

Co-author: Mike Godwin, Head of Marketing, Rill Data
Cloudera has partnered with Rill Data, an expert in metrics at any scale, as Cloudera’s preferred ISV partner to provide technical expertise and support services for Apache Druid customers. We want Cloudera customers that rely on Apache Druid to know that their clusters are secure and supported by the Cloudera partner ecosystem.
As creators and experts in Apache Druid, Rill understands the data store’s importance as the engine for real-time, highly interactive analytics. Rill’s services and platform ensure the performance, reliability, and security required to meet the most demanding SLAs.
Cloudera users can securely connect Rill to a source of event stream data, such as Cloudera DataFlow, model data into Rill’s cloud-based Druid service, and share live operational dashboards within minutes via Rill’s interactive metrics dashboard or any connected BI solution.
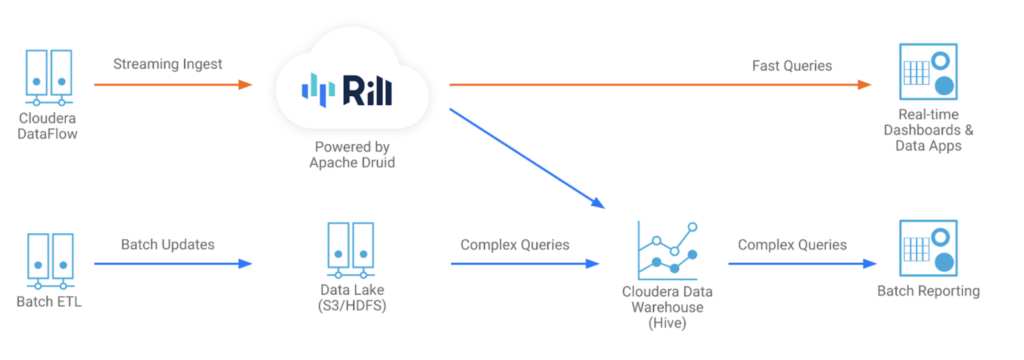
Figure 1: Rill and Cloudera Architecture
Deploying metrics shouldn’t be so hard
Integrating with Cloudera DataFlow for streaming ingest and Cloudera Data Warehouse for querying, Rill’s solution solves three critical challenges in the analytics stack:
- ETL Pain: Modeling event streams into the flat formats required by operational databases is inefficient and lacks observability. Rill solves this with pipeline services and Rill Developer, a free SQL-based data modeler.
- Database Pain: Apache Druid is powerful but complex to configure, operate, and scale. Rill relieves that burden with a managed service offering or Druid monitoring for existing clusters.
- BI Tool Pain: BI tools, such as Tableau and Looker, are challenging to properly connect to operational databases. Rill provides pre-built connectors along with a front-end purpose-built for analyzing data in Druid.
Cloudera DataFlow to Rill is a straight path
Druid’s native support for ingesting data from Apache Kafka allows it to stream data from Cloudera DataFlow to Rill’s fully managed Druid service. Data is made queryable in real time.
The Druid native Kafka indexing service features:
- Pull-based ingestion
- Exactly once support
- Autoscaling to handle spikes in data volume

Figure 2: Straight Path from Cloudera DataFlow to Rill
The best of both worlds: Apache Hive and Druid
Cloudera Data Warehouse and Rill Data—built on Apache Hive and Druid, respectively—can be connected using the Hive-Druid Integration. Combining the powerful Hive data warehouse with the fast operational analytics from Druid lets Cloudera customers accelerate their existing Hive workloads and achieve better performance. An independent benchmark shows that combining Druid and Hive can result in up to 190x faster queries without sacrificing the power of Hive for complex analytical queries that involve joins. This is especially useful when the data in Druid needs to be joined with the data residing elsewhere in the warehouse.
The table below summarizes Hive and Druid key features and strengths and suggests how combining the feature sets can provide the best of both worlds for data analytics.
| Component | Strengths | Features |
| Apache Hive (Cloudera Data Warehouse) |
Large-scale high throughput analytics |
|
| Apache Druid (Rill Cloud Service) |
Operational analytics queries
Drill-down with large number of arbitrary dimensions |
|
Intuitive metrics, simple design
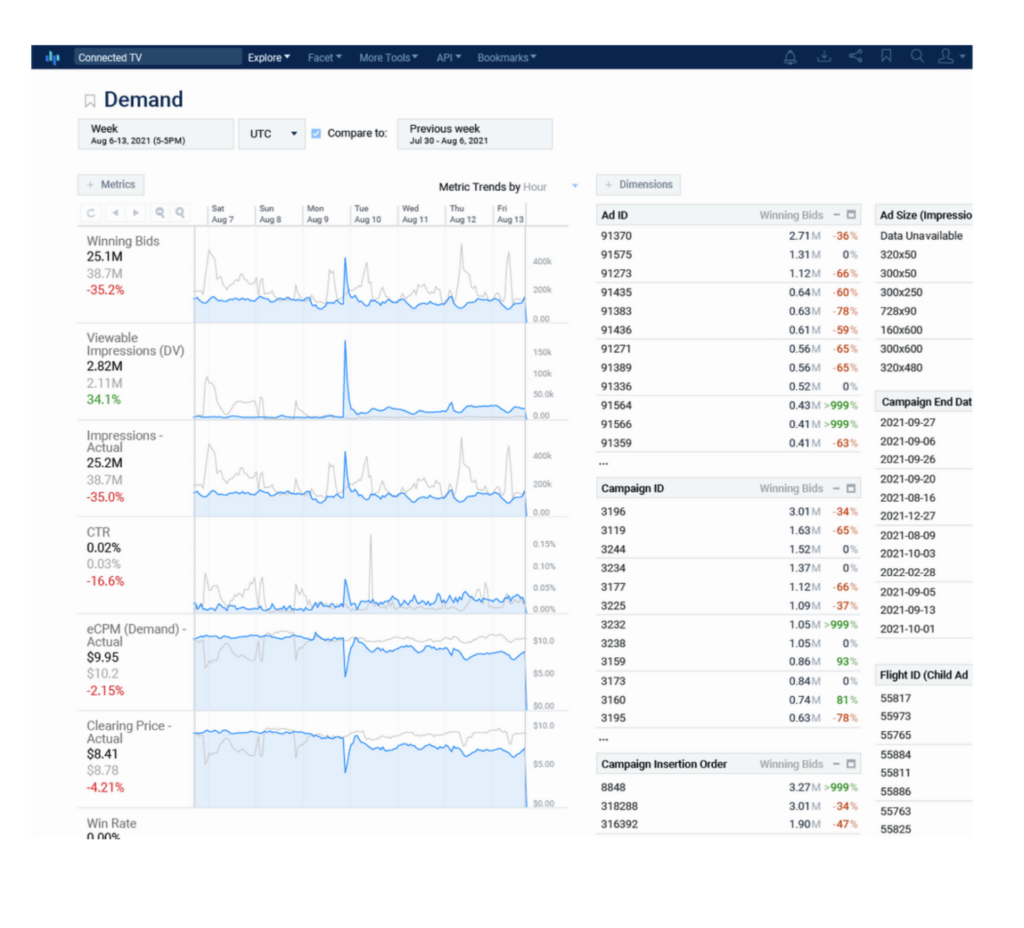
Business stakeholders and metrics consumers should spend more time exploring key metrics than building and designing dashboards. Rill’s metrics dashboards remove friction from the analytics experience with an opinionated design that requires little training. More specifically:
- All in one: Each metric and dimension is available to users at high granularity as Druid handles high cardinality uniquely well. That means no more “dashboard rot” trying to find the right view of the data for your use case.
- Simplified interface: Rill’s metrics dashboard focuses on metrics trends (timelines) and dimensional insights (top-N). By eliminating highly configurable widgets, Rill dashboards facilitate discovery and interaction—one customer often drives 10x the query volume from Rill vs. traditional BI dashboards.
- Built-in workflow: In addition to querying capabilities, Rill includes scheduled exports and alerts to stay on top of regular reporting and provide opportunities to dive deeper.
Triton Digital, for example, uses Rill to deploy self-serve reporting for hundreds of digital media publishers with little or no training. One product owner shares:
“Rill requires little to no training and is utilized by many of our audio SSP clients. The ability to provide a wide range of metrics and dimensions with an intuitive interface is appreciated, as it allows them to navigate their data with speed and ease.”
Continuity and performance for Apache Druid
Cloudera recognizes that, once running, Druid is often quite stable, but resolving issues can be challenging. To provide continuity for Cloudera Data Platform (CDP) customers using Druid, Rill offers a variety of services for companies who need consultative support or the security and features of newer versions of Druid.
Cluster Monitoring and Health Check: Starting with a comprehensive review at an initial kick off and continuing on a quarterly basis, Rill conducts a review of cluster health focused on performance tunings, version upgrades (including security fixes), and data model optimizations. The Rill team includes former Clouderans who provide insight into both Druid maintenance and consistency with your existing CDP deployment. Rill’s support offering also includes a monitoring service—Cloudera customers can emit their cluster metrics for monitoring with a custom built dashboard. For support services, contact Rill’s Advanced Technology Group.
Druid-as-a-Service: For those looking to migrate an existing Druid deployment to a fully managed service, Rill’s team of Apache Druid experts can help. Rill provides end-to-end support on your existing cluster, a migration plan for moving pipelines and clusters to the cloud, and a fully managed production Druid service. This reduces the total cost of ownership and frees internal resources for higher priority tasks than Druid maintenance and optimization.
Welcoming Rill Data to the Cloudera partner ecosystem
Cloudera is pleased to introduce this preferred partnership with Rill Data and to reassure Cloudera customers that rely on Apache Druid that their clusters are secure and supported by the Cloudera partner ecosystem. Together Cloudera and Rill Data are dedicated to building and maintaining the data infrastructure that best supports our customers with cost-performant queries, resilience, and distributed real-time metrics.
Learn more about Rill Data on their website, or take the Cloudera Data Platform for a test drive today.
Editor's Choice

