

The emergence of “Big Data” has made machine learning much easier because the key burden of statistical estimation—generalizing well to new data after observing only a small amount of data—has been considerably lightened. In a typical machine learning task, the goal is to design the features to separate the factors of variation that explain the observed data. However, a major source of difficulty in many real-world artificial intelligence applications is that many of the factors of variation influence every single piece of data we can observe. Deep learning solves this central problem via representation learning by introducing representations that are expressed in terms of other, simpler representations.
Companies and researchers are analyzing ever-increasing amounts of data to impact the evolution of current and future technologies. Apache Hadoop and related ecosystems have come to play a significant role in “Big Data Analytics”. They provide a rich and wide choices for handling format, source variation, fast-moving/evolving streaming data, security and trust handling, distributed and noisy sources, supported algorithms, high dimensions as well as scalability of cluster.
However, traditional machine learning and feature engineering algorithms are not efficient enough to extract complex and nonlinear patterns, which are hallmarks of the big data. Deep Learning, on the other hand, helps translate the scale and complexity of the data into solutions like molecular interaction in drug design, search for subatomic particles and automatic parsing of microscopic images.
It goes without saying that colocating a data processing pipeline with a Deep Learning framework makes data exploration/algorithm and model evolution much simpler and at the same time makes data governance and lineage tracking a consolidated effort.
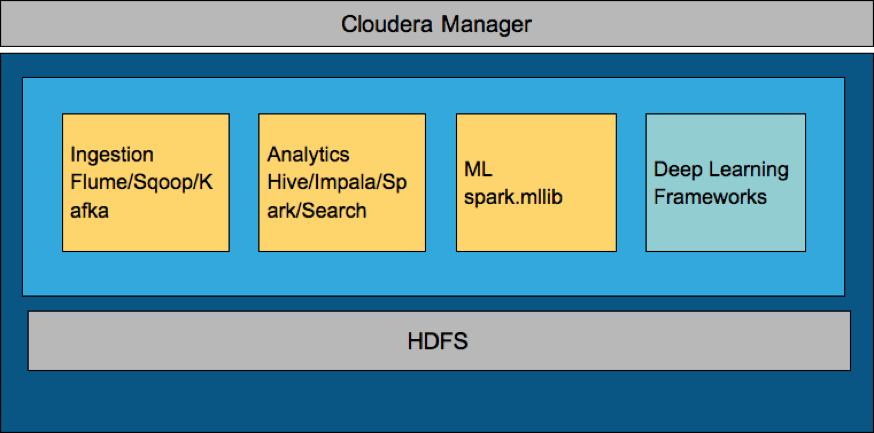
Cloudera Data Science Workbench
Cloudera Data Science Workbench is a comprehensive tool to apply fast and interactive data analysis to evolving models and algorithms as the new data and insights present themselves. It can operate either on on-premise or across public clouds and is a capability of the CDH platform. Cloudera Data Science Workbench provides a predictable, isolated file system and networking setup via Docker containers, across R, Python and Scala users. Users do not have to worry about which libraries are installed on the host, port contention with other user’s processes on the host, and the admins do not have to worry about users adversely impacting the host or other user’s workloads.
In Cloudera Data Science Workbench, Docker will provide admins with a convenient way to package R and Python libraries for their users via the extensible engines feature. It is particularly attractive, as it lets you interact with the output, model and code, all the while being under the same cluster. It makes it very easy to analyze the results and tweak the model parameters to observe delta changes.
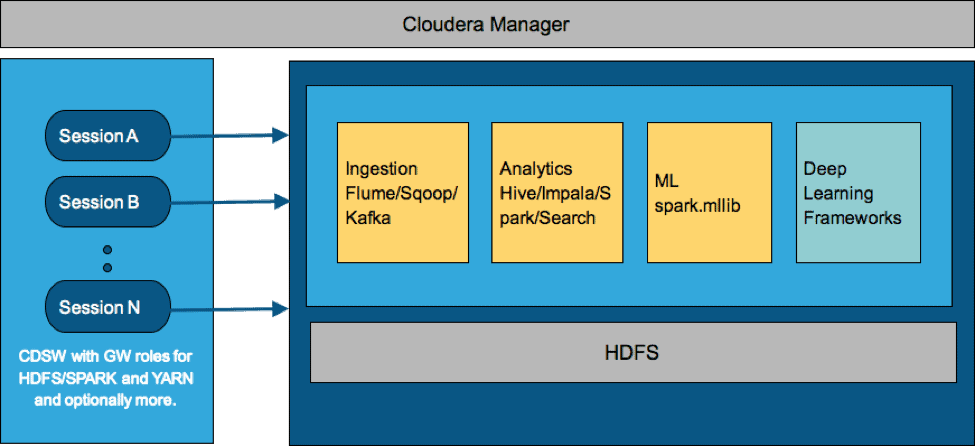
In this blog, we discuss the setup details associated with getting different open-source Deep Learning frameworks working in CDH, and subsequently in Cloudera Data Science Workbench. Once the framework works in the underlying CDH platform in Spark-on-YARN mode, we demonstrate that it is not hard to translate that work into Cloudera Data Science Workbench. In the tool, it is trivial to tweak the parameters, visualize the results, change and compile the source code and retrain and redeploy. CDSW helps each user/role set up their own environment. With the help of extensible engines, and configurable sessions, we can have multiple users test out their own frameworks and algorithms on the same cluster without having to move the data out of the system.
Note: This is not a Deep Learning tutorial or a comparison of different DNN frameworks.
For this blog, and related experiments we use CentOS 7.2 OS, JDK 1.7, CDSW 0.8 (private beta) and Python 2.7.11. We choose frameworks which are more in use across multiple domain areas and those which we have come across in our experiments and have seen deployed out in the field.
CPU and GPUs
Deep Neural Networks (DNNs) require large amounts of computation, especially during the training phase. They can have well over a million (sometimes a billion) parameters to adjust via back propagation. Furthermore, they require large amounts of training data to achieve high accuracy, which translates to several backward and forward passes. Since, neural nets are created from large numbers of identical neurons, they are inherently parallel in nature, which naturally translates to efficient computations to GPUs. The performance increase obtained over CPU only training as compared to GPUs is demonstrably multi-fold. Furthermore, there are accelerated primitive libraries available for DNNs, such as NVIDIA cuDNN which provide even further boost in performance. They provide tuned implementations of routines that arise frequently in DNN applications, such as convolution, pooling, softmax, neuron activations including Sigmoid, ReLU and TANH. In the same vein, there are libraries available to accelerate the performance of analytical and artificial intelligence algorithmic workloads with less expensive hardware.
We give steps to leverage cuDNN libraries if you plan to run your DNN workloads on GPU enabled CDH cluster. In brief, you would need to download your respective NVIDIA driver, download and install the CUDA toolkit and then install cuDNN libraries. The frameworks that we discuss below can take advantage of both CPU and or GPU devices.
Note: Be mindful of the cuDNN versions between Tensorflow and Caffe.
Run with your own Python
When you want a specific version of python or related libraries, it is a very good idea to use an environment maintained by Conda. System environments and utilities are very much tied to the default python which ships with the OS and things may break and stop functioning if tinkered with. In our test cluster, the default CentOS 7.2 image shipped with Python 2.5. We instead installed Anaconda, and set up a Python virtual environment within to match the CDSW stock Python version 2.7.11. Make sure to install the Anaconda and environment in a /usr/local or directly under /usr so that we can mount it to our CDSW session when needed. The Anaconda, Python and Tensorflow install are in this script. One reason to install Tensorflow in it’s own environment is a different version of protobuf (>3.1.0). Our Anaconda install directory is /usr/anaconda. Be sure to edit/comment this line when you use this script. You can also use Continuum’s Anaconda parcel for Cloudera.
If you already have a conda installed with a different version of python than that of CDSW, you might want to create a new environment with the 2.7.11 or 3.6.1 version of python to match the version of CDSW session engines.
This script can be deployed in parallel to all the nodes using a utility such as pssh.
Dataset
We use the mnist data set, available from http://yann.lecun.com/exdb/mnist/. This is a good starter data set, very well normalized and cleaned to test the functionality of our frameworks on CDH and Cloudera Data Science Workbench without getting too much into details of data noise or skew.

Tensorflow On Spark
We use the library TensorFlowOnSpark made available by Yahoo to run the DNNs from Tensorflow on CDH and CDSW. Getting Tensorflow to run smoothly in CDH environment requires couple of variables to be set cluster wide. Specifically, HADOOP_HDFS_PREFIX and CLASSPATH. The JNI interface has trouble expanding the asterisk delimited paths, so we need to add the full output of “hadoop classpath –glob” to the CLASSPATH variable.
If using CUDA, then make sure that your LD_LIBRARY_PATH points to those libraries or those libraries are available in the system path.
- git clone https://github.com/WhiteFangBuck/CDSW-DL.git
cd TensorFlowOnSpark- We made some changes to the code to work with CDSW. – the original TensorFlowOnSpark works fine with underlying CDH.
pushd CDSW-DL/TensorFlowOnSpark/srczip -r ../tfspark.zip *popd
- Make sure Python environment is set up on all the nodes.
- We would need tensorflow-hadoop libraries to read write the TFRecord formats.
git clone https://github.com/tensorflow/ecosystem.gitcd ecosystem/hadoopMake sure your pom.xml has the right artifacts.mvn clean installhadoop fs -copyFromLocal target tensorflow-hadoop-1.0-SNAPSHOT-shaded-protobuf.jar jars/
Tensorflow DNN on CDSW
We re-use our python set up from earlier and use the environment “py27” which has tensorflow 1.0.0 installed. We make our version of python available by configuring the anaconda distribution available as a system mount.
Note: This will not make the running session’s path environment any different.
We use the base engine, and mount /usr/lib64 (to avoid installing all the dependencies – we can also create a base image with all the dependencies installed into the image) from earlier common setup.
We demonstrate here a sample run on our test data mnist.
- Have the mnist data be available in a zipped format in the cdsw home directory.
- Have the TensorFlowOnSpark directory be available in the cdsw home directory.
mkdir ${HOME}/mnistpushd ${HOME}/mnist >/dev/nullcurl -O "http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz"curl -O "http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz"curl -O "http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz"curl -O "http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz"zip -r mnist.zip *popd >/dev/null
- Run the script convert_to_csv.sh
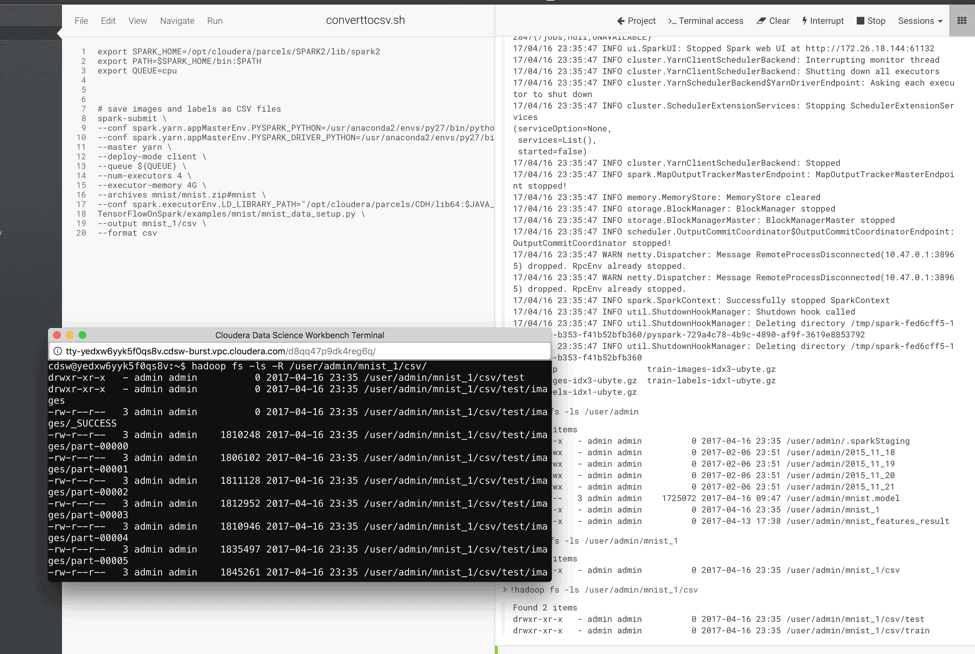
- Run the script save_as_tfrecords.sh
- Run distributed training using feedforward
- Run distributed inference using feedforward
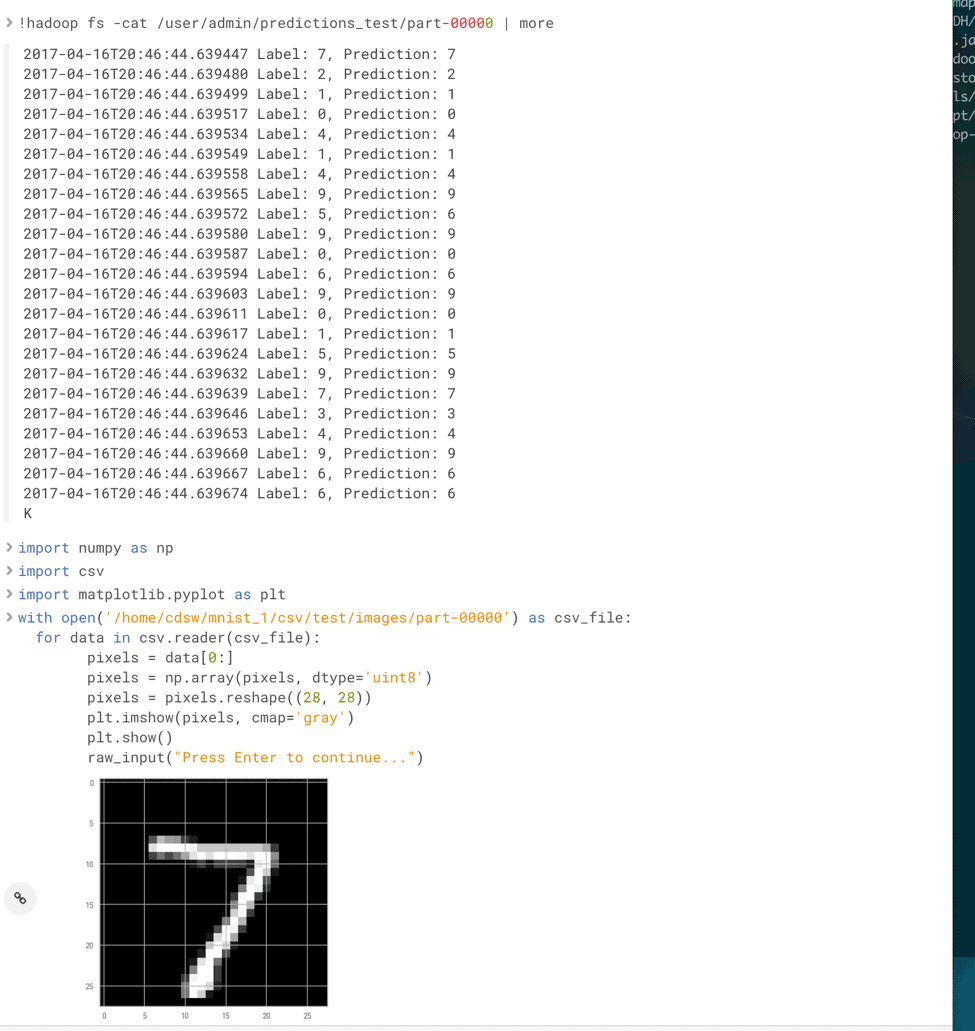
- Let’s look at our first output and verify the result.
Caffe though CDH and CDSW
The Caffe is a Deep Learning Framework from Berkley Vision Lab implemented in C++ where models and optimizations are defined as plaintext schemas instead of code. It has a command line as well as a Python interface and has been widely adopted especially for vision related tasks. Last year a group from Yahoo released a Spark interface for Caffe which gives you the ability to run the DNN model within the same cluster where your ingested data and other analytical frameworks reside, conforming to the company wide security and governance policies.
Executors when running CaffeOnSpark communicate with each other via MPI allreduce style interface via either TCP/Ethernet or Infiniband/RDMA. This enables CaffeOnSpark to achieve far greater performance as compared to traditional Spark computations. The Caffe engines are launched within a Spark executor using JNI layer for fine-grained memory management. It also helps retain state for long running jobs by snapshotting training state periodically.
There has been a more recent development in the Caffe world where Facebook released cross platform update to Caffe, called Caffe2. They also released a few extensions to the original Caffe. In this blog we only work with the original release of Caffe from Berkley.
Dependencies for Caffe/CaffeOnSpark
Caffe requires several dependencies to be satisfied and they are documented here. Note: some dependencies may require further resolution depending on your kernel. Be sure to check if all the dependencies are satisfied cleanly. The lists are long, but the output should look something like:
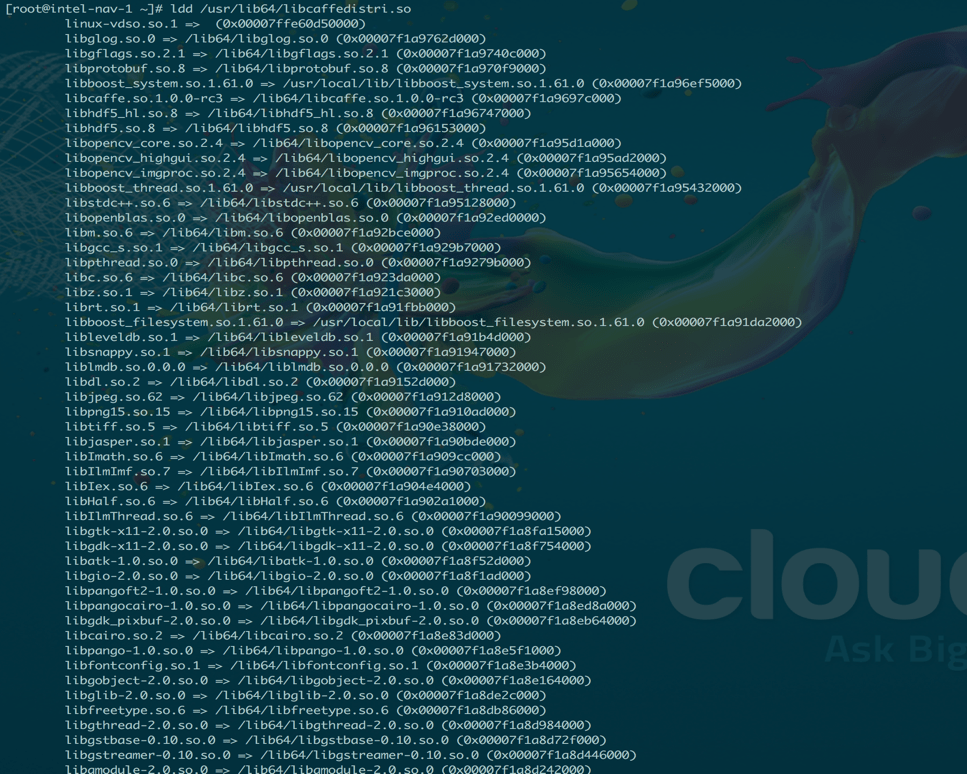
There are a few specifics we used in our implementation:
- After running the setup-caffe.sh, edit your Makefile.config to reflect following changes
- CPU_ONLY or CUDNN_ONLY (We uncomment CPU_ONLY)
- BLAS (We use open)
- BLAS include directories (/usr/include/openblas)
- ANACONDA_HOME (we give our environment) and related PYTHON_INCLUDE and PYTHON_LIB.
- Any other INCLUDE_DIRS and LIBRARY_DIRS
- pushd $CAFFE_ON_SPARK
- make build
- Check the dependencies for the shared library are resolved.
- Copy the shared files into /usr/lib64
- cp $CAFFE_ON_SPARK/caffe-distri/distribute/lib/* /usr/lib64/
- Do a test run of a job on Spark:
export LD_LIBRARY_PATH=<path to cuda libraries>:<path to caffe libraries>
spark2-submit --master yarn --deploy-mode client \
--conf spark.executor.instances=<number of executors> \
--conf spark.executor.cores=<number of cores> \
--files ./lenet_memory_solver.prototxt,./lenet_memory_train_test.prototxt \
--conf spark.driver.extraLibraryPath="${LD_LIBRARY_PATH}" \
--conf spark.executorEnv.LD_LIBRARY_PATH="${LD_LIBRARY_PATH}" \
--class com.yahoo.ml.caffe.CaffeOnSpark \
target/caffe-grid-0.1-SNAPSHOT-jar-with-dependencies.jar \
-train -features accuracy,loss \
-label label \
-conf lenet_memory_solver.prototxt \
-connection ethernet \
-model mnist.model \
-output mnist_features_result
Let’s Run on CDSW
There are two ways to make the shared libraries available to the CDSW session container during runtime. The easier way is to make the libraries be part of a mounted directory, but then these libraries would be part of each project and session launched. Unless you are very sure, we suggest mounting only system paths such as /usr/lib64 which would not conflict with the default mounted directories for CDSW sessions. Please note, that once your session is up, you will only have write level access to the default home folder /home/cdsw. So, any changes that you would like to happen in the environment, need to be done before the session is launched.
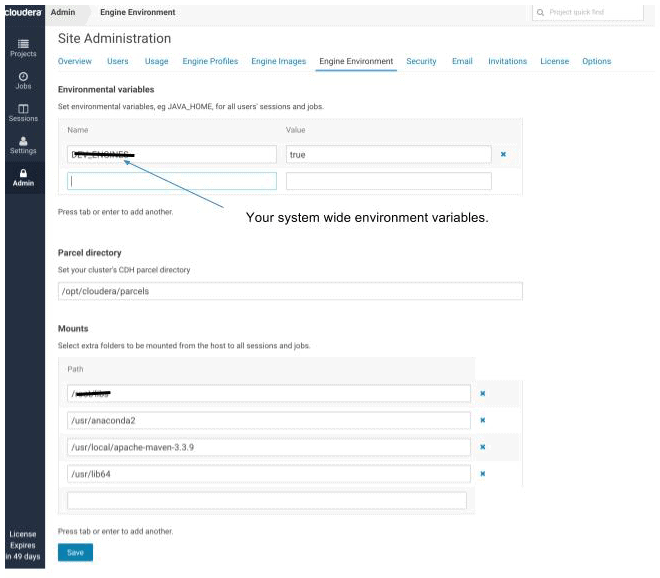
Another way, which is more elegant, is to take advantage of extensible engines feature of the CDSW. All you need to do is pull in your base image for the Docker container, make a new build from it and then push it back to the registry.
A sample Dockerfile has been provided here to create a new image. This file copies the local directories of shared libraries for cuda and boost and also creates entries in the ldcache.
- Pull the base image
- Build an extensible using the Dockerfile
- Push it out to the repo
- Whitelist the engine in the CDSW panel as shown below:

- Use this image in your project settings when launching the relevant session.
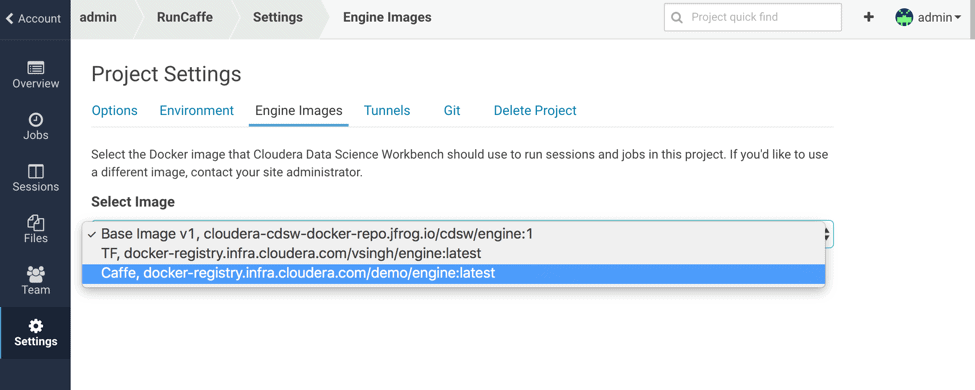
To run Caffe On Spark in CDSW, do the following:
- Create a project.
- Modify any environment settings such as LD_LIBRARY_PATH
- Once the session is up, you can copy the relevant files into your local home directory using HDFS. We had copied the relevant jar file, data(mnist) and two solver files into HDFS. You can also use “upload file/directory” feature of the CDSW, but that copies from the local machine.
- Once in the session, create a new bash file
- In the interactive shell type !bash <your scriptname>
A few others: BigDL and DL4J
DL4J is a distributed library for Deep Learning written for Java and Scala and integrated with Hadoop and Spark. The underlying computations are in C, C++ and CUDA and has Keras as its Python API. To use DL4J in CDH/CDSW, either compile the library from source or download the relevant spark artifacts. Simply make the jar available as part of spark-defaults.conf.
We demonstrate a similar example for BigDL where we compile the project within the CDSW session. BigDL is a distributed deep learning library for Spark that run directly on top of Spark or YARN and application interface can be either in Scala or Python. BigDL uses Intel® Math Kernel Library (Intel® MKL) and multi-threaded programming to achieve high performance.
Note: More elaborate blogs on these particular frameworks are forthcoming .
- Create a new project and provide the github link
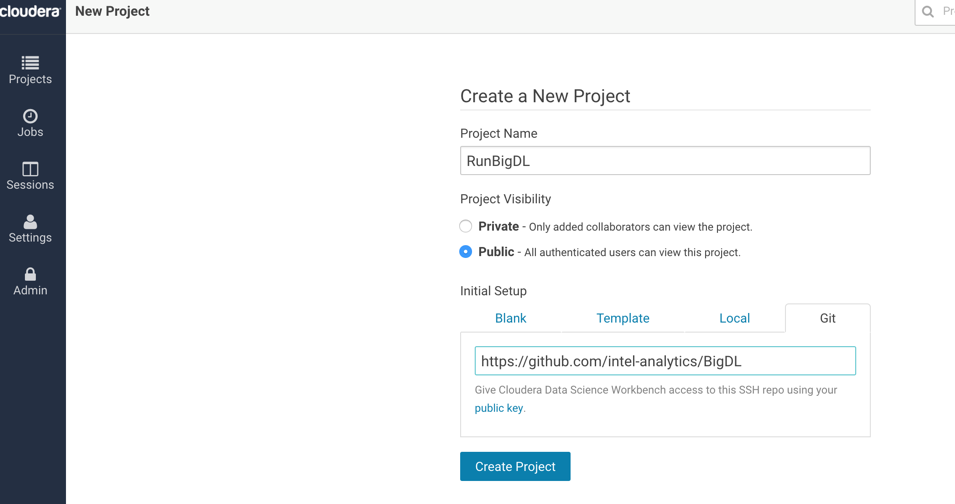
- Click on create project
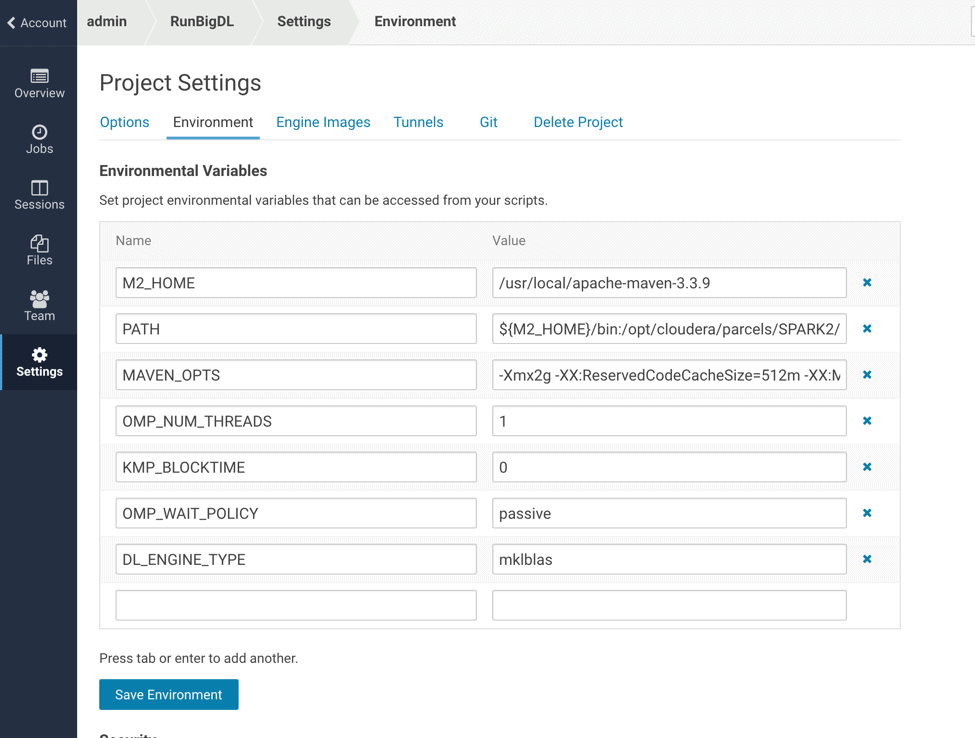
- Set the environment variables in the project settings. We specifically provide the maven path to the mounted directory. This is ideal if you would like to make changes in the source code and compile again, but this may warrant the session needing higher memory. It is much easier to compile the code on the base node and upload the jar to CDSW.
- After launching the session, we will make changes to xml or source code if needed.
- We use the interactive terminal to compile:
- cd BigDL
- !bash make-dist.sh -P cloudera
- !bash bigdl-lenet.sh
Summary
The work in this blog demonstrates the ease of running complex non-linear feature representational algorithms such as DNN on a platform like CDH, where data pre-processing, extraction, analysis are already part of the system along with security and governance. We also show the value of Cloudera Data Science Workbench in being to able launch DNN programs, form a notebook like environment, which spawns off the jobs into the CDH Cluster, taking advantage of cluster compute as well data and model locality and cluster perimeter, user and process isolation and security and can interact, analyze and visualize the output.
Editor's Choice


Data science is a “concept to unify statistics, data analysis, machine learning and their related methods” in order to “understand and analyze actual phenomena” with data.
I had done Data Science course from TGC India. They offer a variety of tutorials covering everything from the processes of Data Science to how to get started with Data Science.