

This blog post was published on Hortonworks.com before the merger with Cloudera. Some links, resources, or references may no longer be accurate.
This is the 3rd blog of the Hadoop Blog series (part 1, part 2, part 4, part 5). In this blog, we provide a high-level overview on the release of Apache Hadoop 3.1.
The Apache Hadoop community just announced the release of Apache Hadoop 3.1.0! This is the next big milestone in the Apache Hadoop 3.x line, the first one being the 3.0.0 release back in December 2017. It’s a significant release for many readers of this blog who are on the Apache Hadoop 2.x series.
Important notes from the announcement:
This release is *not* yet ready for production use. Critical issues are being ironed out via testing and downstream adoption. Production users should wait for a 3.1.1/3.1.2 release.
The Hadoop community fixed 768 JIRAs (https://s.apache.org/apache-hadoop-3.1.0-all-tickets) in total as part of the 3.1.0 release. Of these fixes:
– 141 in Hadoop Common
– 266 in HDFS
– 329 in YARN
– 32 in MapReduce
Apache Hadoop 3.1.0 contains a number of significant features and enhancements.
A few of them are noted below.
Hadoop Common
– HADOOP-14831 / HADOOP-14531 / HADOOP-14825 / HADOOP-14325. S3/S3A/S3Guard related improvements.
Hadoop HDFS
– HDFS-9806 – HDFS block replicas to be provided by an external storage system
Hadoop YARN
– YARN-6223. First class GPU support on YARN
– YARN-5983. First class FPGA support on YARN
– YARN-5079 / YARN-4793 / YARN-4757 / YARN-6419. YARN native service support
– YARN-6592. Rich placement constraints in YARN
– YARN-5881. Enable configuration of queue capacity in terms of absolute resources for Capacity Scheduler.
– YARN-7117. Capacity Scheduler: Support auto-creation of leaf queues while doing queue mapping
A quick look back
We wanted to use this opportunity to also look back a bit and analyze how the Hadoop code-base changed over time and across recent releases. The following charts show some of the statistics.
Note that in some cases, we picked 2.8.3 as the base-line 2.x release since that is likely the closest 2.x release that enjoys the most installation footprint around the world.

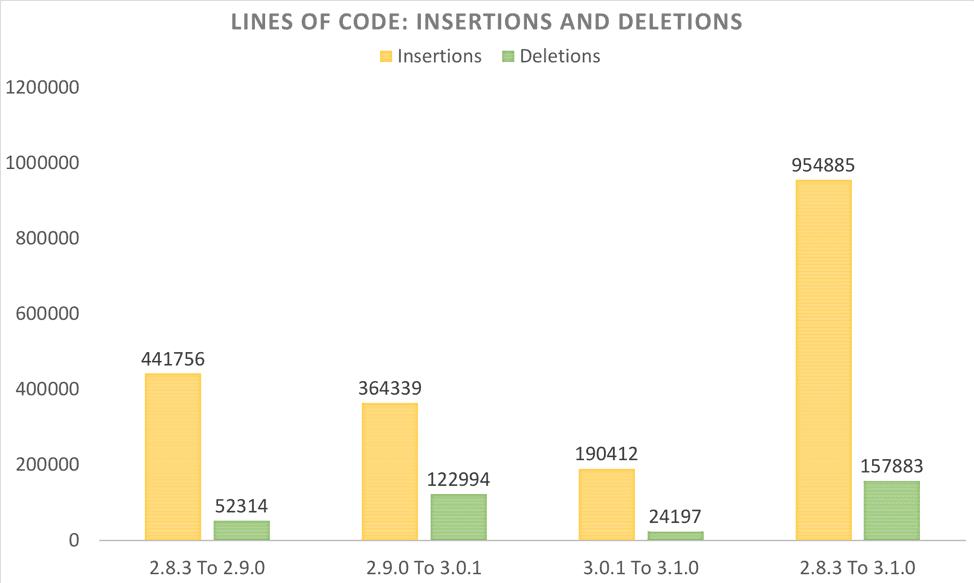
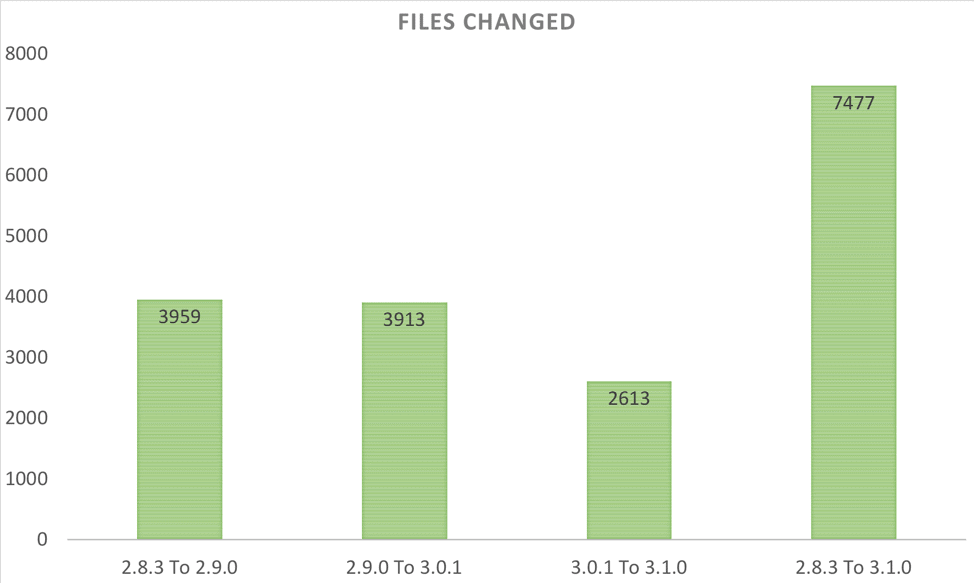
Distributions of number of resolved JIRAs (since 3.0.0) by contributors
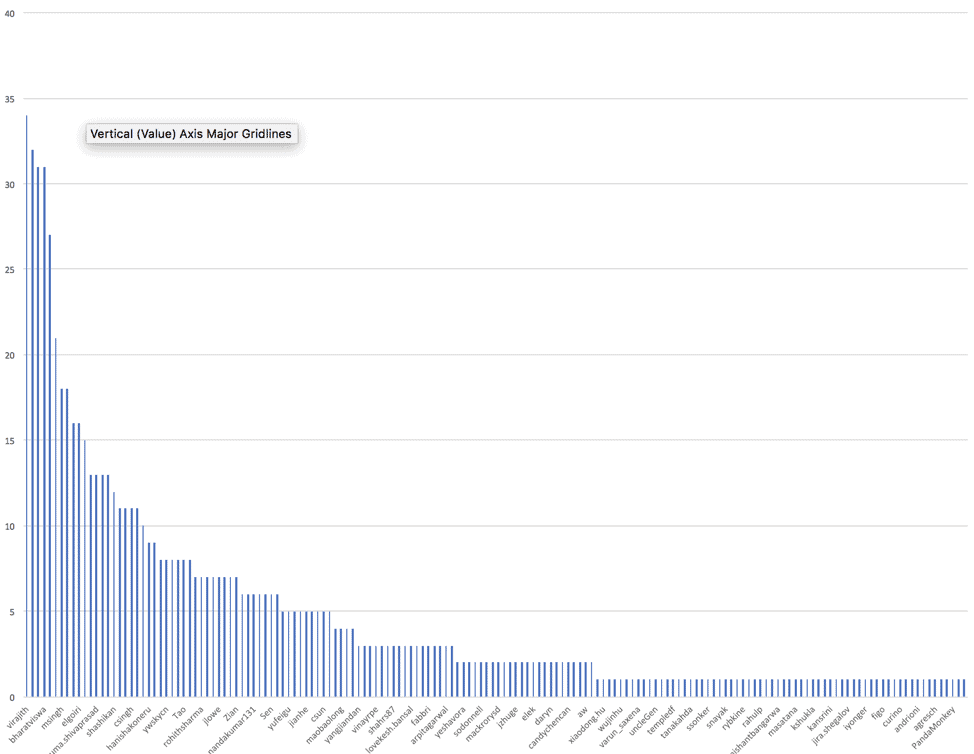
As with previous releases, we see a very large number of contributors all coming together to make this release happen, and a clearly long tail. A great community story!
We want to express our gratitude to every contributor, every reviewer and committer who participated in this release! And congratulations, Apache Hadoop community!
Learn more about Hadoop 3:
- First-Class Support for Long Running Services on Apache Hadoop YARN
- How Apache Hadoop 3 Adds Value Over Apache Hadoop 2
- Apache Hadoop 3.1 – A Giant Leap for Big Data
- Trying out Containerized Applications on Apache Hadoop YARN 3.1
[1] Patches from 2.8.3 to 3.1.0: project in (“Hadoop Common”) AND fixVersion in (3.1.0, 2.9.0, 3.0.0, 3.0.0-beta1, 3.0.1, 3.0.0-alpha, 3.0.0-alpha1, 3.0.0-alpha2, 3.0.0-alpha3, 3.0.0-alpha4) AND fixVersion not in (2.8.3, 2.8.2, 2.8.1, 2.7.2, 2.6.1, 2.7.1, 2.6.0, 2.7.0, 2.8.0) AND resolution in (Fixed, Done) ORDER BY fixVersion ASC
Editor's Choice

