

Unmodified TPC-DS-based performance benchmark show Impala’s leadership compared to a traditional analytic database (Greenplum), especially for multi-user concurrent workloads. Additionally, benchmark continues to demonstrate significant performance gap between analytic databases and SQL-on-Hadoop engines like Hive LLAP, Spark SQL, and Presto.
The past year has been one of the biggest for Apache Impala (incubating). Not only has the team continued to work on ever-growing scale and stability, but a number of key capabilities have been rolled out that further solidifies Impala as the open standard for high-performance BI and SQL analytics. For cloud and hybrid deployments, Impala now delivers cloud-native elasticity, flexibility, as well as the ability to read/write directly from Amazon S3 object store (with additional object stores planned for the upcoming year). With the GA of Apache Kudu, users can now run high-performance analytics with Impala over data immediately as it arrives or is updated. It’s also even easier to migrate existing BI workloads from traditional analytic databases or data warehouses to Cloudera’s analytic database built with Impala, as well as optimize performance along the way, using Navigator Optimizer. And, as always, performance improvements at greater concurrency remained a key priority throughout the year.
In addition to these advancements, Impala’s adoption has continued to grow as more and more organizations (like NYSE and Quest Diagnostics) look to Cloudera’s modern analytic database — rather than traditional analytic databases — for its flexibility, scalability, and open architecture to support both SQL and non-SQL workloads (such as data science, machine learning, and operational workloads). These organizations required a system that not only provided these key benefits but did so while also delivering the interactive performance akin to traditional analytic databases.
For this benchmark, we compared the multi-user performance of Cloudera’s modern analytic database with Impala to a traditional analytic database (Greenplum) using unmodified TPC-DS queries. We also looked at how both the analytic databases compared to the SQL-on-Hadoop engines of Hive with LLAP, Spark SQL, and Presto. Overall, we found:
- Impala leads in performance against the traditional analytic database, including over 8x better performance for high concurrency workloads
- There is a significant performance difference between the analytic databases and the other SQL-on-Hadoop engines, with Impala up to nearly 22x faster for multi-user workloads
- These other SQL-on-Hadoop engines were also unable to complete the large-scale benchmark to compare to the analytic databases, so a simplified, smaller scale benchmark was needed (with Hive even still requiring modifications and Presto unable to complete multi-user tests)
Read on for the full details.
Comparative Set
Analytic Databases (tested at 10TB and 1TB scale, unmodified queries)
- Impala 2.8 from CDH 5.10
- Greenplum Database 4.3.9.1
Additional SQL-on-Hadoop engines (tested at 1TB scale with some query modifications for Hive)
- Spark SQL 2.1
- Presto 0.160
- Hive 2.1 with LLAP from HDP 2.5
Configuration
Cluster consisting of seven worker nodes each with:
- CPU: 2 x E5-2698 v4 @ 2.20GHz
- Storage: 8 x 2TB HDDs
- Memory: 256GB RAM
Three clusters consisting of identical hardware were configured, one for Impala, Spark, and Presto (running CDH), one for Greenplum, and one for Hive with LLAP (running HDP). Each cluster was loaded with identical TPC-DS data: Parquet/Snappy for Impala and Spark, ORCFile/Zlib for Hive and Presto, and Greenplum used its own internal columnar format with QuickLZ compression.
Queries
Workload:
- Data: TPC-DS 10TB and 1TB scale factor
- Queries: TPC-DS v2.4 query templates (unmodified beyond TPC-DS specification)
We ran the 77 queries that all the engines had language support to run without modifications to the TPC-DS spec (except Hive).1 The 22 excluded queries all use the following less common SQL functionality:
- 11 queries with
ROLLUP(TPC-DS permitted variants not used in this testing) - 3 queries with
INTERSECTorEXCEPT - 8 queries with advanced subquery placements (eg. subquery in
HAVINGclause, etc.)
Due to Hive’s even greater limitations on subquery placement, we were forced to make a number of modifications to create semantically equivalent queries. We ran these modified queries just for Hive.
While Greenplum, Presto, and Spark SQL also claim to support all 99 queries unmodified, Spark SQL and Presto could not successfully complete the 99 queries at the 10TB scale even without concurrency. Greenplum exhibited increasing query failures with increasing multi-user concurrency (details below).
If interested, see this previous blog and the published TPC-DS based kit on the modifications for the additional 22 queries to run all 99 queries with Impala.
Analytic Database Benchmark Results: Impala vs. Greenplum at 10TB Scale
Impala and Greenplum were tested at the 10TB scale using the common 77 unmodified TPC-DS queries. Both a single-user test and a more realistic set of multi-user tests comparing two, four, and eight concurrent streams were run. To summarize:
- Overall, Impala outperforms Greenplum for both the single-user and multi-user concurrency tests
- Impala scales better with increasing concurrency going from 2x faster to 8.3x faster while also maintaining a significantly higher success rate than Greenplum
In the single-user test, Impala outperformed Greenplum by a factor of 2.8x when comparing the geometric mean across queries and by a factor of 1.8x for total time to finish the query stream:
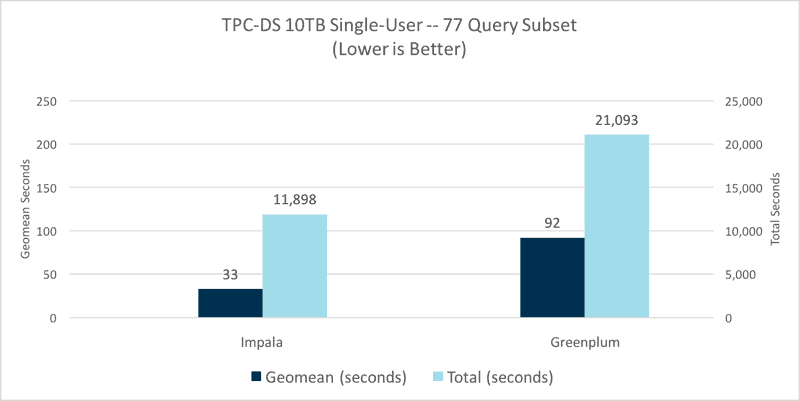
For the multi-user throughput comparison, the same set of 77 unmodified queries were run using the TPC-DS dsqgen tool to generate concurrent query streams. Each query stream consisted of the common 77 queries in a random order and each stream used different query substitution values. We ran multiple tests, increasing the number of query streams beyond the points of system saturation and measured throughput across all succeeding queries at each level of concurrency.
As shown in the below chart, Impala’s performance lead accelerates with increasing concurrency going from 2x faster with two streams to 8.3x faster with eight streams when compared to Greenplum.
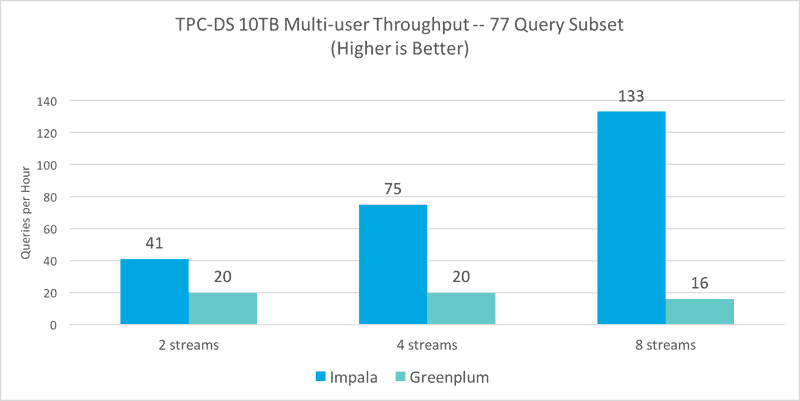
Given the modest size of the cluster compared to the data set size and concurrency, for both systems it was expected to see some query failures as concurrency was increased. Both Impala and Greenplum achieve 100% success rate at the two stream test. for the four and eight stream tests, Impala averaged 97% success while Greenplum dropped to 50% success for the same. If these tests were run on a cluster larger than the 7-node cluster, one would expect the success rates to improve for both systems.
Analytic Databases vs. SQL-on-Hadoop Engines: 1TB Benchmark
An attempt was made to use the same 77 queries and 10TB scale factor benchmark with the inclusion of the additional SQL-on-Hadoop engines, however, Hive, Presto, and Spark SQL all failed to successfully complete many of the 77 unmodified queries even for just single-user results, thus making it not possible to run a comparison at 10TB.
We, therefore, ran a separate comparison at the 1TB scale to compare the analytic database engines with the rest of the SQL-on-Hadoop engines. The same 77 TPC-DS queries were used across all engines except Hive, which required some modifications to work around its limitations in handling subqueries that would have otherwise failed to parse.
With these simplified criteria necessary for the other SQL-on-Hadoop engines to participate, we again ran both a single-user test and a more realistic multi-user test across all five engines. To summarize:
- Analytic databases – Impala and Greenplum – outperform all SQL-on-Hadoop engines at every concurrency level
- Impala again sees its performance lead accelerate with increasing concurrency by 8.5x-21.6x
- Presto demonstrated the slowest performance out of all the engines for the single-user test and was unable to even complete the multi-user tests
In this single-user test, we see again Impala maintains its performance lead when comparing the geometric mean, however, Greenplum has a slight edge on total time. Both analytic databases drastically outperform the other engines, with Impala outperforming the other SQL-on-Hadoop engines by 3.6x to 13x for geometric mean and 2.8x-8.3x for total time.
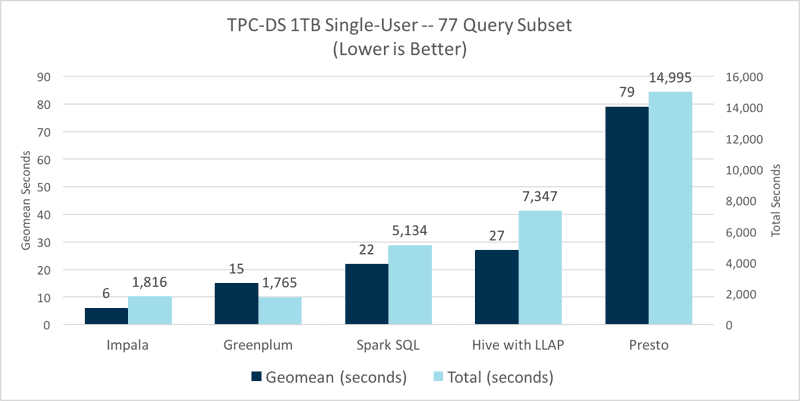
Presto struggles with common SQL queries beyond simple single table scans with filters, groupings, and aggregations. For these very simple type of queries it tends to perform more in line with Spark SQL but, as demonstrated above, performs the worst of the SQL-on-Hadoop cohort for more typical BI queries leveraging more standard SQL including joins.
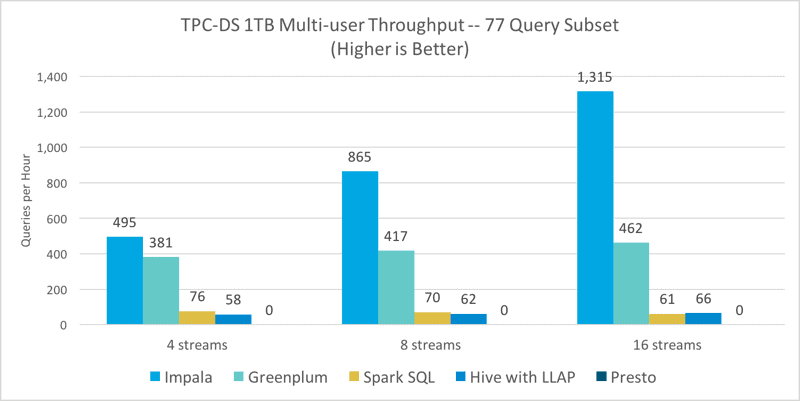
The more representative multi-user comparison tests were run with four, eight, and sixteen concurrent streams using TPC-DS dsqgen to generate the randomized query streams as with the 10TB analytic database comparison above. All engines except Presto were able to complete the streams without any query failures at the 1TB scale at all three concurrency levels. Even when running just four concurrent queries, Presto would fail most queries with out of memory errors.
For the engines that were able to successfully complete the multi-user concurrency tests, the difference in performance between the analytic database cohort and the SQL-on-Hadoop cohort becomes even more apparent. Impala proves superior throughput at every concurrency level — not only 1.3x-2.8x faster than Greenplum, but an even more substantial difference compared to Spark SQL, where it’s 6.5x-21.6x faster, and Hive where it’s 8.5x-19.9x faster.
Conclusion
Organizations are increasingly looking to modernize their architecture, however, not at the expense of interactive, multi-user performance necessary for their important BI and SQL analytics. Impala, as part of Cloudera’s platform, is uniquely able to deliver a modern analytic database. By design, Impala has the flexibility to support a greater variety of data and use cases, without any upfront modeling; it can elastically and cost-effectively scale on-demand both on-premises and in the cloud; and as part of this shared platform, this same data is available to other teams and workloads beyond just SQL analytics for extended value. In addition, as we’ve seen from the above benchmark results, Impala provides all this on top of having the leading performance compared to traditional analytic databases.
The difference between the analytic database cohort (Impala, Greenplum) and the SQL-on-Hadoop cohort (Hive, Presto, Spark) also becomes apparent, both in overall performance and the ability to run at-scale and with increasing concurrency. While these other SQL-on-Hadoop engines aren’t able to meet the requirements for analytic database workloads, that doesn’t mean they don’t have value for other workloads. In fact, a vast majority of Cloudera customers leverage the platform’s open architecture to prepare their data with Hive, build and test models with Spark, and run BI and reporting with Impala, all without having to copy data across disparate silos.
Over the next year, we will continue to drive significant advancements for our modern analytic database, with Impala at the core, including around adding intelligence and automation to the BI experience, continuing to expand cloud support, and further improving multi-tenancy and scalability. Be on the lookout for more details on the blog.
And as usual, we encourage you to independently verify these results by running your own benchmarks based on the open benchmark toolkit.
Greg Rahn is the Director of Product Management at Cloudera for the Impala team.
Mostafa Mokhtar is a Software Engineer at Cloudera, working on the Impala team.
- 1, 2, 3, 4, 6, 7, 11, 12, 13, 15, 16, 17, 19, 20, 21, 25, 26, 28, 29, 30, 31, 32, 33, 34, 37, 39, 40, 41, 42, 43, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 68, 69, 71, 73, 74, 75, 76, 78, 79, 81, 82, 83, 84, 85, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99 ↩︎
Editor's Choice

