

Cloudera Data Platform (CDP) brings many improvements to customers by merging technologies from the two legacy platforms, Cloudera Enterprise Data Hub (CDH) and Hortonworks Data Platform (HDP). CDP includes new functionalities as well as superior alternatives to some previously existing functionalities in security and governance. One such major change for CDH users is the replacement of Sentry with Ranger for authorization and access control.
For big data platforms like Cloudera’s stack that are used by multiple business units with many users, upgrading even minor versions must be a well-planned activity to reduce the impact to users and business. So, upgrading to a new major version in CDP can create hesitation and apprehension. Having access to the right set of information helps users in preparing ahead of time and removing any hurdles in the upgrade process. This blog post provides CDH users with a quick overview of Ranger as a Sentry replacement for Hadoop SQL policies in CDP.
Why switch to Ranger?
Apache Sentry is a role-based authorization module for specific components in Hadoop. It is useful in defining and enforcing different levels of privileges on data for users on a Hadoop cluster. In CDH, Apache Sentry provided a stand-alone authorization module for Hadoop SQL components like Apache Hive and Apache Impala as well as other services like Apache Solr, Apache Kafka, and HDFS (limited to Hive table data). Sentry depended on Hue for visual policy management, and Cloudera Navigator for auditing data access in the CDH platform.
On the other hand, Apache Ranger provides a comprehensive security framework to enable, manage and monitor data security across the Hadoop platform. It provides a centralized platform to define, administer and manage security policies consistently across all Hadoop components that Sentry protected, as well as additional services in the Apache Hadoop ecosystem like Apache HBase, YARN, Apache NiFi. Furthermore, Apache Ranger now supports Public Cloud objects stores like Amazon S3 and Azure Data Lake Store (ADLS). Ranger also provides security administrators with deep visibility into their environment through a centralized audit location that tracks all the access requests in real time.
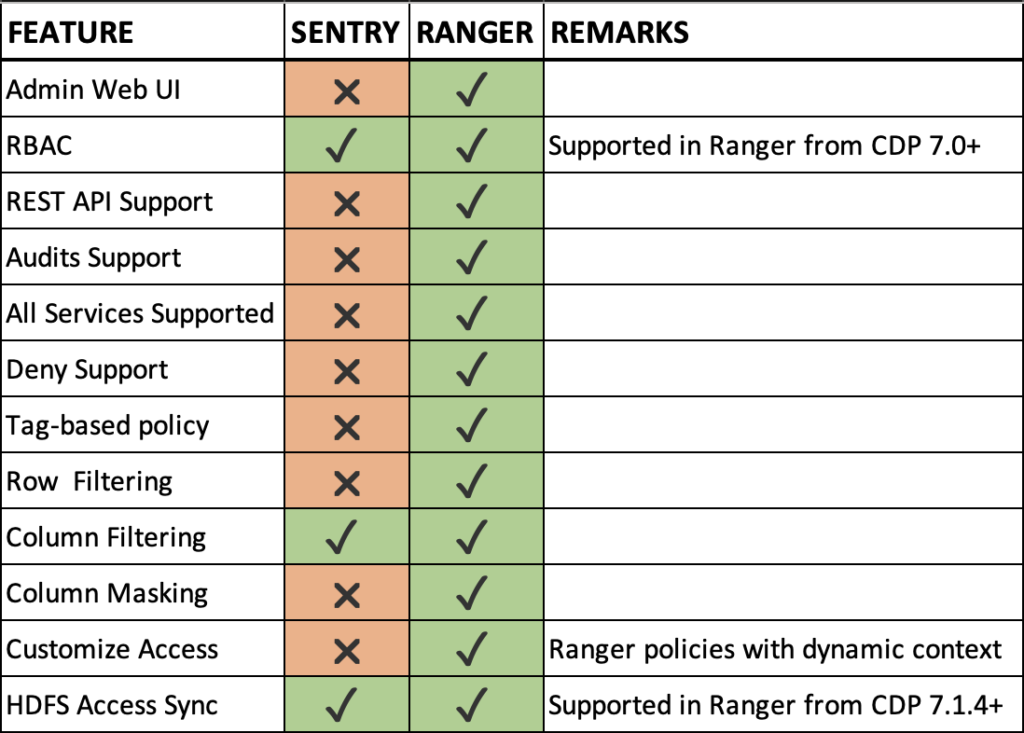
Apache Ranger has its own Web User Interface (Web UI) which is a superior alternative to the Sentry’s Web Interface provided through the Hue Service. The Ranger Web UI can also be used for security key management, with a separate login for Key administrators using the Ranger KMS service. Apache Ranger also provides much needed security features like column masking and row filtering out of the box. Another important factor is that the access policies in Ranger can be customized with dynamic context using different attributes like geographic region, time of the day, etc. The table below gives a detailed comparison of the features between Sentry and Ranger.
Sentry to Ranger – A few behavioral changes
As suggested above, Sentry and Ranger are completely different products and have major differences in their architecture and implementations. Some of the notable behavioral changes when you migrate to Ranger in CDP from Sentry in CDH are listed below.
- Inherited model in Sentry Vs Explicit model in Ranger
- In Sentry, any privilege granted on a container object in the hierarchy is automatically inherited by the base object within that. For example, if a user has ALL privileges on the database scope, then that user has ALL privileges on all the base objects contained within that scope, like tables and columns. So, one grant given to a user on a database would give access to all the objects within the database.
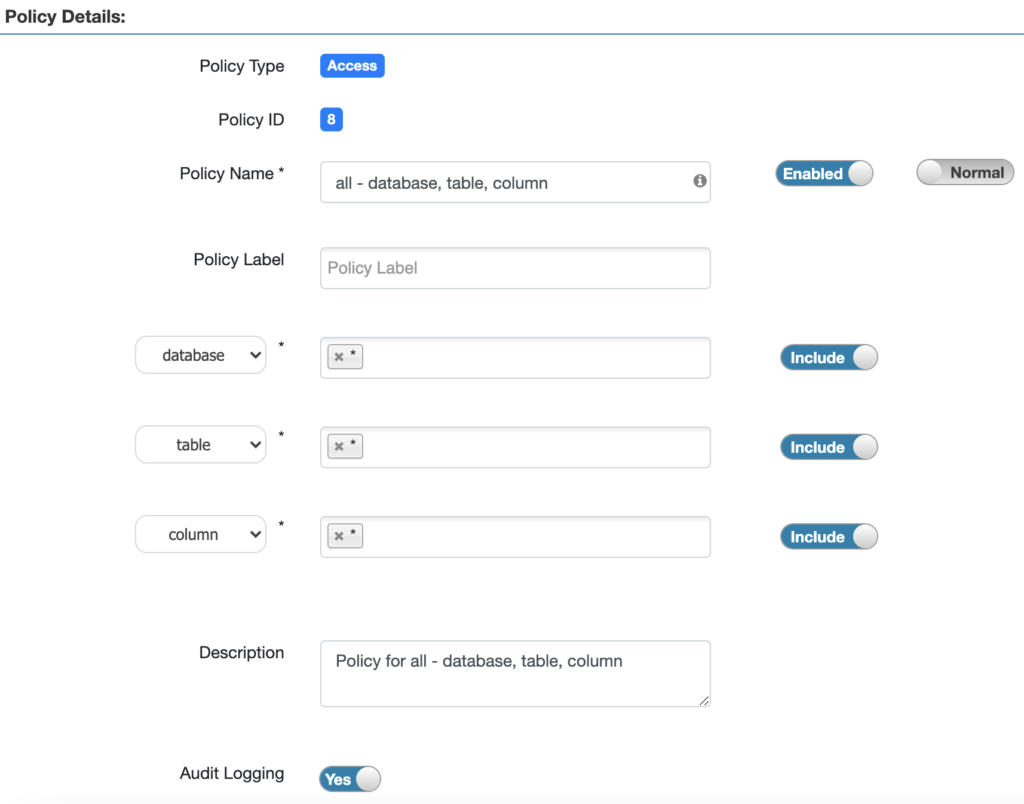
- In Ranger, explicit Hadoop SQL policies with necessary permissions should exist for a user to get access to an object. This means, Ranger provides a finer grained level of access control. Having access at a database level would not grant the same access at the table level. And having access at a table level would not grant the same access at the column level. For example, with Ranger Hadoop SQL policies, to grant access on all tables and columns to a user, create a policy with wildcards like – database → <database-name>, table → * and column → *.
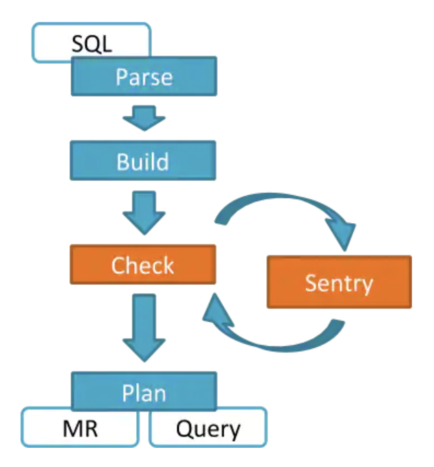
- Access Control implementation – Sentry Vs Ranger
- Sentry Authorization processing for Hive happens via a semantic hook that is executed by HiveServer2. Access requests go back to Sentry Server each time for validation. Access control checks in Impala are like that in Hive. The main difference in Impala is the caching of Sentry metadata (privileges) by Impala Catalog server.
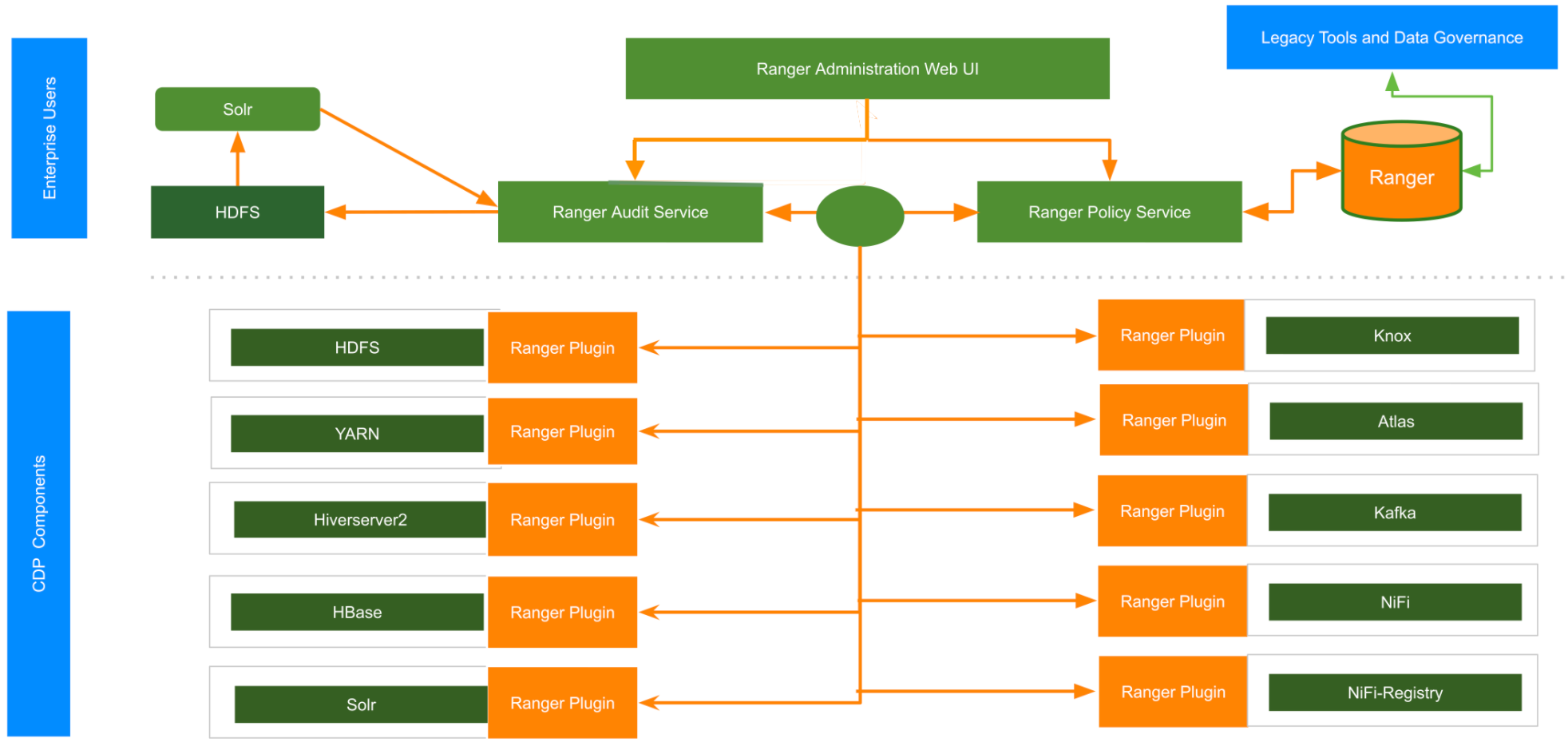
-
- All services within CDP Private Cloud Base that support Ranger-based authorization, have an associated Ranger plugin. These Ranger plugins cache the access privileges and tags at client side. They also periodically poll the privilege and tag store for any changes. When a change is detected, the cache is automatically updated. Such an implementation model enables the Ranger plugin to process authorization requests completely within the service daemons, resulting in considerable performance improvements, and resilience in the face of failures outside the service.
- HDFS Access Sync implementation – Sentry Vs Ranger
- Sentry has an option to automatically convert the SQL privileges to provide access to HDFS. This is implemented through an HDFS-Sentry plugin that allows you to configure synchronization of Sentry privileges with HDFS ACLs for specific HDFS directories. With synchronization enabled, Sentry will translate permissions on databases and tables to the appropriate corresponding HDFS ACL on the underlying files in HDFS. And these added access permissions on HDFS files can be viewed by listing the extended ACLs using HDFS commands.
- Since CDP Private Cloud Base 7.1.5, a feature Ranger Resource Mapping Server (RMS), is introduced which serves the same purpose. Please note that RMS is available in CDP Private Cloud Base 7.1.4 as a tech preview. The implementation of HDFS ACL Sync in Sentry is different from how Ranger RMS handles automatic translations of access policies from Hive to HDFS. But the underlying concept and authorization decisions are the same for table-level access. Please read this blog post on Ranger RMS to learn more about this new feature.
- Access Permissions for HDFS Location in SQL – Sentry Vs Ranger
- In Sentry, URI permissions on a location were required for the following actions
- Explicitly set the location of a table – create external table
- Alter the location of a table – alter table
- Import and export from a table with the location
- Create a function from a jar file
- In Ranger, “URL” policies in Hadoop SQL or HDFS policies on the location used by the Hive object can be used to the same effect for such activities that use location. For creating functions, proper permissions in “udf” policies in Hadoop SQL are required.
- In Sentry, URI permissions on a location were required for the following actions
- Special Entities in Ranger
- Group “public” – This is a special internal group within Ranger that consists of any authenticated user that exists on the system. Membership is implicit and automatic. It should be noted that all users would be part of this group and any policies granted to this group provide access to everyone. The following are the default policies that give permissions to this special group “public”. Based on the security requirements, “public” can be removed from these default policies to further restrict user access.
- all – database ⇒ public ⇒ create permission
- Allows users to self-service create their own databases
- default database tables columns ⇒ public ⇒ create permission
- Allows users to self-service create tables in the default database
- Information_schema database tables columns ⇒ public ⇒ select permission
- Allows users to query for information about tables, views, columns, and your Hive privileges
- all – database ⇒ public ⇒ create permission
- Special Object {OWNER} – This should be considered as a special entity within Ranger which would get attached to a user based on their actions. Using this special object can significantly simplify policy structure. For example, if a user “bob” creates a table, then “bob” becomes the {OWNER} of that table and would get any permissions provided to {OWNER} on that table across all the policies. The following are the default policies that would have permissions for {OWNER}. Though it is not recommended, based on the security requirements, access to this special entity can be altered. Removing the default {OWNER} permissions may require adding additional, specific policies for each object owner, which can increase the operational burden of policy management.
- all – database, table, column ⇒ {OWNER} ⇒ all permissions
- all – database, table ⇒ {OWNER} ⇒ all permissions
- all – database, udf ⇒ {OWNER} ⇒ all permissions
- all – database ⇒ {OWNER} ⇒ all permissions
- Special Object {USER} – This should be considered as a special entity within Ranger which means “current user”. Using this special object can significantly simplify policy structure where data resources contain the user-name attribute value. For example, giving access to {USER} on HDFS path /home/{USER} will give the user “bob” access to “/home/bob”, and user “kiran” access to “/home/kiran”. Similarly, granting access to {USER} on the database, db_{USER}, will provide the user “bob” access to “db_bob”, and user “kiran” access to “db_kiran”.
- Group “public” – This is a special internal group within Ranger that consists of any authenticated user that exists on the system. Membership is implicit and automatic. It should be noted that all users would be part of this group and any policies granted to this group provide access to everyone. The following are the default policies that give permissions to this special group “public”. Based on the security requirements, “public” can be removed from these default policies to further restrict user access.
How does this change affect my environment?
- Migration to Ranger
- Cloudera provides an automated tool, authzmigrator, to migrate from Sentry to Ranger
- The tool converts the Hive objects’ permissions and URL permissions (i.e., URI in Sentry) as well as Kafka permissions in Sentry in CDH clusters
- Currently the tool does not cover authorization permissions enabled through Sentry for Cloudera Search (Solr)
- The tool has a well-defined two-step process – (1) Export permissions from Sentry in Source (2) Ingest the exported file into Ranger service in CDP
- The tool works in both a direct upgrade and side-car migration approach from CDH to CDP
- In case of direct upgrade, the whole process is automated
- In case of side-car migration, a manual procedure is defined for the authzmigrator tool
- Object Permissions in Ranger
- “Insert” permission in Sentry now maps to “Update” permission in Ranger Hadoop SQL policies
- “URI” permission in Sentry now maps to “URL” policy in Ranger Hadoop SQL
- Additional granular permissions are present in Ranger Hadoop SQL
- Drop, Alter, Index, Lock etc.
- Hive-HDFS Access Sync with Ranger
- A new service, Ranger RMS need to be deployed
- Ranger RMS connects to the same database used by Ranger
- Ranger RMS currently works only table-level sync and not at database level (coming soon)
- External Table Creation with Ranger in Hive
- When creating External Tables with custom LOCATION clause in Hive, one of the following additional accesses is required (1) or (2)
- (1) Users should have direct read and write access to the HDFS location
- This can be provided through HDFS Policy in Ranger or HDFS POSIX permissions or HDFS ACL
- (2) A URL policy in Ranger Hadoop SQL policies that provide users with read and write permissions on the HDFS location defined for the table
- URL should not have a trailing slash character (“/”)
- If the location path is not owned by the user then make sure that the configuration “ranger.plugin.hive.urlauth.filesystem.schemes” is set to “file:” and not “hdfs:,file:” (which is the default) in both Hive and Hive on Tez services
- (1) Users should have direct read and write access to the HDFS location
- The user “hive” should have all the privileges on the HDFS location of the table
- When creating External Tables with custom LOCATION clause in Hive, one of the following additional accesses is required (1) or (2)
Summary
Apache Ranger enables authorization as a part of Shared Data Experience (SDX), which is the fundamental part of Cloudera Data Platform architecture and is critical for data management and data governance. In CDP, Ranger provides all the capabilities that Apache Sentry provided in the CDH stack. Ranger is a comprehensive solution that can enable, manage, and monitor data security across the entire CDP ecosystem. It also offers additional security capabilities like data filtering and masking. By bringing authorization and auditing together, Ranger enhances the data security strategy of CDP as well as provides a superior user experience. Apart from these authorization and audit enhancements, Ranger Web UI can also be used for security key management with a separate login for Key administrators using the Ranger KMS service.
To learn more about Ranger and related features, here are some helpful resources:
Editor's Choice

