

Every enterprise is trying to collect and analyze data to get better insights into their business. Whether it is consuming log files, sensor metrics, and other unstructured data, most enterprises manage and deliver data to the data lake and leverage various applications like ETL tools, search engines, and databases for analysis. This whole architecture made a lot of sense when there was a consistent and predictable flow of data to process. In reality, most companies are trying to collect massive and unpredictable data flows, and often the processing requirements can change and get complicated pretty quickly. The ability to wrangle and sift through petabytes of data can strain any analytics performance and impede the ability to get timely actionable insights.
Rethink the data need
When I interview customers from the line of business leaders to individual developers, they explain their biggest challenge is finding the right information at the right time is like looking for a needle in a haystack. The business is so unprepared with information overflow that missing an important event or insight has become the business norm. The ability to have the right data can determine an enterprise’s ability to succeed or fail. Meeting this challenge could mean making buying decisions at the best price, adjusting business processes to save millions of operation costs, or helping the cybersecurity team detect cyber threats faster and minimize the risk of exposing confidential data.
What should IT leaders consider when planning their data needs? Should the enterprise continue the status quo with the old data lake methodology? Or rethink the data problem by collecting only the data that matters?
How a global oil and gas company changed its data strategy
A global oil and gas company collects, transforms, and distributes over hundreds terabytes of desktop, server, and application log data to their SIEM per day. As the company evolves into a hybrid and multi-cloud strategy, they need to start collecting applications, servers, and network logs from the cloud. As the data strategy continues to shift, the team has ran into the following problems:
- The cybersecurity team has too much data to sift through and struggles to make sense of their data.
- They can’t do ad hoc analysis once the data is in the SIEM. It’s too costly to move the data to another application.
- The application license and infrastructure costs are rising faster than the ability to detect cyber events effectively.
Start thinking about processing data at the edge
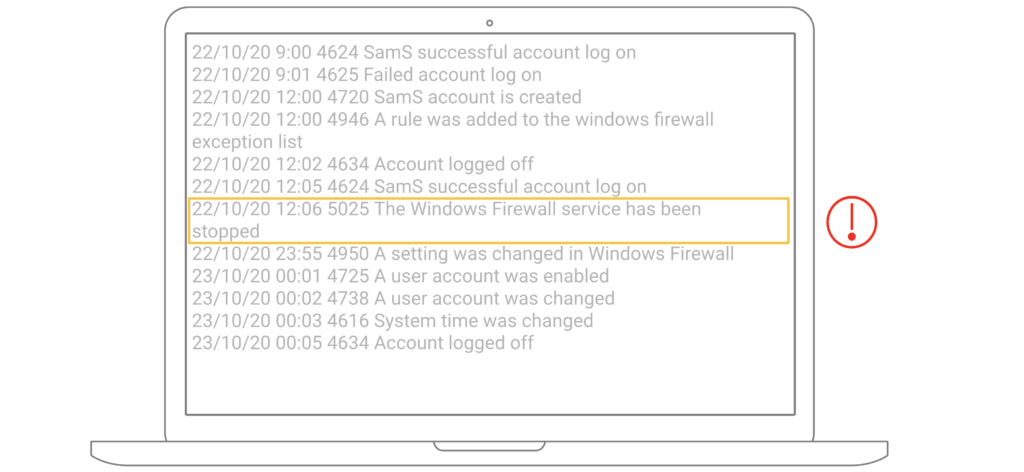
Each device can record user activities, whether this is logging onto the devices or changing the password. Most of these events are common user activities, but the cybersecurity team only cares about the unusual events that matter (as highlighted in the image). Rather than collecting every single event and analyzing later, it would make sense to identify the important data as it is being collected. What product can help collect events only?
Let’s transform the first mile of the data pipeline
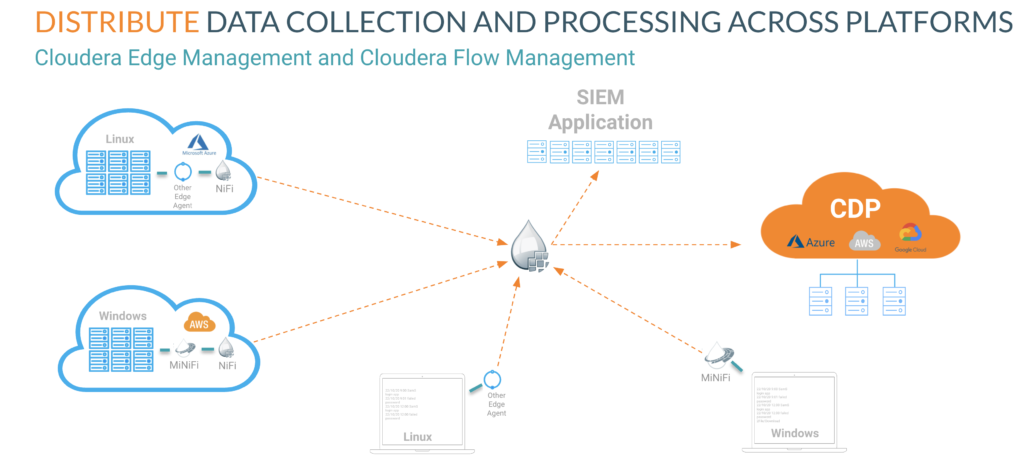
Cloudera Edge Management, which includes a lightweight edge agent, powered by Apache MiNiFi, was deployed on every desktop, server, network, and application from on-premises to the public cloud for collecting log data. It delivers the data to Cloudera Flow Management, powered by Apache NiFi, to parse, transform and distribute the top priority data that matter to the SIEM and provides the remaining data to the public cloud for further analysis. The ability to manage how the data flows and transforms during the first mile of the data pipeline and control the data distribution can accelerate the performance of all analytic applications.
What is the impact on the business?
The enterprise realizes solving the first mile of the data pipeline can accelerate their existing analytics, and it became the new approach to modernizing all their analytics. In this scenario, Cloudera Edge and Flow Management were implemented to parse and transform XML log data to JSON and distribute the results to the SIEM. By controlling the processing of the data flows, the cybersecurity team can now run Splunk searches 55% faster and get faster insight into potential fraud.

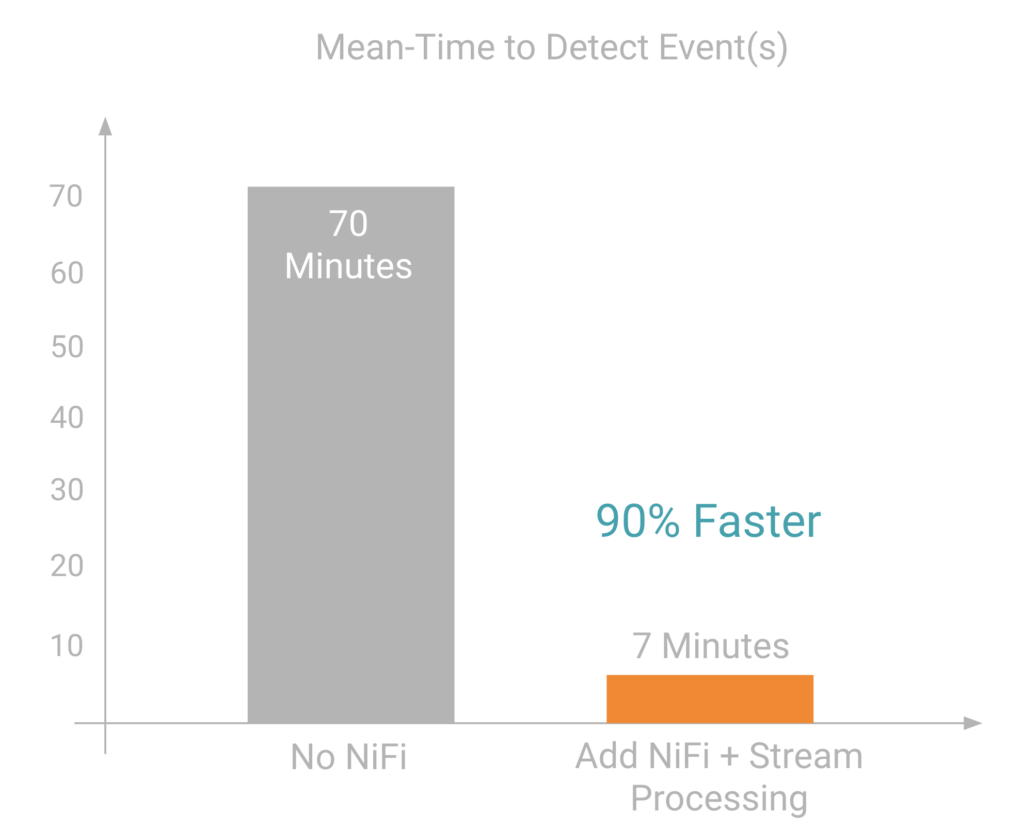
Here is another example: the scoring system takes 70 minutes to identify a perpetrator getting access to the computer system and the time to detect the intrusion. By adding Cloudera Flow Management with a stream processing engine, the “mean time to detect events” accelerated to 7 minutes, a 90% faster response to an intrusion.
By modernizing the data flow, the enterprise got better insights into the business. They also reduced terabytes of data ingestion, which significantly brought down the infrastructure and licensing costs by 30%.
Make a move to Cloudera Edge and Flow Management
You may wonder whether modernizing your first mile of the data pipeline is the solution to building the foundation for next-generation analytics. The truth is the efficiency of Cloudera Edge and Flow Management will give you the freedom to scale and modernize your analytics and optimize your infrastructure cost. Don’t just let your legacy solution keep you from powering your business to new levels. Learn by modernizing your data flow, and you’ll get faster insight that speeds up ad-hoc decisions, reduces risk, and drives innovation across your line of business.
Learn more about Cloudera Edge and Flow Management
Editor's Choice

