

In my previous post you learned how to index email messages in batch mode, and in near real time, using Apache Flume with MorphlineSolrSink. In this post, you will learn how to index emails using Cloudera Search with Apache HBase and Lily HBase Indexer, maintained by NGDATA and Cloudera. (If you have not read the previous post, I recommend you do so for background before reading on.)
Which near-real-time method to choose, HBase Indexer or Flume MorphlineSolrSink, will depend entirely on your use case, but below are some things to consider when making that decision:
- Is HBase an optimal storage medium for the given use case?
- Is the data already ingested into HBase?
- Is there any access pattern that will require the files to be stored in a format other than HFiles?
- If HBase is not currently running, will there be enough hardware resources to bring it up?
There are two ways to configure Cloudera Search to index documents stored in HBase: to alter the configuration files directly and start Lily HBase Indexer manually or as a service, or to configure everything using Cloudera Manager. This post will focus on the latter, because it is by far the easiest way to enable Search on HBase — or any other service on CDH, for that matter.
Understanding HBase Replication and Lily HBase Indexer
When designing this solution, Cloudera identified four major requirements to make HBase indexing effective:
- Indexing latency must be in near-real-time (seconds) and tunable
- The Solr Index must eventually be consistent with the HBase table while inserts, updates, and deletes are applied to HBase
- The indexing mechanism must be scalable and fault tolerant
- The indexing process cannot slow down HBase writes
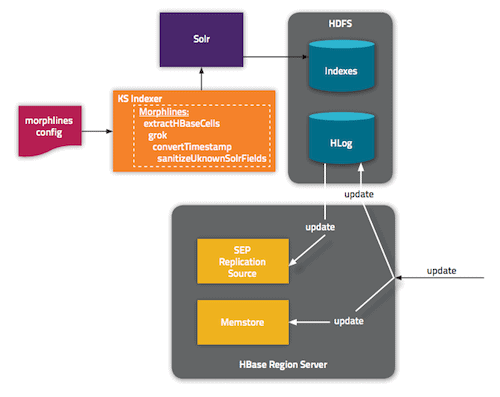
To meet these requirements, Cloudera Search uses HBase’s native replication mechanism. For those unfamiliar with HBase replication, here is a brief and very high-level summary:
As updates are applied to the write-ahead-log (WAL), HBase RegionServer listens to these updates on a separate thread. When that thread’s buffer is filled or it hits the end of the file, it sends the batches with all the replicated updates to a peer RegionServer running on a different cluster. The WAL, therefore, is essential for indexing to work.
Cloudera Search uses the HBase replication mechanism, which listens for HBase row mutation events and, instead of sending updates to a different RegionServer, sends them to Lily HBase Indexer. In turn, Lily HBase Indexer applies Cloudera Morphlines transformation logic, breaking up the events into Solr fields and forwarding them into Apache Solr Server.
There are major advantages to using HBase replication versus implementing the same functionality in HBase coprocessors. First, replication works in parallel and asynchronously with the data being ingested into HBase. Therefore, Cloudera Search indexing does not add any latency or operational instability to routine HBase operation. Second, using the replication method allows for seamless on-the-fly changes to transformation logic. Conversely, to effect a change through coprocessor modification requires a RegionServer restart, which would make data unavailable to HBase users. Perhaps most important is that implementing coprocessors is fairly intrusive and, if not tested properly, can disrupt HBase performance.
This flow is illustrated below:
Installing Cloudera Search and Deploying Lily HBase Indexer
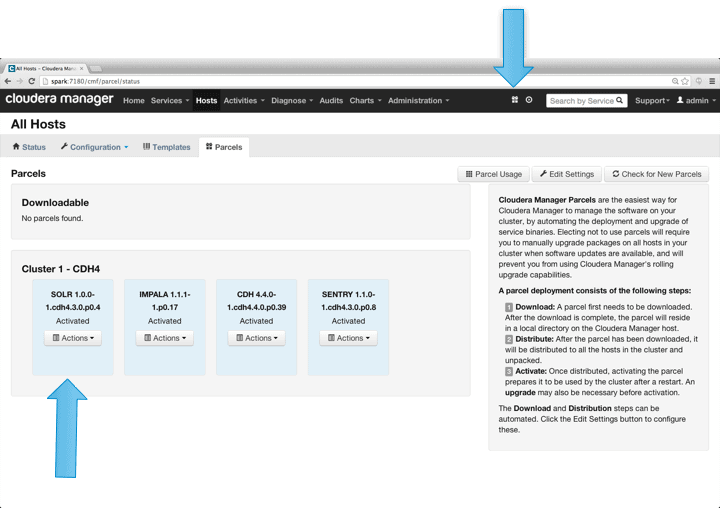
Cloudera Manager downloads and deploys Cloudera Search as a single package automatically. All you have to do is to click the “Packages” icon in the top nav, choose the Solr version, and download, distribute, and activate it:
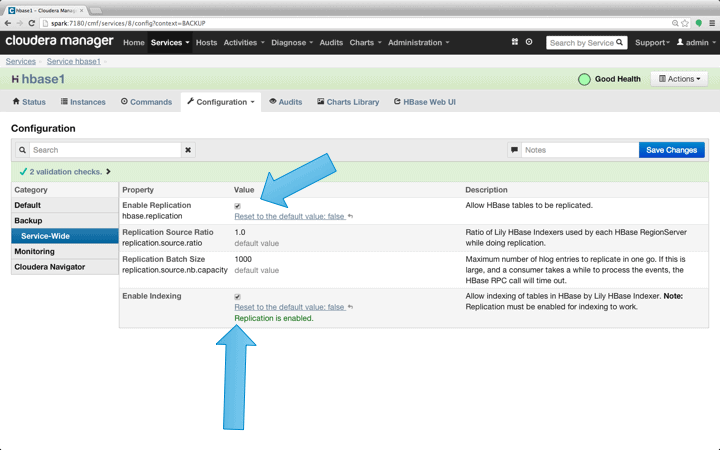
As mentioned previously, Cloudera Search depends on HBase replication, and, therefore, that will be enabled next. Activate replication by clicking HBase Service->Configuration->Backupand ensuring “Enable HBase Replication” and “Enable Indexing” are both checked. If necessary, save the changes and restart the HBase service.

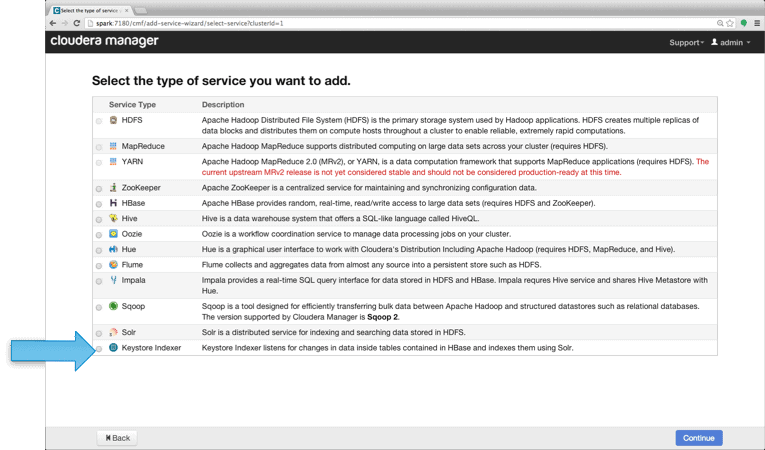
To add Lily HBase Indexer, go to Services->Add Service, choose “Keystore Indexer”, and add it, pointing it to the HBase instance that will be used for email processing:
Configuring Solr
Next, configure Solr exactly as described in the previous post here.
- Generate a sample schema.xml configuration file:
$ solrctl --zk localhost:2181/solr \ instancedir --generate $HOME/emailSearchConfig
- Edit the schema.xml file in $HOME/emailSearchConfig, with the config file that will define fields relevant to email processing. A full copy of the file can be found at this link.
- Upload the Solr configurations to ZooKeeper:
$ solrctl --zk localhost:2181/solr instancedir \ --create email_collection $HOME/emailSearchConfig
- Generate the Solr collection:
$ solrctl --zk localhost:2181/solr collection \ --create email_collection -s 1
Registering the Indexer
This step is needed to add and configure the indexer and HBase replication. The command below will update ZooKeeper and add myindexer as a replication peer for HBase. It will also insert configurations into ZooKeeper, which Lily HBase Indexer will use to point to the right collection in Solr.
$ hbase-indexer add-indexer -n myindexer -c indexer-config.xml \
-cp solr.zk=localhost:2181/solr \
-cp solr.collection=collection1
Arguments:
- -n myindexer – specifies the name of the indexer that will be registered in ZooKeeper
- -c indexer-config.xml – configuration file that will specify indexer behavior
- -cp solr.zk=localhost:2181/solr – specifies the location of ZooKeeper and Solr config. This should be updated with the environment specific location of ZooKeeper.
- -cp solr.collection=collection1 – specifies which collection to update. Recall the Solr Configuration step where we created collection1.
The index-config.xml file is relatively straightforward in this case; all it does is specify to the indexer which table to look at, the class that will be used as a mapper (com.ngdata.hbaseindexer.morphline.MorphlineResultToSolrMapper), and the location of the Morphline configuration file. The mapping-type is set to column because we want to get each cell as an individual Solr document. By default mapping-type is set to row, in which case the Solr document becomes the full row.
Param name=”morphlineFile” specifies the location of the Morphlines configuration file. The location could be an absolute path of your Morphlines file, but since you are using Cloudera Manager, specify the relative path: “morphlines.conf”.
The contents of the hbase-indexer configuration file can be found at this link.
For the full-reference of hbase-indexer command, it is sufficient to execute the command without any arguments:
$ hbase-indexer Usage: hbase-indexerwhere an option from one of these categories: TOOLS add-indexer update-indexer delete-indexer list-indexers PROCESS MANAGEMENT server run the HBase Indexer server node REPLICATION (EVENT PROCESSING) TOOLS replication-status replication-wait PACKAGE MANAGEMENT classpath dump hbase CLASSPATH version print the version or CLASSNAME run the class named CLASSNAME Most commands print help when invoked w/o parameters.
Configuring and Starting Lily HBase Indexer
If you recall, when you added Lily HBase Indexer, you specified the instance of HBase with which it’s associated. Therefore, you do not need to do that in this step. You do, however, need to specify the Morphlines transformation logic that will allow this indexer to parse email messages and extract all the relevant fields.
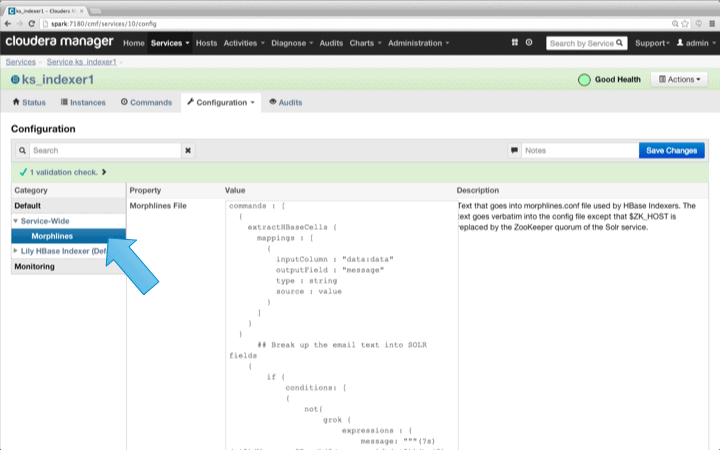
Go to Services and choose Lily HBase Indexer that you added previously. Select Configurations->View and Edit->Service-Wide->Morphlines. Copy and paste the morphlines file.
The email morphlines library will perform the following actions:
1. Read the HBase email events with the extractHBaseCells command
2. Break up the unstructured text into fields with the grok command
3. If Message-ID is missing from the email, generate it with the generateUUID command
4. Convert the date/timestamp into a field that Solr will understand, with the convertTimestamp command
5. Drop all of the extra fields that we did not specify in schema.xml, with the sanitizeUknownSolrFieldscommand
The extractHBaseCells command deserves more attention, as it is the only thing different about the HBase Indexer’s morphlines configuration. The parameters are:
- inputColumn – specifies columns to which to subscribe (can be wild card)
- outputFied – the name of the field where the data is sent
- type – the type of the field (it is string in the case of email body)
- source – could be value or qualified; value specifies that the cell value should be indexed
extractHBaseCells {
mappings : [
{
inputColumn : "messages:*"
outputField : "message"
type : string
source : value
}
]
}
Download a copy of this morphlines file from here.
One important note is that the id field will be automatically generated by Lily HBase Indexer. That setting is configurable in the index-config.xml file above by specifying the unique-key-field attribute. It is a best practice to leave the default name of id — as it was not specified in the xml file above, the default id field was generated and will be a combination of RowID-Column Family-Column Name.
At this point save the changes and start Lily HBase Indexer from Cloudera Manager.
Setting Up the Inbox Table in HBase
There are many ways to create the table in HBase programmatically (Java API, REST API, or a similar method). Here you will use the HBase shell to create the inbox table (intentionally using a descriptive column family name to make things easier to follow). In production applications, the family name should always be short, since it is always stored with every value as a part of a cell key. The following command will do that and enable replication on a column family called “messages”:
hbase(main):003:0> create 'inbox', {NAME => 'messages', REPLICATION_SCOPE => 1}
To check that the table was created properly run the following command:
hbase(main):003:0> describe 'inbox'
DESCRIPTION ENABLED
{NAME => 'inbox', FAMILIES => [{NAME => 'messages', DATA_BLOCK_ENCODING => ' true
NONE', BLOOMFILTER => 'NONE', REPLICATION_SCOPE => '1', VERSIONS => '3',
COMPRESSION => 'NONE', MIN_VERSIONS => '0', TTL => '2147483647', KEEP_DEL
ETED_CELLS => 'false', BLOCKSIZE => '65536', IN_MEMORY => 'false', ENCODE
_ON_DISK => 'true', BLOCKCACHE => 'true'}]}
From this point any email put into table “inbox” in column family “messages” will trigger an event to Lily HBase Indexer, which will process the event, break it up into fields, and send it to Solr for indexing.
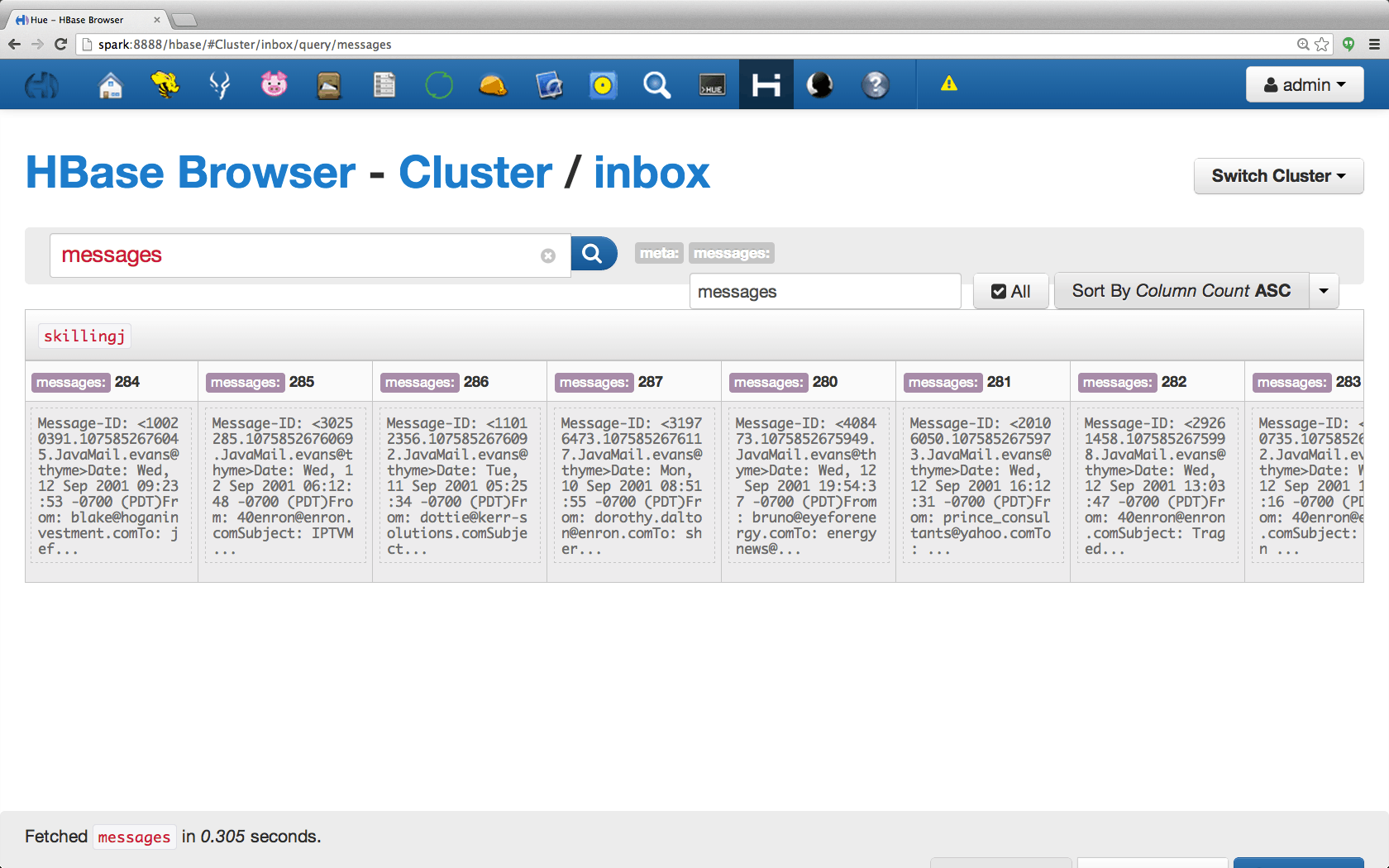
The schema of inbox table is simple: The row ID is the name of the person to whom this inbox belongs. Each cell is an individual message with the column being a unique integer ID. Below is snapshot of a sample table as displayed by Hue’s HBase interface:
Accessing the Data
You have the choice of many visual tools to access the indexed emails. Hue and Solr GUI are both very good options. HBase also enables a number of access techniques, not only from a GUI but also via the HBase shell, API, and even simple scripting techniques.
Integration with Solr gives you great flexibility and can also provide very simple as well as advanced searching options for your data. For example, configuring the Solr schema.xml file such that all fields within the email object are stored in Solr allows users to access full message bodies via a simple search, with the trade-off of storage space and compute complexity.
Alternatively, you can configure Solr to store only a limited number of fields, such as the id, sender, and subject. With these elements, users can quickly search Solr and retrieve the message ID(s) which in turn can be used to retrieve the full message from HBase itself.
The example below stores only the message ID in Solr but indexes on all fields within the email object. Searching Solr in this scenario retrieves email IDs, which you can then use to query HBase. This type of setup is ideal for Solr as it keeps storage costs low and takes full advantage of Solr’s indexing capabilities.
The shell script below issues a query to the Solr Rest API for a keyword “productId” and returns the field “id” in CSV format. The result is a list of document IDs that match the query. The script then loops through the ids and breaks them up into Row Id, Column Family, and Column Name, which are used to access HBase through the standard HBase REST API.
#!/bin/bash
# Query SOLR and return the id field for every document
# that contains the word resign
query_resp=$(curl -s 'http://spark:8983/solr/collection1_shard1_replica1/select?q=productId&fl=id&wt=csv')
# Loop through results of the previous command,
# and use the id to retrieve the cells from HBase via the HBase REST API
for i in $query_resp
do
if [ "$i" != "id" ]; then
cmd=$(echo $i |awk -F'-' '{print "curl -s http://spark:20550/inbox/" $1 "/" $2 ":" $3}')
$cmd -H "Accept: application/x-protobuf "
fi
done
Conclusion
In this post you have seen how easy it is to index emails that are stored in HBase — in near real time and completely non-intrusively to the main HBase flow. In summary, keep these main steps in mind:
- Enable replication in HBase
- Properly configure Lily HBase Indexer
- Use Morphlines in Lily HBase Indexer to help with transformations (no coding required!)
If you have had the opportunity to read the previous post, you can see that the morphlines.conf file is practically identical in all three cases. This means that it is very easy to grow the search use cases over the Hadoop ecosystem. If the data is already in HDFS, use MapReduceIndexerTool to index it. If the data is arriving through Flume, use SolrMorphlineSink with an identical morphlines file. If later you decide HBase fits the use case, only a minimal change is required to start indexing cells in HBase: Just add the extractHBaseCells command to the morphlines file.
Although this example concentrates on emails as a use case, this method can be applied in many other scenarios where HBase is used as a storage and access layer. If your enterprise uses HBase already for a specific use case, consider implementing Cloudera Search on top of it. It requires no coding and can really open up the data to a much wider audience in the organization.
Jeff Shmain is a solutions architect at Cloudera.
Editor's Choice


The previous post link is not working. Please can that be fixed.