-the-scenes HBase optimizations, making it easier to get better HBase performance. For example, Phoenix implements salting of primary keys — so HBase users don’t have to think through this aspect of key design.
Further, Phoenix based applications can co-exist with HBase applications — meaning you can use a single HBase cluster to support both. With Phoenix, customers can continue to use their favorite BI & dashboarding tools just like they did with Hive & Impala in the past. When using Phoenix, they can also choose to directly use Phoenix with those tools in addition to the option of using Hive / Impala eliminating a step for new implementations.
From a security and governance perspective (SDX), in CDH, Phoenix uses HBase ACLs for role based access control for Phoenix tables. Phoenix also uses HBase integration into Cloudera Navigator for audit information.
Cloudera has released a Phoenix 4.14.1 parcel available to CDH 5.16.2 customers and Phoenix 5.0 parcel available to CDH 6.2+ customers.
Existing HDP customers already have Apache Phoenix support and almost half of HBase users using HDP currently use Phoenix as well speaking to its popularity in the HBase user community.
Download Apache Phoenix for CDH
Build mission-critical applications using Apache Phoenix. Download the software here.
Frequently asked questions about Phoenix
Q) What are the workloads that Phoenix should be used for
Phoenix supports the same use cases as HBase, primarily low-latency, high concurrency workloads. However, Phoenix makes it simpler to also leverage the underlying data for dashboarding & BI purposes
Q) What is the authorization mechanism with Phoenix?
Phoenix depends on HBase for authorization. For CDH customers, this utilizes HBase ACLs. For HDP customers, this is through HBase-Ranger integration
Q) What’s the scalability of Phoenix? What’s the largest known cluster?
Phoenix scales to hundreds of TB of data. The largest customer has over 0.5 PB of data that is managed by Phoenix. Specifics on use cases can be found in the PhoenixCon archives and in the archives for NoSQL day videos earlier this year in users own words & slides.
Q) Does Phoenix support geo spatial secondary indexing? What level of support spatial data?
It has limited support for geo-spatial data. However, GeoMesa provides a geospatial layer on HBase that can support this need and integrated with customer applications. Phoenix, GeoMesa as well as JanusGraph and OpenTSDB can all co-exist in a single HBase cluster.
Q) How do you create and use an Index?
See Phoenix Secondary Indexing page for details on indexing. From Phoenix 4.8.0 onward, no configuration changes are required to use local indexing.
Q) Is there a limit on number of columns you can put on index?
Like in an RDBMS, an index is essentially a separate table with the index and a link to the source data. If you index all columns you defeat the purpose by maintaining two identical tables. Indexes should be used judiciously as there is some non-trivial overhead on write (global indexes) or read (local indexes).
Editor's Choice


Hi Krishna, you write about GeoMesa in CDH, but our engineers looked into this and it seems that GeoMesa does not support the HBase and Accumulu versions which are deployed in CDH6?
If so – how can we store and index Geo data in CDH6?
Thanks!
You are correct. GeoMesa supports HBase in CDH 5.16 and HBase in CDP. GeoMesa docs indicate support for the HBase version in CDH is experimental.
i hope use phoenix for cdh 6
Please reach out to your Cloudera account team. Phoenix is available for CDH 6.