

This is the third post in a series that explores the theme of enabling diverse workloads in YARN. Our introductory post to understand the context around all the new features for diverse workloads as part of YARN in HDP 2.2, and a related post on CPU scheduling.
Introduction
One of the core responsibilities of YARN is monitoring and limiting resource usage of application containers. When it comes to resource management there are two parts:
- Resource allocation: Application containers should be allocated on nodes that have the required resources and
- Enforcement and isolation of Resource usage: Containers should only be allowed to use the resources they get allocated on a NodeManager (NM). They should also not be affected by other containers on the node.
Before HDP 2.2, memory has been the only supported resource for applications on YARN for a long time. This means that applications can request for a certain amount of memory resources, the ResourceManager (RM) then finds nodes with memory enough to satisfy resource-requests and schedules containers on those nodes. The NM then brings up the containers on the node, monitors the memory usage and if the memory usage of any container exceeds its allocation, it kills that container. This ensures that containers are always strictly limited to the memory requested.
With HDP 2.2, as we discussed before in a previous post on CPU scheduling, YARN now also supports another type of resource – CPU, represented as vcores. The allocation behavior with respect to CPU is the similar to memory – nodes inform the RM how many vcores they have and the scheduler uses that number to schedule application containers. When it comes to resource isolation and enforcement, the story extends itself a bit – how do we ensure that containers don’t exceed their vcore allocation? What’s stopping an errant container from spawning a bunch of threads and consume all the CPU on the node?
Enter CGroups
CGroups is a mechanism for aggregating/partitioning sets of processes (tasks in Linux’s nomenclature), and all their children, into hierarchical groups with specialized behaviour. CGroups is a Linux kernel feature and was merged into kernel version 2.6.24. CGroups allows control of various system resources such as memory, CPU, blockio, etc. In addition, CGroups also take care of ensuring that the resource usage of child processes are limited as per the limit set for their parent. From YARN’s perspective, this allows the NM to limit the CPU usage of containers and fits in perfectly with the current YARN’s model of resource isolation and enforcement.
The end-to-end control-flow works as follows:
- When an NM starts, it reports the number of vcores to the RM. We recommend that this be set to the number of physical cores on your node. The reason vcores was added was to enable administrators to have fine-grained control on resource utilization on clusters with heterogeneous hardware. Nodes with faster processors can be configured with higher cores allowing for more containers to be launched.
- When an application is submitted, it asks for a number of vcores needed for launching the ApplicationMaster as part of the submission. The AM itself can specify the vcores desired when it requests for containers.
- The RM in turn finds nodes with the appropriate vcores available and schedules the containers on those nodes.
- When the container is launched, the number of vcores requested is translated to a percentage of the overall CPU (divide the number of vcores for the container by the total number of vcores on the node).
- CGroups is setup to ensure that the container launched is limited to the percentage of CPU that it was allocated.
How to use Cgroups based isolation in YARN
To enable CGroups in YARN, you must be running Linux kernel version greater than 2.6.24. You must also setup the NM to use the LinuxContainerExecutor which in turn means that you should have the native container-executor binary as part of your install. This binary is used by the LinuxContainerExecutor to launch containers with the appropriate restrictions.
There are some configuration variables that you should be aware of when setting up CGroups. Some of these properties are for setting up the LinuxContainerExecutor while the rest are specifically directed towards setting up CGroups:
- nodemanager.container-executor.classThis should be set to org.apache.hadoop.yarn.server.nodemanager.LinuxContainerExecutor. CGroups is a Linux kernel feature that is today in HDP 2.2 only exposed via the LinuxContainerExecutor.
- nodemanager.linux-container-executor.groupThe Unix group of the NodeManager. It should match the setting in “container-executor.cfg”. This configuration is required for validating the secure access of the container-executor binary.
- nodemanager.linux-container-executor.resources-handler.classThis should be set to org.apache.hadoop.yarn.server.nodemanager.util.CgroupsLCEResourcesHandler. Using the LinuxContainerExecutor is necessary but not sufficient for using CGroups. If you wish to use CGroups, the resource-handler-class must be set to CGroupsLCEResourcesHandler.
- nodemanager.linux-container-executor.cgroups.mountWhether the LinuxContainerExecutor should attempt to mount cgroups if not found, from a mount-path described below – can be true or false
- nodemanager.linux-container-executor.cgroups.mount-pathWhere the LinuxContainerExecutor should attempt to mount cgroups if not found. Common locations include /sys/fs/cgroup and /cgroup; the default location can vary depending on the Linux distribution in use. This path must exist before the NodeManager is launched. This is only used when the LCE resources handler is set to the CgroupsLCEResourcesHandler, and yarn.nodemanager.linux-container-executor.cgroups.mount is true. A point to note here is that the container-executor binary will try to mount the path specified + “/” + the subsystem. In our cause, since we are trying to limit CPU the binary tries to mount the path specified + “/cpu” and that’s the path it expects to exist.
- nodemanager.linux-container-executor.cgroups.hierarchyThe cgroups hierarchy under which NodeManager can place YARN processes (cannot contain commas). If yarn.nodemanager.linux-container-executor.cgroups.mount is false (that is, if cgroups have been pre-configured), then this cgroups hierarchy must already exist and be writable by the NodeManager user, otherwise the NodeManager will fail to start.
Aggregate limits on containers
Some organizations may wish to run non-YARN processes on the same node as the NM. These may be monitoring agents, HBase servers, etc. How do you share CPU between the containers launched by the NM and these external tasks? You may not want your YARN containers using all the CPU on any given physical machine. For this purpose we’ve added a new configuration property: yarn.nodemanager.resource.percentage-physical-cpu-limit. This variable lets you set the maximum amount of CPU to be used by all the YARN containers put together. This limit is a hard limit and can be used to ensure that YARN containers can run on your nodes without consuming all CPU, and thus leaving enough capacity for non-YARN process.
Soft vs hard limits
By default, the CGroups-based container resource restrictions are only soft limits – if there is spare CPU available on a given node, the containers are allowed to use it (potentially far exceeding their allocation). However if an additional application container is launched that needs CPU, existing containers’ CPU usage is scaled back appropriately. This may lead to situations where applications which are CPU bound finish faster when the cluster is either idle or lightly loaded but take longer when the cluster has more load. This behaviour contrasts with memory isolation in YARN – if users don’t size their containers correctly, their containers will be killed potentially failing the applications too. On the other hand, once the containers are sized correctly, applications will run in a predictable manner.
The above behavior can be turned on/off by a config setting – administrators can set yarn.nodemanager.linux-container-executor.cgroups.strict-resource-usage to true if they wish to restrict all containers to their specific resource allocation. This sets a hard limit on the container’s CPU usage, adding some predictability in application performance. This setting is also useful when benchmarking your workload to avoid cluster load adding noise to your measurements.
Example usage
If you are looking for applications that can benefit from using CGroups, Storm on YARN is a really good example of an application that can gain by enabling CGroups. In addition, the DistributedShell application and the MapReduce framework also have support for specifying vcores and both benefit by using CGroups.
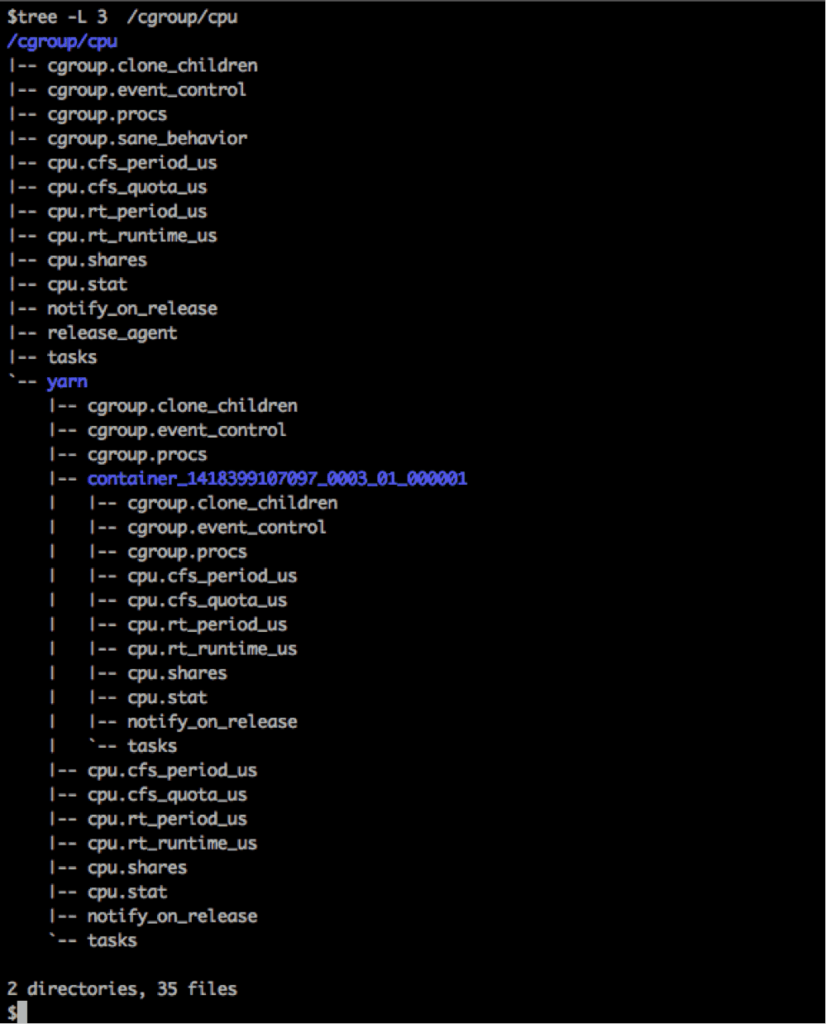
Below are a couple of screenshots that show how a CGroups hierarchy looks like when used by YARN.
The following gives the list of all the individual settings in the cgroups.
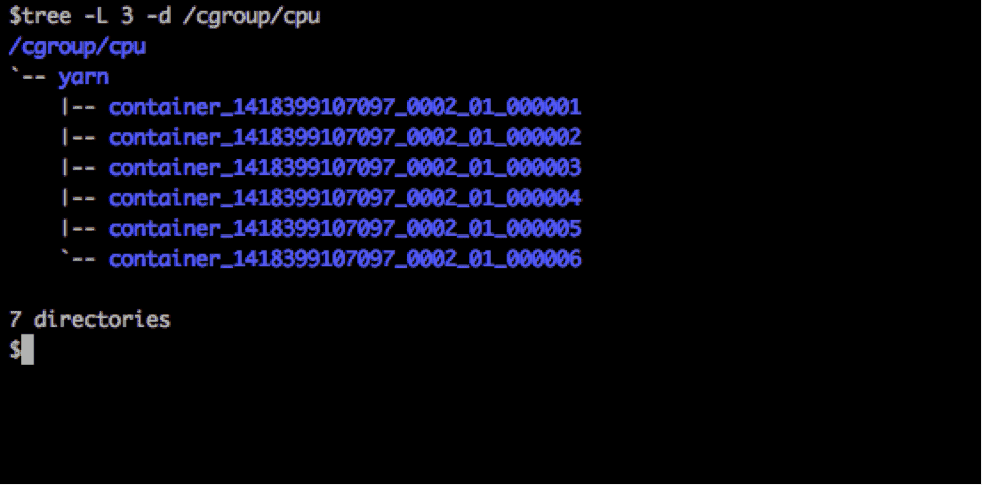
When running an application, YARN creates a Cgroup for each container naming it after its ContainerID. For e.g, the following is a situation where YARN is running 6 containers of one application in parallel on a node.
Conclusion
In this and the previous companion posts, we’ve covered various features that help enabling diverse workloads on YARN. Specifically, we discussed about scheduling & isolating workloads that require CPU as resource, impact of adding CPU as resource on applications. We hope you found these posts useful!
Editor's Choice

