

Two years ago we wrote a research report about Federated Learning. We’re pleased to make the report available to everyone, for free. You can read it online here: Federated Learning.
Federated Learning is a paradigm in which machine learning models are trained on decentralized data. Instead of collecting data on a single server or data lake, it remains in place—on smartphones, industrial sensing equipment, and other edge devices—and models are trained on-device. The trained models are transferred to a central server and combined. Transporting models rather than data has numerous ramifications and tradeoffs.
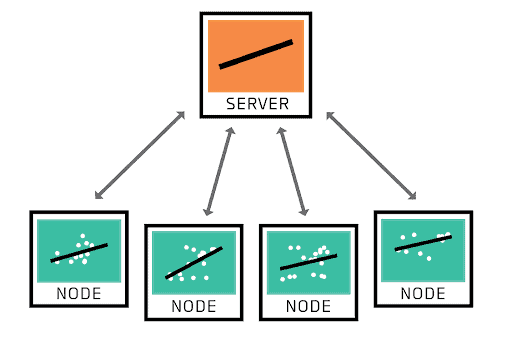
In federated learning, a network of nodes shares models rather than training data with a server.
Keeping data decentralized helps solve essentially two problems. First, it makes data privacy easier. Since the data is never transferred to a central location, the data cannot be aggregated or combined with other data. Decentralized approaches to machine learning are favoured in privacy-sensitive consumer applications, like providing autocomplete or textual image search on a smartphone. Companies like Owkin are extending the same privacy benefits to medical organizations, enabling research to cross institutional boundaries while safeguarding patient privacy and complying with data protection regulations.
The second advantage to decentralized data is data locality itself. In situations where large volumes of data are generated at the edge, such as in industrial sensing applications, it can be expensive and difficult to transfer that data to a central repository. Federated Learning allows us to capture the signal in that data, for a given predictive purpose, without the requirement to centralize it. We explored a toy application of Federated Learning to predict industrial equipment failure in our interactive prototype Turbofan Tycoon.
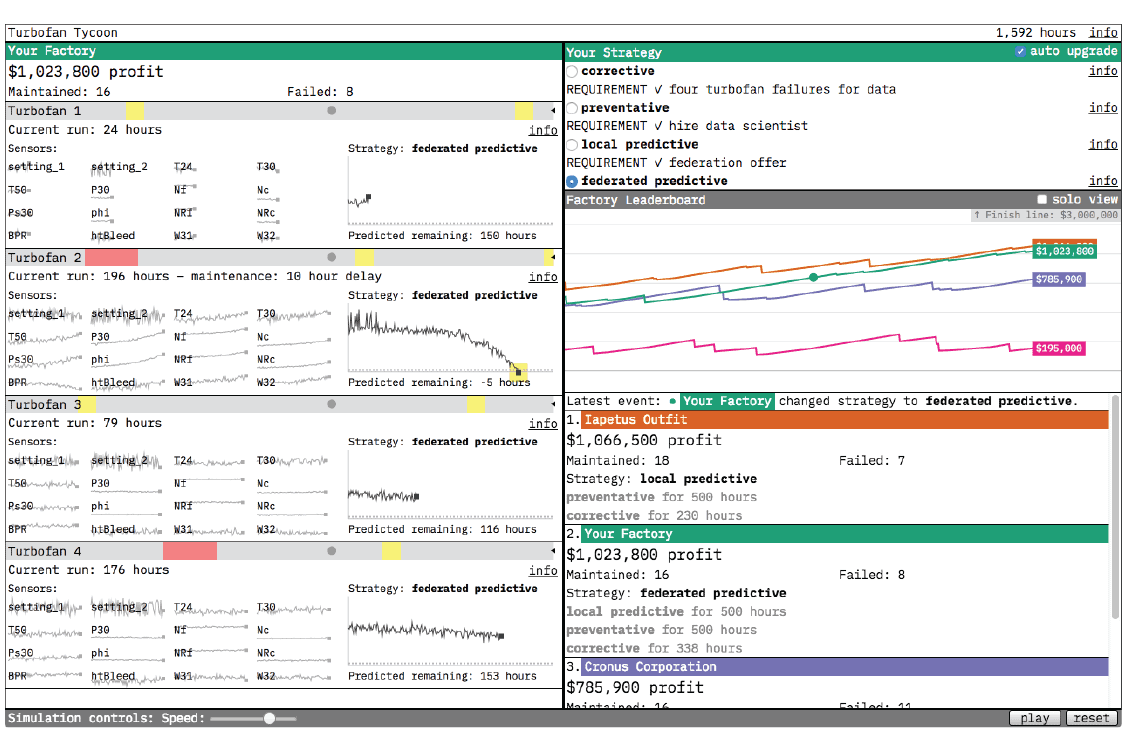
The Turbofan Tycoon prototype.
Two years ago we released a research report on Federated Learning. In the time since it has only grown in relevance. Numerous startups have cropped up (and some disappeared by acquisition) with Federated Learning as their core technology. Google continues to promoting the technology, including for non-machine learning use cases, as in Federated Analytics: Collaborative Data Science without Data Collection. This year saw (what we believe to be) the first conferences with a heavy focus on federated learning, The Federated Learning Conference and the Open Mined Privacy Conference, as well as dedicated workshops at high profile machine learning conferences like ICML and NeurIPS.
OpenMined continues to build a strong community around private machine learning, creating courses and open source tools to lower the barrier-to-entry to federated learning and related privacy-enhancing techniques. Alongside those, TensorFlow Federated, IBM’s federated learning library, and flower.dev are extending the tooling ecosystem.
Federated Learning is no panacea. In a privacy setting, decentralized data simply presents a different attack surface to centralized data. Not all applications require or benefit from federation. However, it is an important tool in the private machine learning toolkit.
While the field has advanced in the preceding years, our report remains a relevant and accessible introduction. We hope that by sharing it with data scientists and leaders, we can help encourage the adoption of privacy-preserving machine learning. You can hear our colleague Mike, who led our report, discussing Federated Learning on a recent episode of the Software Engineering Daily podcast here: Federated Learning with Mike Lee Williams.
Check out our newly-free report on Federated Learning, and stay informed about emerging machine learning capabilities in our other Fast Forward research reports.
Editor's Choice

