





Many enterprises have heterogeneous data platforms and technology stacks across different business units or data domains. For decades, they have been struggling with scale, speed, and correctness required to derive timely, meaningful, and actionable insights from vast and diverse big data environments. Despite various architectural patterns and paradigms, they still end up with perpetual “data puddles” and silos in many non-interoperable data formats. Constant data duplication, complex Extract, Transform & Load (ETL) pipelines, and sprawling infrastructure leads to prohibitively expensive solutions, adversely impacting the Time to Value, Time to Market, overall Total Cost of Ownership (TCO), and Return on Investment (ROI) for the business.
Cloudera’s open data lakehouse, powered by Apache Iceberg, solves the real-world big data challenges mentioned above by providing a unified, curated, shareable, and interoperable data lake that is accessible by a wide array of Iceberg-compatible compute engines and tools.
The Apache Iceberg REST Catalog takes this accessibility to the next level simplifying Iceberg table data sharing and consumption between heterogeneous data producers and consumers via an open standard RESTful API specification.
REST Catalog Value Proposition
- It provides open, metastore-agnostic APIs for Iceberg metadata operations, dramatically simplifying the Iceberg client and metastore/engine integration.
- It abstracts the backend metastore implementation details from the Iceberg clients.
- It provides real time metadata access by directly integrating with the Iceberg-compatible metastore.
- Apache Iceberg, together with the REST Catalog, dramatically simplifies the enterprise data architecture, reducing the Time to Value, Time to Market, and overall TCO, and driving greater ROI.
The Cloudera open data lakehouse, powered by Apache Iceberg and the REST Catalog, now provides the ability to share data with non-Cloudera engines in a secure manner.
With Cloudera’s open data lakehouse, you can improve data practitioner productivity and launch new AI and data applications much faster with the following key features:
- Multi-engine interoperability and compatibility with Apache Iceberg, including Cloudera DataFlow (NiFi), Cloudera Stream Analytics (Flink, SQL Stream Builder), Cloudera Data Engineering (Spark), Cloudera Data Warehouse (Impala, Hive), and Cloudera AI (formerly Cloudera Machine Learning).
- Time Travel: Reproduce a query as of a given time or snapshot ID, which can be used for historical audits, validating ML models, and rollback of erroneous operations, as examples.
- Table Rollback: Enable users to quickly correct problems by rolling back tables to a good state.
- Rich set of SQL (query, DDL, DML) commands: Create or manipulate database objects, run queries, load and modify data, perform time travel operations, and convert Hive external tables to Iceberg tables using SQL commands.
- In-place table (schema, partition) evolution: Evolve Iceberg table schema and partition layout on the fly without requiring data rewriting, migration, or application changes.
- Cloudera Shared Data Experience (SDX) Integration: Provide unified security, governance, and metadata management, as well as data lineage and auditing on all your data.
- Iceberg Replication: Out-of-the-box disaster recovery and table backup capability.
- Easy portability of workloads between public cloud and private cloud without any code refactoring.
Solution Overview
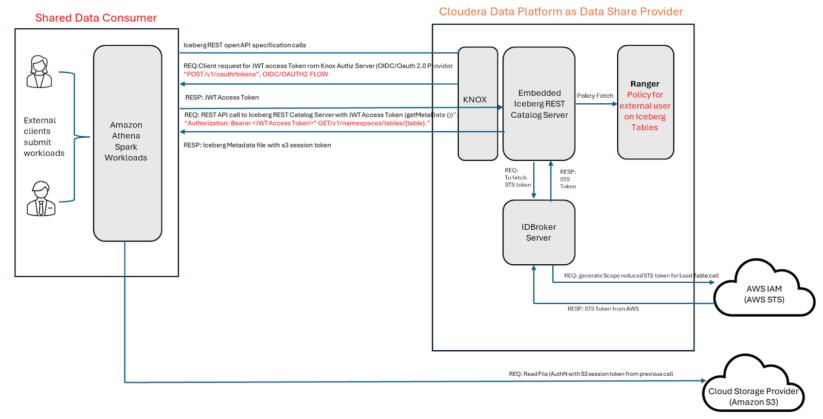
Data sharing is the capability to share data managed in Cloudera, specifically Iceberg tables, with external users (clients) who are outside of the Cloudera environment. You can share Iceberg table data with your clients who can then access the data using third party engines like Amazon Athena, Trino, Databricks, or Snowflake that support Iceberg REST catalog.
The solution covered by this blog describes how Cloudera shares data with an Amazon Athena notebook. Cloudera uses a Hive Metastore (HMS) REST Catalog service implemented based on the Iceberg REST Catalog API specification. This service can be made available to your clients by using the OAuth authentication mechanism defined by the
KNOX token management system and using Apache Ranger policies for defining the data shares for the clients. Amazon Athena will use the Iceberg REST Catalog Open API to execute queries against the data stored in Cloudera Iceberg tables.
Pre-requisites
The following components in Cloudera on cloud should be installed and configured:
- Cloudera Data Platform Public Cloud version 7.2.18.300 or later
- One of the following to create the required Iceberg Tables
- Data Warehouse Virtual Warehouse running Hive (with HUE access)
- Data Hub running Hive and HUE
The following AWS prerequisites:
- An AWS Account & an IAM role with permissions to create Athena Notebooks
In this example, you will see how to use Amazon Athena to access data that is being created and updated in Iceberg tables using Cloudera.
Please reference user documentation for installation and configuration of Cloudera Public Cloud.
Follow the steps below to setup Cloudera:
1. Create Database and Tables:
Open HUE and execute the following to create a database and tables.
CREATE DATABASE IF NOT EXISTS airlines_data; DROP TABLE IF EXISTS airlines_data.carriers; CREATE TABLE airlines_data.carriers ( carrier_code STRING, carrier_description STRING) STORED BY ICEBERG TBLPROPERTIES ('format-version'='2'); DROP TABLE IF EXISTS airlines_data.airports; CREATE TABLE airlines_data.airports ( airport_id INT, airport_name STRING, city STRING, country STRING, iata STRING) STORED BY ICEBERG TBLPROPERTIES ('format-version'='2');
2. Load data into Tables:
In HUE execute the following to load data into each Iceberg table.
INSERT INTO airlines_data.carriers (carrier_code, carrier_description) VALUES ("UA", "United Air Lines Inc."), ("AA", "American Airlines Inc.") ; INSERT INTO airlines_data.airports (airport_id, airport_name, city, country, iata) VALUES (1, 'Hartsfield-Jackson Atlanta International Airport', 'Atlanta', 'USA', 'ATL'), (2, 'Los Angeles International Airport', 'Los Angeles', 'USA', 'LAX'), (3, 'Heathrow Airport', 'London', 'UK', 'LHR'), (4, 'Tokyo Haneda Airport', 'Tokyo', 'Japan', 'HND'), (5, 'Shanghai Pudong International Airport', 'Shanghai', 'China', 'PVG') ;
3. Query Carriers Iceberg table:
In HUE execute the following query. You will see the 2 carrier records in the table.
SELECT * FROM airlines_data.carriers;
4. Setup REST Catalog
5. Setup Ranger Policy to allow “rest-demo” access for sharing:
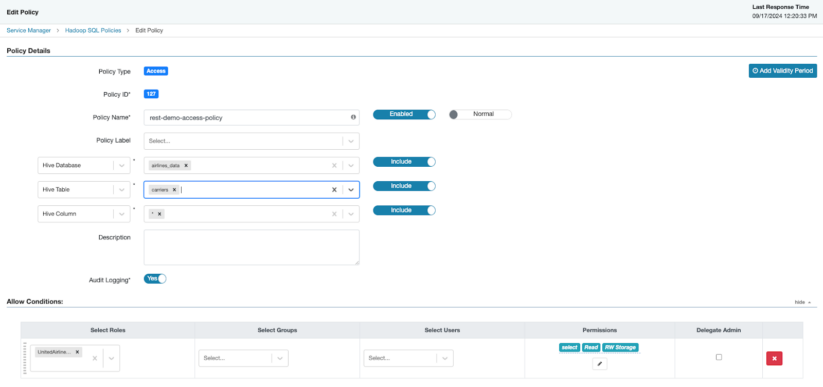
Create a policy that will allow the “rest-demo” role to have read access to the Carriers table, but will have no access to read the Airports table.
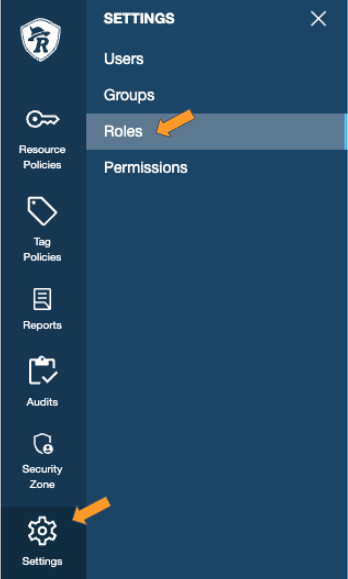
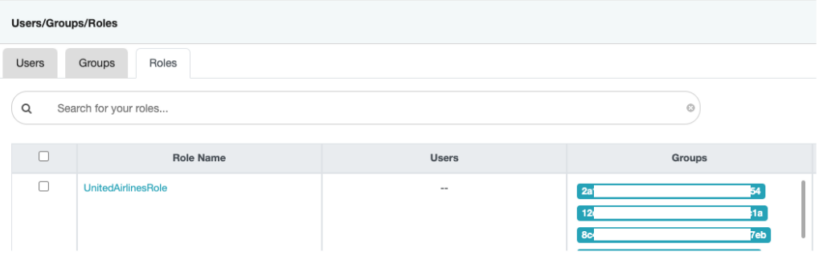
In Ranger go to Settings > Roles to validate that your Role is available and has been assigned group(s).
In this case I’m using a role named – “UnitedAirlinesRole” that I can use to share data.
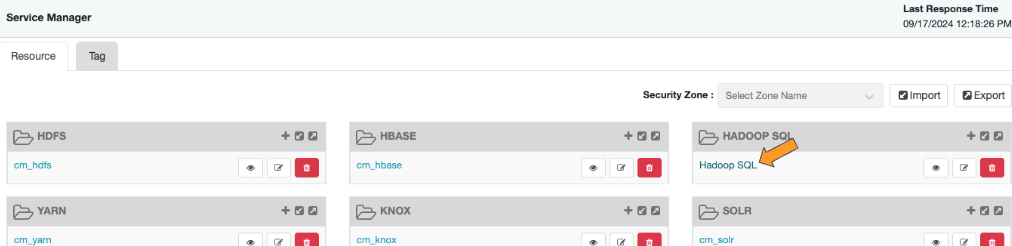
Add a Policy in Ranger > Hadoop SQL.
Create new Policy with the following settings, be sure to save your policy
- Policy Name: rest-demo-access-policy
- Hive Database: airlines_data
- Hive Table: carriers
- Hive Column: *
- In Allow Conditions
- Select your role under “Select Roles”
- Permissions: select
Follow the steps below to create an Amazon Athena notebook configured to use the Cloudera Iceberg REST Catalog:
6. Create an Amazon Athena notebook with the “Spark_primary” Workgroup
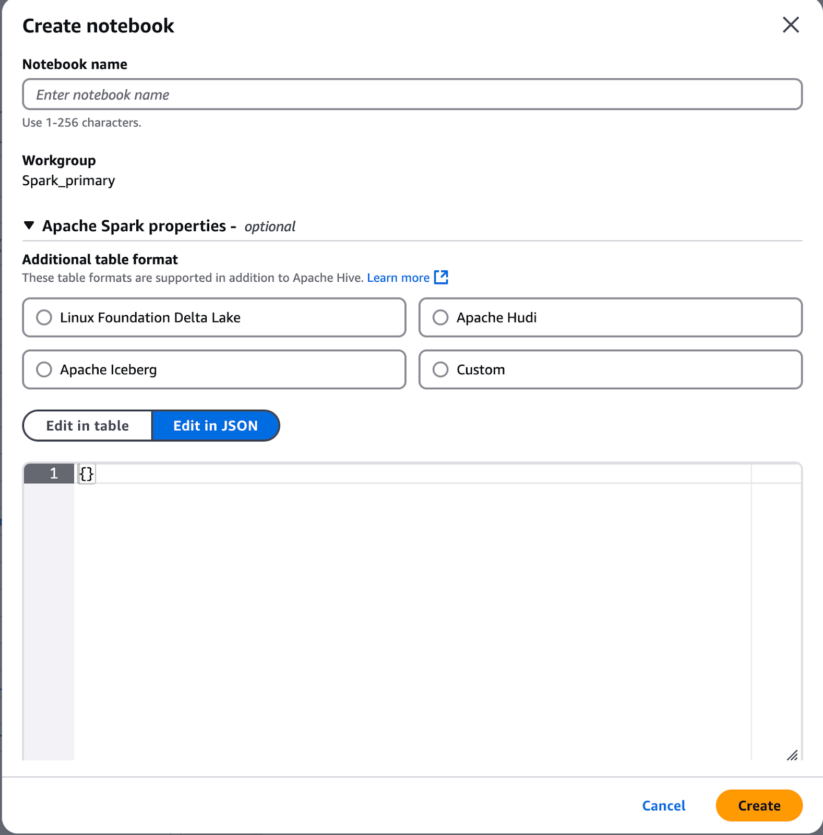
a. Provide a name for your notebook
b. Additional Apache Spark properties – this will enable use of the Cloudera Iceberg REST Catalog. Select the “Edit in JSON” button. Copy the following and replace <cloudera-knox-gateway-node>, <cloudera-env-name>, <client-id>, and <client-secret> with the appropriate values. See REST Catalog Setup blog to determine what values to use for replacement.
{ "spark.sql.catalog.demo": "org.apache.iceberg.spark.SparkCatalog", "spark.sql.catalog.demo.default-namespace": "airlines", "spark.sql.catalog.demo.type": "rest", "spark.sql.catalog.demo.uri": "https://<cloudera-knox-gateway-node>/<cloudera-env-name>/cdp-share-access/hms-api/icecli", "spark.sql.catalog.demo.credential": "<client-id>:<client-secret>", "spark.sql.defaultCatalog": "demo", "spark.sql.extensions": "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions" }
c. Click on the “Create” button, to create a new notebook
7. Spark-sql Notebook – execute commands via the REST Catalog
Run the following commands 1 at a time to see what is available from the Cloudera REST Catalog. You will be able to:
- See the list of available databases
spark.sql(show databases).show();
- Switch to the airlines_data database
spark.sql(use airlines_data);
- See the available tables (should not see the Airports table in the returned list)
spark.sql(show tables).show();
- Query the Carriers table to see the 2 Carriers currently in this table
spark.sql(SELECT * FROM airlines_data.carriers).show()
Follow the steps below to make changes to the Cloudera Iceberg table & query the table using Amazon Athena:
8. Cloudera – Insert a new record into the Carriers table:
In HUE execute the following to add a row to the Carriers table.
INSERT INTO airlines_data.carriers VALUES("DL", "Delta Air Lines Inc.");
9. Cloudera – Query Carriers Iceberg table:
In HUE and execute the following to add a row to the Carriers table.
SELECT * FROM airlines_data.carriers;
10. Amazon Athena Notebook – query subset of Airlines (carriers) table to see changes:
Execute the following query – you should see 3 rows returned. This shows that the REST Catalog will automatically handle any metadata pointer changes, guaranteeing that you will get the most recent data.
spark.sql(SELECT * FROM airlines_data.carriers).show()
11. Amazon Athena Notebook – try to query Airports table to test security policy is in place:
Execute the following query. This query should fail, as expected, and will not return any data from the Airports table. The reason for this is that the Ranger Policy is being enforced and denies access to this table.
spark.sql(SELECT * FROM airlines_data.airports).show()
Conclusion
In this post, we explored how to set up a data share between Cloudera and Amazon Athena. We used Amazon Athena to connect via the Iceberg REST Catalog to query data created and maintained in Cloudera.
Key features of the Cloudera open data lakehouse include:
- Multi-engine compatibility with various Cloudera products and other Iceberg REST compatible tools.
- Time Travel and Table Rollback for data recovery and historical analysis.
- Comprehensive SQL support and in-place schema evolution.
- Integration with Cloudera SDX for unified security and governance.
- Iceberg replication for disaster recovery.
Amazon Athena is a serverless, interactive analytics service that provides a simplified and flexible way to analyze petabytes of data where it lives.. Amazon Athena also makes it easy to interactively run data analytics using Apache Spark without having to plan for, configure, or manage resources. When you run Apache Spark applications on Athena, you submit Spark code for processing and receive the results directly. Use the simplified notebook experience in Amazon Athena console to develop Apache Spark applications using Python or Use Athena notebook APIs. The Iceberg REST Catalog integration with Amazon Athena allows organizations to leverage the scalability and processing power of EMR Spark for large-scale data processing, analytics, and machine learning workloads on large datasets stored in Cloudera Iceberg tables.
For enterprises facing challenges with their diverse data platforms, who might be struggling with issues related to scale, speed, and data correctness, this solution can provide significant value. This solution can reduce data duplication issues, simplify complex ETL pipelines, and reduce costs, while improving business outcomes.
To learn more about Cloudera and how to get started, refer to Getting Started. Check out Cloudera’s open data lakehouse to get more information about the capabilities available or visit Cloudera.com for details on everything Cloudera has to offer. Refer to Getting Started with Amazon Athena
Editor's Choice

