

Synopsis
This article introduces a new Apache Hadoop feature called S3Guard. S3Guard addresses one of the major challenges with running Hadoop on Amazon’s Simple Storage Service (S3), eventual consistency. We outline the problem of S3’s eventual consistency, how it affects Hadoop workloads, and explain how S3Guard works.
Problem
Although Apache Hadoop has support for using Amazon Simple Storage Service (S3) as a Hadoop filesystem, S3 behaves different than HDFS. One of the key differences is in the level of consistency provided by the underlying filesystem. Unlike HDFS, S3 is an eventually consistent filesystem. This means that changes made to files on S3 may not be visible for some period of time.
Many Hadoop components, however, depend on HDFS consistency for correctness. While S3 usually appears to “work” with Hadoop, there are a number of failures that do sometimes occur due to inconsistency:
- FileNotFoundExceptions. Processes that write data to a directory and then list that directory may fail when the data they wrote is not visible in the listing. This is a big problem with Spark, for example.
- Flaky test runs that “usually” work. For example, our root directory integration tests for Hadoop’s S3A connector occasionally fail due to eventual consistency. This is due to assertions about the directory contents failing. These failures occur more frequently when we run tests in parallel, increasing stress on the S3 service and making delayed visibility more common.
- Missing data that is silently dropped. Multi-step Hadoop jobs that depend on output of previous jobs may silently omit some data. This omission happens when a job chooses which files to consume based on a directory listing, which may not include recently-written items.
Solution
To address these issues caused by S3’s eventual consistency, we worked with the Apache Hadoop community to create a new feature, called S3Guard. S3Guard is being developed as part of the open source Apache Hadoop S3 client, S3A. S3Guard works by logging all metadata changes made to S3 to an external, consistent storage system, called a Metadata Store. Since the Metadata Store is consistent, S3A can use it to fill in missing state that may not be visible yet in S3.
We currently support a DynamoDB-based Metadata Store for use in production. We also have written an in-memory Metadata Store for testing. We designed the system to allow adding additional back end databases in the future.
The initial version of S3Guard fixed the most common case of inconsistency problems: List after create. If a Hadoop S3A client creates or moves a file, and then a client lists its directory, that file is now guaranteed to be included in the listing. This version of S3Guard shipped in CDH 5.11.0. The next feature we added was delete tracking. Delete tracking ensures that, after S3A deletes a file, subsequent requests for that file metadata, either directly, or by listing the parent directory, will reflect the deletion of the file. We have also designed S3Guard with performance in mind, and have seen speedups on certain workloads. Keep an eye out for more performance enhancements in the future.
How S3Guard List Consistency Works
This is a simple example of how S3Guard enables list-after-create consistency in S3A. We start our example with nothing but a S3 bucket that contains two directories, /a and /a/b, and one file /a/b/exists.
![[Figure 1 - Existing S3 Bucket]](https://blog.cloudera.com/wp-content/uploads/2019/08/Figure-1-Existing-S3-Bucket.png)
[Figure 1 – Existing S3 Bucket]
![[Figure 2 - Creating a New Metadata Store]](https://blog.cloudera.com/wp-content/uploads/2019/08/Figure-2-Creating-a-New-Metadata-Store.png)
[Figure 2 – Creating a New Metadata Store]
![[Figure 3 - After Creating a new file /a/b/file]](https://blog.cloudera.com/wp-content/uploads/2019/08/Figure-3-After-Creating-a-new-file-abfile.png)
[Figure 3 – After Creating a new file /a/b/file]
![[Figure 4 - Creating a Consistent Listing]](https://blog.cloudera.com/wp-content/uploads/2019/08/Figure-4-Creating-a-Consistent-Listing-1.png)
[Figure 4 – Creating a Consistent Listing]
How S3Guard Delete Tracking Works
Delete tracking in S3Guard works by storing a “is deleted” flag, also known as a tombstone, along with the path in the Metadata Store. Continuing our example from above, assume we have a S3Guard-enabled Hadoop cluster with two files and two directories, as shown in Figure 5.
![[Figure 5 - Before Deleting a File]](https://blog.cloudera.com/wp-content/uploads/2019/08/Figure-5-Before-Deleting-a-File-1.png)
[Figure 5 – Before Deleting a File]
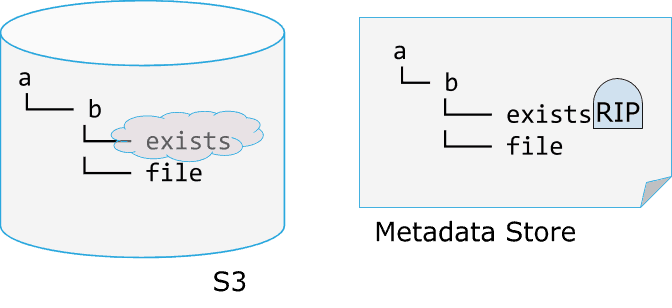
[Figure 6 – After Deleting /a/b/exists]
![[Figure 7 - Consistent List After Delete]](https://blog.cloudera.com/wp-content/uploads/2019/08/Figure-7-Consistent-List-After-Delete-1.png)
[Figure 7 – Consistent List After Delete]
Related Open Source Work
Although S3Guard is the first S3 consistency implementation to be committed to the Apache Hadoop codebase, it is not the first system of its kind. S3Guard was inspired by Netflix’ S3mper and shares parts of its architecture.
More Details
This article provided a basic overview of S3Guard, but if you would like to learn more of the implementation details, I invite you to read the original design document and check out the Apache Hadoop JIRA that tracks its development.
Try S3Guard Today
For those of you wanting to try S3Guard, the CDH documentation is here. I also encourage you to take advantage of Cloudera’s Altus Data Engineering product to quickly provision a cluster in the cloud and try out S3Guard.
Credits
Thank you to the Apache Hadoop community for working with us on S3Guard. In particular, thanks to Steve Loughran, Lei (Eddy) Xu, Mingliang Liu, Sean Mackrory, Chris Nauroth, Ai Deng, and everyone else who contributed.
Editor's Choice

