



What is Cloudera Data Engineering (CDE) ?
Cloudera Data Engineering is a serverless service for Cloudera Data Platform (CDP) that allows you to submit jobs to auto-scaling virtual clusters. CDE enables you to spend more time on your applications, and less time on infrastructure.
CDE allows you to create, manage, and schedule Apache Spark jobs without the overhead of creating and maintaining Spark clusters. In addition to this, you can define virtual clusters with a range of CPU and memory resources, and the cluster scales up and down as needed to execute your Spark workloads, helping control your cloud costs.
Managed, serverless Spark service helps our customers in a number of ways:
- Auto scaling of compute to eliminate static infrastructure costs. This feature ensures that customers do not have to maintain a large infrastructure footprint and hence reduce total cost of ownership.
- Ability for business users to easily control their own compute needs with a click of a button, without IT intervention.
- Complete view of the job performance, logging and debugging through a single pane of glass to enable efficient development on Spark.
Refer to the following Cloudera blog to understand the full potential of Cloudera Data Engineering.
Why should technology partners care about CDE?
Unlike traditional data engineering workflows that have relied on a patchwork of tools for preparing, operationalizing, and debugging data pipelines, Cloudera Data Engineering is designed for efficiency and speed — seamlessly integrating and securing data pipelines to any CDP service including Machine Learning, Data Warehouse, Operational Database, or any other analytic tool in your business. Partner tools that leverage CDP as their backend store can leverage this new service to ensure their customers can take advantage of a serverless architecture for Spark.
ISV Partners, like Precisely, support Cloudera’s hybrid vision. Precisely Data Integration, Change Data Capture and Data Quality tools support CDP Public Cloud as well as CDP Private Cloud. Precisely end-customers can now design a pipeline once and deploy it anywhere. Data pipelines that are bursty in nature can leverage the public cloud CDE service while longer running persistent loads can run on-prem. This ensures that the right data pipelines are running on the most cost-effective engines available in the market today.

Using the CDE Integration API:
CDE provides a robust API for integration with your existing continuous integration/continuous delivery platforms.
The Cloudera Data Engineering service API is documented in Swagger. You can view the API documentation and try out individual API calls by accessing the API DOC link in any virtual cluster:
- In the CDE web console, select an environment.
- Click the Cluster Details icon in any of the listed virtual clusters.
- Click the link under API DOC.
For further details on the API, please refer to the following doc link here.
Custom base Image for Kubernetes:
Partners who need to run their own business logic and require custom binaries or packages available on the Spark engine platform, can now leverage this feature for Cloudera Data Engineering. We believe customized engine images would allow greater flexibility to our partners to build cloud-native integrations and could potentially be leveraged by our enterprise customers as well. The following set of steps will describe the ability to run Spark jobs with dependencies on external libraries and packages. The libraries and packages will be installed on top of the base image to make them available to the Spark executors.
First, obtain the latest CDE CLI
a) Create a virtual cluster
b) Go to virtual cluster details page
c) Download the CLI
Learn more on how to use the CLI here
Run Spark jobs on customized container image – Overview
Custom images are based on the base dex-spark-runtime image, which is accessible from the Cloudera docker repository. Users can then layer their packages and custom libraries on top of the base image. The final image is uploaded to a docker repo, which is then registered with CDE as a job resource. New jobs are defined with references to the resource which automatically downloads the custom runtime image to run the Spark drivers and executors.
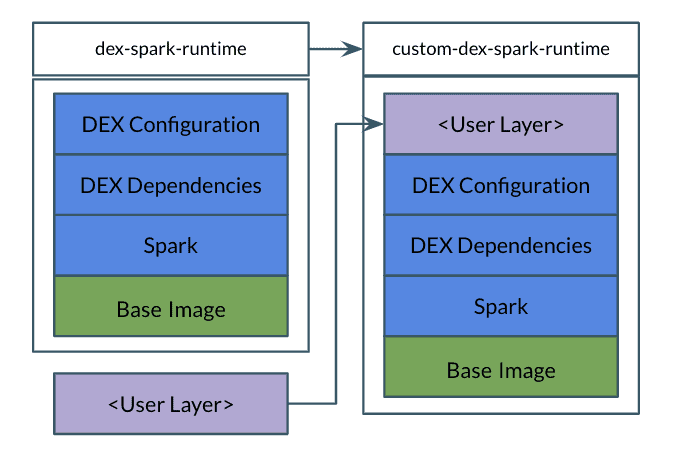
Run Spark jobs on customized container image: Steps
1. Pull “dex-spark-runtime” image from “docker.repository.cloudera.com”
$ docker pull container.repository.cloudera.com/cloudera/dex/dex-spark-runtime:<version>
Note: “docker.repository.cloudera.com” is behind the paywall and will require credentials to access, please ask your account team to provide
2. Create your “custom-dex-spark-runtime” image, based on “dex-spark-runtime” image
$ docker build --network=host -t <company-registry>/custom-dex-spark-runtime:<version> . -f Dockerfile
Dockerfile Example:
FROM docker.repository.cloudera.com/<company-name>/dex-spark-runtime:<version> USER root RUN yum install ${YUM_OPTIONS} <package-to-install> && yum clean all && rm -rf /var/cache/yum RUN dnf install ${DNF_OPTIONS} <package-to-install> && dnf clean all && rm -rf /var/cache/dnf USER ${DEX_UID}
3. Push image to your company Docker registry
$ docker push <company-registry>/custom-dex-spark-runtime:<version>
4. Create ImagePullSecret in DE cluster for the company’s Docker registry (Optional)
REST API:
# POST /api/v1/credentials { "name": "<company-registry-basic-credentials>", "type": "docker", "uri": "<company-registry>", "secret": { "username": "foo", "password": "bar", } } CDE CLI: === credential === ./cde credential create --type=docker-basic --name=docker-sandbox-cred --docker-server=https://docker-sandbox.infra.cloudera.com --docker-username=foo --tls-insecure --user srv_dex_mc --vcluster-endpoint https://gbz7t69f.cde-vl4zqll4.dex-a58x.svbr-nqvp.int.cldr.work/dex/api/v1
Note: Credentials will be stored as Kubernetes “Secret”. Never stored by DEX API.
5. Register “custom-dex-spark-runtime” in DE as a “Custom Spark Runtime Image” Resource.
REST API:
# POST /api/v1/resources { "name":"", "type":"custom-spark-runtime-container-image", "engine": "spark2", "image": <company-registry>/custom-dex-spark-runtime:<version>, "imagePullSecret": <company-registry-basic-credentials> } CDE CLI: === runtime resources === ./cde resource create --type="custom-runtime-image" --image-engine="spark2" --name="custom-dex-qe-1_1" --image-credential=docker-sandbox-cred --image="docker-sandbox.infra.cloudera.com/dex-qe/custom-dex-qe:1.1" --tls-insecure --user srv_dex_mc --vcluster-endpoint https://gbz7t69f.cde-vl4zqll4.dex-a58x.svbr-nqvp.int.cldr.work/dex/api/v1
6. You should now be able to define Spark jobs referencing the custom-dex-spark-runtime
REST API:
# POST /api/v1/jobs { "name":"spark-custom-image-job", "spark":{ "imageResource": "CustomSparkImage-1", ... } ... } CDE CLI: === job create === ./cde job create --type spark --name cde-job-docker --runtime-image-resource-name custom-dex-qe-1_1 --application-file /tmp/numpy_app.py --num-executors 1 --executor-memory 1G --driver-memory 1G --tls-insecure --user srv_dex_mc --vcluster-endpoint https://gbz7t69f.cde-vl4zqll4.dex-a58x.svbr-nqvp.int.cldr.work/dex/api/v1
7. Once the job is created either trigger it to run through Web UI or by running the following command in CLI:
$> cde job run --name cde-job-docker
In conclusion
We introduced the “Custom Base Image” feature as part of our Design Partner Program to elicit feedback from our ISV partners. The response has been overwhelmingly positive and building custom integrations with our cloud-native CDE offering has never been easier.
As a partner, you can leverage Spark running on Kubernetes Infrastructure for free. You can launch a trial of CDE on CDP in minutes here, giving you a hands-on introduction to data engineering innovations in the Public Cloud.
References:
https://www.cloudera.com/tutorials/cdp-getting-started-with-cloudera-data-engineering.html
Editor's Choice

