

There are many ways that Apache Kafka has been deployed in the field. In our Kafka Summit 2021 presentation, we took a brief overview of many different configurations that have been observed to date. In this blog series, we will discuss each of these deployments and the deployment choices made along with how they impact reliability. In Part 1, the discussion is related to: Serial and Parallel Systems Reliability as a concept, Kafka Clusters with and without Co-Located Apache Zookeeper, and Kafka Clusters deployed on VMs.
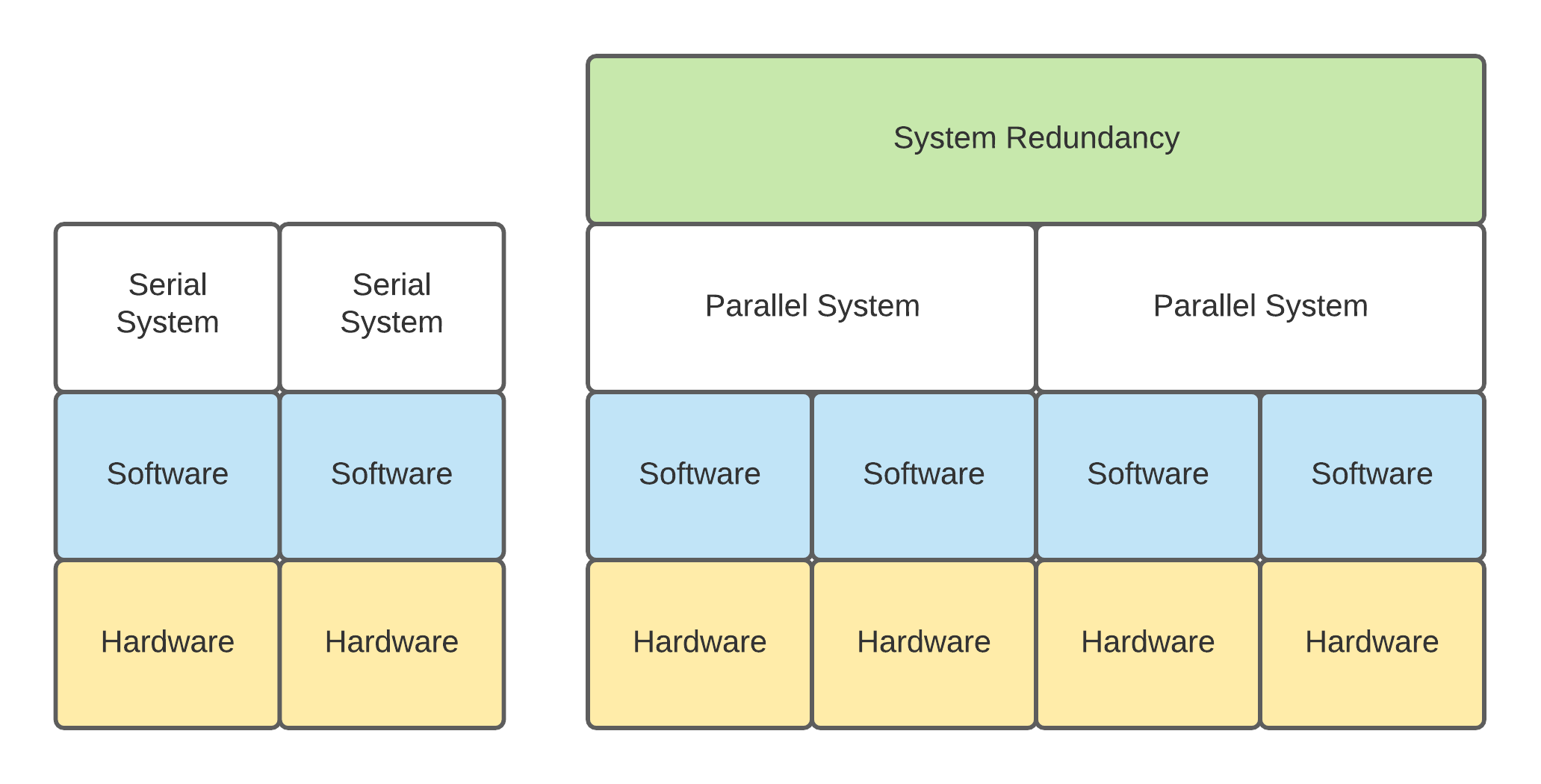
Serial and Parallel Systems Reliability
Systems Reliability can be thought of as how long a system can operate correctly before it enters a bad state without the need for maintenance or outsider actions to resolve problems with the system itself. This reliability can be seen as two types: Serial Reliability and Parallel Reliability. Kafka clusters experience a mixture of both of these types of reliability and while beyond the scope of this series to calculate and mix both together we will reference and discuss some of things in each deployment type that can impact the Serial and Parallel Reliability of the deployment topology itself. There are also differing layers you can perform this analysis on to try and decide how reliable parts of a system are. From very low levels, you can look at how the hardware itself is deployed, going higher you can look at the cluster deployment and beyond that you can get into systems that have cluster redundancy such as system disaster recovery and come to different conclusions about the reliability at each layer.
Serial Systems Reliability
With a Serial System, reliability depends on every component in the system to continue operating. The failure of a single component will result in the system becoming unavailable. There are many things like this that people experience in daily life that fall into the serial system bucket, perhaps one of the most pervasive is an automobile. If the battery in your automobile stops functioning, you’re no longer able to start and utilize the vehicle (system) until that component is repaired. The vehicle also has other components that operate in this fashion such as the fuel pump, ECU, and even the tires. While there are four tires, all four are required to operate the vehicle, its performance is significantly degraded when operating without all 4 tires to the point it likely should not be utilized short of harming components on the system like the wheel hubs more.
Kafka as software falls more cleanly into the Parallel Systems Reliability discussed below but some parts of it can end up Serial. Specifically hardware infrastructure in my experience has a greater chance of serial based failures. For example running an OS disk on the server which is not in a RAID configuration that provides redundancy will result in a serial reliability calculation for the disk which the Kafka Broker will be dependent on for operation. Servers with only 1 network drop relay on the networking card, cable, and switch to continue operating and all present a serial reliability issue if not deployed in a Highly Available redundant fashion.
Mathematically a Serial System Reliability can be described as the following, where adding more components will continue to weaken the system.
Rs= R1* R2… Rn
RS is the Reliability of the total system
R1, R2, Rn… is the reliability of each component in the system 1 being the first, 2 being the second and n being however many n components there are.
For example a serial system with 90% reliable components
- 2 components
- 90% * 90% = 81% system reliability
- 4 components
- 90% * 90% * 90% * 90% = 65% system reliability
Parallel Systems Reliability
With a Parallel System, Reliability on having one component online results in the system remaining online, some may equate this with redundancy or high availability. With Kafka, this is a bit more complex than just having additional brokers which are parallely available. There are multiple aspects to the software reliability of the topic being hosted: replicas, and minimum in-sync replicas. While not a perfect example of Parallel Systems, one familiar to most would be our own eyes and ears which provide redundant functionality. Should an ear or eye stop working you can continue to see and hear, the reason I feel this is a poor example is that the performance of your sight and hearing are reduced even though continuing to function.
Mathematically Parallel System Reliability can be described as the following, where adding more components will continue to strengthen the system.
Rs= 1 - (1 -R1) *(1-R2) … (1-Rn)
For example a parallel system with 90% reliable components
- 2 components
- 1-(1-0.90)*(1-0.90) = 99.00% system reliability
- 4 components
- 1-(1-0.90)*(1-0.90)*(1-0.90)*(1-0.90) = 99.99% system reliability
When thinking about parallel reliability within Kafka, as aforementioned, it has a lot to do with the topic replicas, producer acks and in-sync replicas. This configurability brings Kafka a lot of tunability where other systems like Zookeeper have a fixed configuration that cannot be changed.
A topic with any number of partitions but only 1 replica has no parallel copies of the data available, in the event that one replica is lost due to a broker failure that the entire partition is offline for the topic making it unable to accept reads or writes. Should the topic utilizing greater than 1 replica it then has parallel copies of itself which are able to withstand the failure of a broker keeping the data online for reads and potentially writes.
Producer acknowledgements (acks) is one way that message durability is controlled with topic writes. There are 3 ways a producer can be configured to acknowledge that a messages have been written to the broker: acks=0 which is a fire and forget without waiting for a broker to ack and the least durable providing no guarantee, acks=1 which waits for the write to the leader replica on a broker to be acknowledged, and acks=all which is the most durable and writes to a minimum number of in-sync replicas for the given partition.
Writes when using a producer with acks=all depends on the minimum in-sync replicas which are replicas based on configurations (min-insync.replicas & replica.lag.time.max.ms) considered to be current (and non-lagging) copies of the leader replica. The min-insync.replica configuration then helps provide message durability guarantees by allowing or disallowing writes should the cluster be taken into a degraded state; such as not having enough replicas online due to broker or hard-drive failures to meet the min requirements or should it start replicating slowly for some reason beyond the time set by replica.lag.time.max.ms. You may have realized that the min-insync.replica does not provide system availability and feels as if it works against keeping the system online but this is the tradeoff made in order to have durable messages (prevent message loss in the system) there is no free lunch as they say. Of course should you not care about durability of messages (acceptable to lose messages) one can always enable unclean.leader.election.enable=true at a cluster or topic level, with this setting even if all in-sync replicas are lost the topic will continue to operate and accept writes.
In a system utilizing unclean.leader.election.enable=true and replicas are less than or equal to the number of brokers in the cluster then the number of components in the parallel system reliability formula can be thought of as the number of replicas. When viewing the system as a whole this may not be exactly correct because there could be multiple serial components under-pinning the cluster such as the network core or operating system hard drives for the server that may reduce the reliability of the topic but from a cluster perspective the topic can be thought of as having the given parallel reliability.
Kafka Clusters with and without Co-Located Zookeeper
One of the current dependencies that running a Kafka cluster has is on having a Zookeeper quorum, and while the community is working on a KRaft implementation that will be able to replace Zookeeper at the time of writing this it is unavailable outside of an early access form that would not be recommended for production. How you deploy Zookeeper can matter greatly to the reliability of your Kafka Cluster the below diagram shows a number of ways smaller 3 node Kafka Clusters have been deployed, these are not the only possible permutations but some of the most common seen.
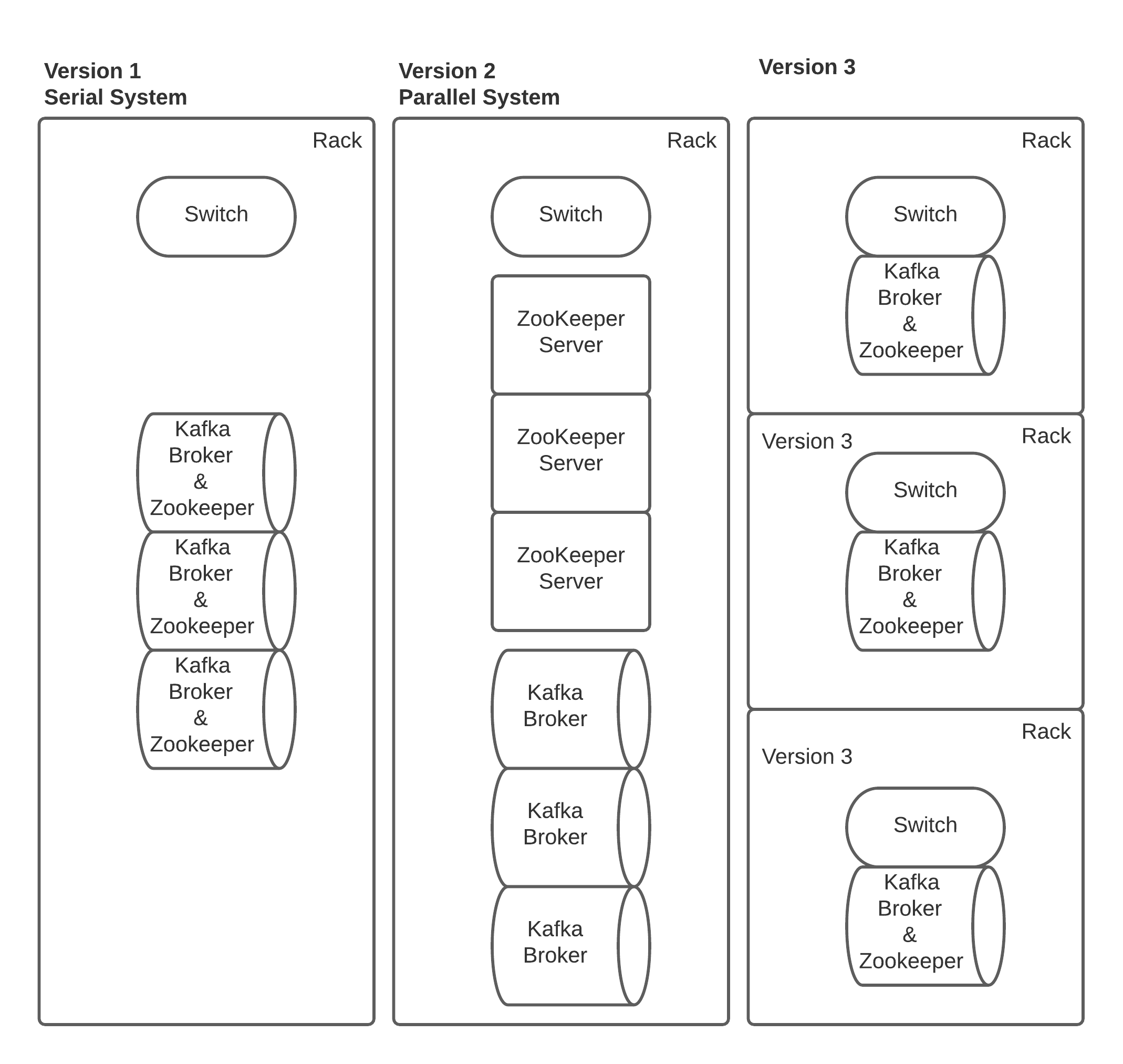
In Version 1, I consider this the most Serial deployment possible when deploying a 3 node Kafka cluster. The primary reasons for this are: Located in a single rack, Kafka and Zookeeper are co-deployed, there could be other reasons as well related to the top of rack switch if it’s redundant or not and if the network core is redundant or not. The Kafka cluster itself is still argubally a parallel system. These factors really start to touch on what part of the system you are looking at as discussed in section Serial and Parallel Systems Reliability above, that the hardware may be serial but the software on top could be parallel.
While there is nothing specifically wrong with this deployment, if attempting to maximize the parallel system for reliability and minimize serial effects one should be aiming to reduce any single serial failure paths. The colocated Zookeeper and Kafka brokers add an additional complexity in that a single server failure will have a larger impact then if a single server failed like in Version 2 were Zookeeper and Kafka Broker are separate. This is because Zookeeper and Kafka are both independent parallel systems but now both potentially linked to the same serial failure event at the hardware level.
If you do decide to colocate both Zookeeper and Kafka together on the same server ensure that Zookeeper log directory is utilizing dedicated disks which are not shared with any other applications such as Kafka log directory. This is because Zookeeper operates by committing every transaction to disk before it is available in the Zookeeper Quorum. If the disk is being shared with another application like Kafka that is also using the disk it is possible to create large delays in transactions being committed that can slow down processes that require the updated data from the Zookeeper Quorum. Another potential pitfall of not having dedicated disks for Kafka and Zookeeper is if the Kafka topic is not configured to have a bytes retention policy and only retains based on time should the disk fill up due to uncontrolled producer writes Zookeeper will no longer be able to commit ceasing to function due to lack of available storage.
Personally I have run version 3 in production for a number of years with acceptable results. In this deployment the serial rack failure is mitigated by spreading out the brokers and Zookeepers servers across multiple racks. This can help reduce the impact if you’re not using a redundant network switch for your top of rack switch. For the time that this configuration was run we did have Zookeeper colocated with our Kafka Brokers but as noted above utilized dedicated disks and never saw any issues related to Zookeeper disk contention. If you have the hardware available you should still separate your Zookeeper and Kafka brokers to continue improving the reliability of the system to failures by reducing the serial dependencies on a single server.
VM Based Kafka Clusters
Another deployment pattern some clients use is to deploy the Kafka Cluster over Virtual Machines (VMs.) This can create some additional complexities not only at the hardware level but at the software level too. It goes without saying that multiple VMs could be placed into the same physical rack much like in the prior section Kafka Clusters with and without Co-Located Zookeeper so we won’t drill into these as they have been discussed already, rather the issues that are important to address here are: multiple brokers per physical VM Host, and partition replica placement.
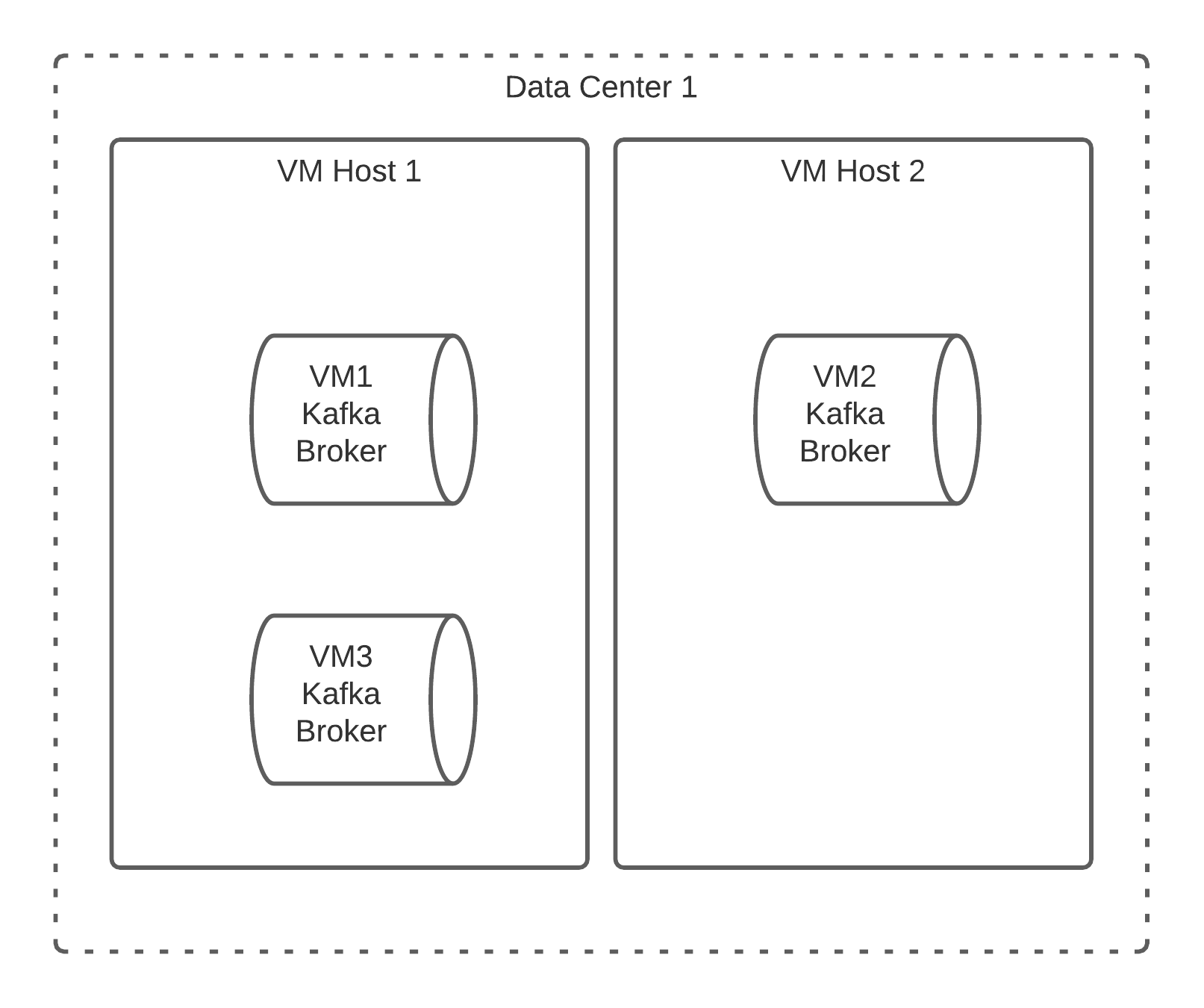
The above diagram provides an example of how a 3 node cluster could be deployed on 2 VM Hosts. In this case VM Host 1 has multiple Kafka Brokers located on it: VM1 and VM3. While this may not cause any specific issues it does present a serial reliability dependency on the VM Host 1, if it’s lost or experiences a performance degeneration for any reason all related VMs can also experience this issue. This can create a much more complex debugging scenario where it can take additional time to debug if it’s the software or the virtualization solution and its underlying hardware that is creating the trouble. Personally I have seen teams spend hours trying to debug their Kafka Cluster believing something was wrong with the software when it turned out it was the underlying VM Host that was experiencing the issue, after many hours they moved the VM’s off the host and the problems resolved; later it was identified that a CPU hardware issue was ongoing with that specific VM Host.
Another issue that is presented here is related to the serial reliability of the replica placement for each topic’s partitions. Given a situation where a topic has a replica of 2 both replicas could end up being hosted on the same VM Host, in this case if the VM host is lost then the partition would become unavailable. For the most part this issue can be avoided by utilizing Rack Awareness in Kafka but requires the cluster administrator to understand which Rack each VM Broker is located in so that the appropriate mapping can be assigned to each Broker. If all the VM Hosts are located in the same physical rack then a VM Host level mapping would have to be implemented to ensure that each VM Host is treated as if it was a rack physically. Doing this would then remove the serial reliability that a replica has on the single VM Host and begin treating it as more parallel reliability from a hardware and software perspective.
In Summary
In this part of the series, we set the stage for Serial and Parallel Reliability as a concept, how there are multiple levels that can be looked at from the hardware, software, and the parallel system itself which can change how one thinks about reliability. We also looked into multiple ways that Single Clusters have been deployed historically with and without colocated Zookeeper, and within a single rack or across multiple. Finally, we shared a discussion on Virtualized clusters and the complexities that exist from dependencies on a single virtual host running many VMs and replica placement complexities. These deployments mostly touch on the hardware, software and how the parallel system operates for a single deployment. In part 2 of the series, we will look at failover between clusters and geographically deployed systems that have to replicate data between them providing a level of System or Cluster redundancy.
Editor's Choice

