

It’s official – Cloudera and Hortonworks have merged, and today I’m excited to announce the availability of Cloudera Data Science Workbench (CDSW) for Hortonworks Data Platform (HDP). Trusted by large data science teams across hundreds of enterprises —
Western Union and IQVIA to name just a couple — CDSW is now also ready to help Hortonworks customers accelerate the delivery of new data products through secure, collaborative data science at scale.
Data scientists require on-demand access to data, powerful processing infrastructure, and multiple tools and libraries for development and experimentation. Meanwhile, IT has a difficult time keeping up with these changing needs while ensuring operational efficiency and compliance. Sound familiar? CDSW was designed precisely to resolve this common conflict, offering data science teams a modern, collaborative environment for rapid development using open tools and libraries, plus on-demand access to data and compute. IT organizations can deliver all of this with a scalable, secure, governed, self-service platform which avoids costly data and tool stack silos.
What is CDSW?
Cloudera Data Science Workbench is a web-based application that allows data scientists to use their favorite open source libraries and languages — including R, Python, and Scala — directly in secure environments, accelerating analytics projects from research to production.
Built using Docker containers, Cloudera Data Science Workbench offers data science teams per-project isolation and reproducibility, in addition to easier collaboration. By leveraging all the existing platform’s support for Apache Ranger and Apache Atlas, IT teams can take advantage of their previous investment in security, audit, and governance policies along with seamless Kerberos and LDAP integration. Add it to an existing HDP cluster, and it just works.
With Cloudera Data Science Workbench, data scientists can:
- Use R, Python, or Scala along with the scale-out processing capabilities of Apache Spark 2.X on HDP clusters from a web browser, with no desktop footprint.
- Utilize GPUs effectively for workload specific needs.
- Install any library or framework (e.g. Tensorflow, PyTorch, or XGBoost) within isolated project environments.
- Directly access data stored anywhere, including secure HDP clusters and cloud object storage.
- Share insights and visualizations from reproducible, collaborative research.
- Build and execute model training runs in isolation and deploy models directly from source as REST APIs, tracking performance and any user-specified artifacts to easily rollback to old versions.
- Run experiments with historical reference for hyperparameter tuning, feature engineering, grid searches, A/B testing and more.
- Automate and monitor data pipelines and periodic retraining using built-in job scheduling.
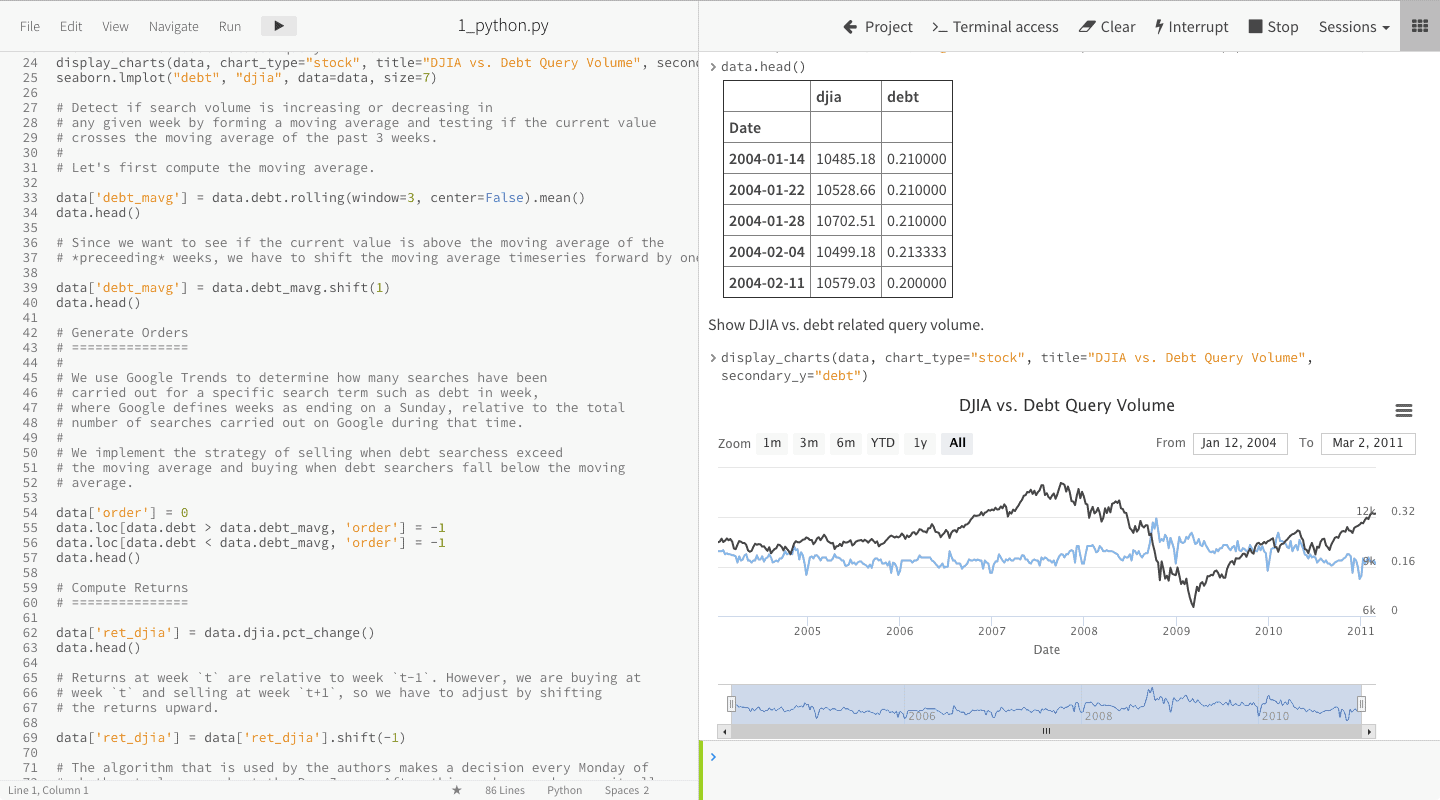
Meanwhile, IT professionals can:
- Give their data science team the freedom to work how they want, when they want.
- Maintain compliance with out-of-the-box support for full platform security, especially Kerberos.
- Provide a consistent experience wherever data is managed — on-premises, in the cloud or both.
Beyond Notebooks — Secure and Scalable for Enterprise by Design
Both at Hortonworks and today at our post-merger Cloudera, we believe in and advocate strongly for the value, power and practical necessity of leveraging open source software for data-driven innovation and differentiation. Data scientists often use Jupyter or Zeppelin notebooks as convenient, open source, free and extensible tools supporting many open source languages and libraries for development, visualization and sharing.
However as organizations look to scale machine learning capabilities, moving from individual users to teams, and from tens to hundreds or even thousands of models in production, they encounter the common limitations of notebooks. For multi-user or regulated environments, security, governance, reproducibility, and resource isolation are critical. To move beyond laptop experimentation to impacting the business, data teams also need seamless sharing and native integration with the production data platform.
For HDP customers who require secure, self-service support for teams of data scientists, CDSW offers a uniquely compelling solution with features for collaboration, multi-user project isolation and integration with customers’ existing version control and source repositories like Git. Enterprise data science teams also appreciate CDSW’s integration with our platform’s existing capabilities for dataset lineage, data dictionaries, and the ability to tag and comment on data, all of which make it easier for data scientists to find and trust the right data when delivering insights. Beyond development, these days it’s not enough to simply build models; data scientists need to easily deploy them to business users without leaning on DevOps for re-coding. CDSW makes it easy to deploy models directly from development as batch scoring jobs or REST APIs, completing and accelerating the data scientist’s end-to-end workflow, from sourcing data to building experiments and models to deploying trusted models to production.
Built from the ground up for enterprise, CDSW has been chosen by Cloudera’s many enterprise customers to accelerate modern, open data science for business at scale. We’re looking forward to providing the same benefits to HDP customers with CDSW on HDP.
Please join us for a live webinar on February 12th at 10 am PT for a demonstration of a machine learning workflow using CDSW on HDP. Register Now
 Saumitra Buragohain is a Vice President, Product Management for Hortonworks Data Platform (HDP). During his tenure, Saumitra led the launch of HDP 3.0.0 and first DataPlane application Data Lifecycle Manager from concept to business case to release. Prior to joining Hortonworks, Saumitra led the product direction in two startups (one was acquired by Western Digital) and prior to that, Saumitra ran the virtualization strategy in a $3B EMC Business Unit and ran a $600M P&L in Brocade. Saumitra has an MBA from Santa Clara University and an MSEE from University of Southern California.
Saumitra Buragohain is a Vice President, Product Management for Hortonworks Data Platform (HDP). During his tenure, Saumitra led the launch of HDP 3.0.0 and first DataPlane application Data Lifecycle Manager from concept to business case to release. Prior to joining Hortonworks, Saumitra led the product direction in two startups (one was acquired by Western Digital) and prior to that, Saumitra ran the virtualization strategy in a $3B EMC Business Unit and ran a $600M P&L in Brocade. Saumitra has an MBA from Santa Clara University and an MSEE from University of Southern California.
Editor's Choice

